Home
- Introduction
- Trigram Model
- Decision Tree
- Walk through the paper
- Set construction implications
- Implementing the algorithm
- Additional considerations
- Results
- Future Work
- References
trsl, pronounced tre-sell, is an implementation of the paper Tree based statistical language model. This is referred to as the paper through this wiki.
A Tree-Based Statistical Language Model for Natural Language Speech Recognition (1989) by L R Bahl, P F Brown, P V de Souza, R L Mercer
This implementation is based on the Python programming language.
The original paper talks about a couple of flaws in the trigram model for predicting the next word in a speech recognition task. The trigram model assumes that the probability distribution of the next word mostly depends on the previous two words.
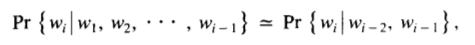
Trigram equation. Source: Tree based statistical language model paper
This trigram model assumption is flawed. As we can see from the image below. We lose a lot of useful information
about the context by limiting the memory to only a very few previous words.
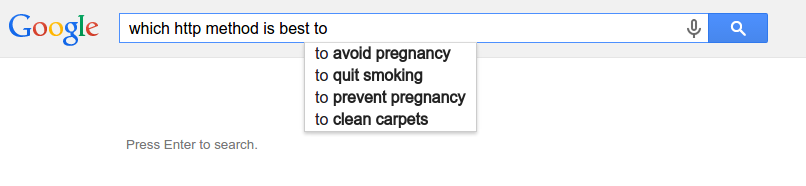
Google Search Prediction using a short memory model
Also, sentences that are functionally equivalent can fall into different equivalence classes with this approach. Trying to increase the memory can reduce the number of samples in each equivalence class because a longer sequence of words may not occur very frequently. Thus the model will start mirroring the training text.
For the reasons stated above, the paper suggests a language model that is based on decision trees. Decision trees are a way of minimizing the entropy (a measure of the uncertainty in deciding on an event ) through asking a series of questions on some data that is available. An intuitive explanation about entropy can be found here.
A Decision tree where the answers are always binary is shown here.
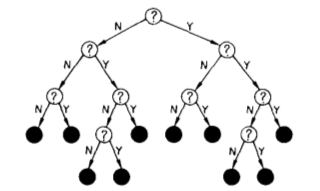
Binary Decision Tree. Source: Tree based statistical language model paper
The central idea of the algorithm is to ask questions of the form 'Is the previous word a verb?' or 'Is the 5th previous word a noun?' at the internal nodes of the tree and arrive at a probability distribution on the vocabulary for the next word that is going to be uttered. More formally, questions of the form Xi ∈ Si? Where Xi (i = 1,2,3,4...,m) called the predictor variables indicate the random discrete variable being questioned and m is the size of the memory (number of previous words) with which we decide to build our model and Si denotes a set of words. The paper reasons that this model will be at least as good as the trigram model, because the trigram model can be also be represented in the form of a tree with questions like 'Is the previous word wi?' or 'Is the second to last word wj?'
-
Step 1: Average Entropy: The Algorithm seeks to minimize the probabilistic average entropy across all the leaf nodes
liin the decision tree which can be computed as in the equation below.Hi(Y)is the entropy of the distribution associated with leafliandPr{li}is the probability of visiting leafli.
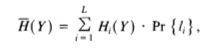
-
Step 2: Leaf Entropy: The entropy at each of the leaf nodes can be computed as below.
Vis the size of the vocabulary, andPr { wj | li }is the probability that wordwjwill be the next word spoken given that the immediate word history leads to leafli.
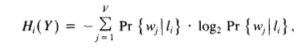
-
Step 3: Tree construction: The tree construction algorithm, as in the paper, is as follows:
- Let
cbe the current node of the tree. Initially,cis the root. - For each predictor variable
Xi , ( i = 1, 2, ... m ), find the setSiwhich minimizes the average conditional entropy at nodec
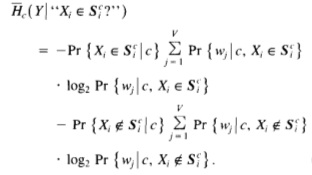
-
Step 4: Determine which of the
mquestions derived in Equation 3 leads to the lowest entropy. Let this be questionk
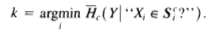
-
Step 5 & 6: The reduction at node
cdue to questionkis listed below. If this reduction is "significant" store questionk, create two descendant nodes,c1andc2, corresponding to the conditionsXi ∈ SiandXi ∉ Siand repeat Step 2 to 4 for each of the new nodes separately.
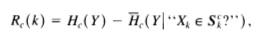
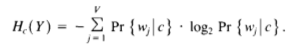
- Let
-
Set construction: The original paper suggests a simple greedy approach to constructing the sets to be used for asking questions in Equation 2 of the algorithm above -
Si- Let
Sbe empty. - Insert into
Sthex ∈ Xwhich leads to the greatest reduction in the average conditional entropy. If nox∈ Xleads to a reduction, make no insertion. - Delete from
Sany memberx, if doing so leads to a reduction in the average conditional entropy. - If any insertions or deletions were made to
S, return to Step ii.
- Let
The computation of average conditional entropy for a question is in itself a computationally intensive task. Therefore, computing this every time a new word is inserted doesn't seem feasible for large vocabularies. Later, the paper suggests inserting and deleting hand made groups of words instead of words in the set construction algorithm.
The sets were predefined to represent grammatical classes such as days of the week, months, nouns, verbs, etc. The classes were of differing coarseness and overlapped; many words belonged to several classes. For example, “July” belonged to the class of months, the class of nouns, as well as its own class, the class of “July,” which contained only that one word. Adding groups of words simultaneously allows set construction to proceed more rapidly.
But constructing sets this way still seemed like a computationally hard task for a large vocabulary and also building word groups by hand would require a lot of man hours and linguistic expertise which our team lacked.
We considered Word Net a curated web of words which can be used to retrieve Syn sets (Synonym sets) of words. But Wordnet ignores functional categories such as prepositions and also, we thought that this would make this process of getting groups of words language dependent, as Wordnet isn't available for many languages.
So we had a need for constructing word groups in a language agnostic way, computationally. We found a solution in Word2Vec which gives us word vectors with interesting properties which we experimented with. We finally arrived at a process to find disjoint (non-overlapping) groups of semantically similar words from a given vocabulary. Our experiments and the process we decided to use listed in the following section.
- Set Construction - Given the vocabulary
Vthat we obtain from the training text, we groupVintonsemantically similar, non-overlapping sets of words. Let us call this function asbuild_sets. Therefore,build_sets(V) = {S1, S2, S3, ... Sn}-- (7) - Let our memory (number of previous words we consider) be
m. We eliminate all punctuation from the training text except the period, which we considered as a word. We also eliminate any sentences that have less thanm+1words. Let us call this processed training text asT. We obtain sample sequences of words by using a sliding window of lengthm+1onT, stopping at sentence boundaries(period) and restarting at the start of the next sentence. Let us call the set of sample sequences that we obtain here asword_seqs.- Let's consider a value for m:
m = 2 - Training text:
w1 w2 w3 w4. w5 w6 w7 - Sample sequences / sentences
- Sample Sequence 1 =
w1 w2 w3 - Sample Sequence 2 =
w2 w3 w4 - Sample Sequence 3 =
w3 w4 - Sample Sequence 4 =
w5 w6 w7 - Sample Sequence 5 =
w6 w7
- Sample Sequence 1 =
- The
ith word from each of the sample sequences wherei = 1, 2 ,3 ... mis represented by a variableXi. These are the predictor variables mentioned in step 2 of the algorithm original algorithm mentioned in the paper. Let them+1th word in the sample sequences be represented by another variable calledTarget.
- Let's consider a value for m:
- We move away from the original algorithm a little after this point. Using the sets from (7), we replace each word in
word_seqsby the index of the set which contains the word. Let us call the output of this process asset_seqs, since the identity of words is replaced by the identity of the set they belong to. Because of this change, the Entropy at each leaf nodeljis now modified from (2) to be - We store
set_seqsin the root of the tree we want to build and the probability of reaching the root is set to 1. - Let
Lbe the set of current leaf nodes in the tree which initially contains only the root node. For each nodeljinL, find the predictor variableXi(i = 1, 2, 3, ... m) and indexk(k = 1, 2, 3, ... n) of a setSkfrom (7) which minimizes the average conditional entropy atlj, which is modified from (3) as - Determine the leaf node
lsplitat which the question asked leads to lowest average conditional entropy. - Partition
set_seqsatlsplitinto sample sequences whereXi = kandXi != k
-
if both these partitions contain more than a particular number of sample sequences that we call
min_samples,- Make two child nodes of lsplit, lsplit1 and lsplit2 and store the respective partitions of set_seqs in lsplit into them.
- Store the question
Xi ∈ Skintolsplit. - Remove
lsplitfromL, addlsplit1andlsplit2intoL - Go to step 5
-
else
- stop growing the tree.
-
if both these partitions contain more than a particular number of sample sequences that we call
- Since we have stored questions of the form
Xi ∈ Skin the internal nodes of the tree thus built, we can traverse the tree with the sample sequences inword_seqsobtained in step 2 of the implementation and reach different leaf nodes. In doing so, we can measure the relative frequencies of theTargetword of the sample sequences that reach their respective leaf nodes and consequently obtain a probability distribution on the vocabulary at each leaf node which serves as our prediction.
-
Why Word2Vec?
-
Helps achieve semantic relatedness, which is a metric defined over a set of documents or terms, where the idea of distance between them is based on the likeness of their meaning or semantic content as opposed to similarity which can be estimated regarding their syntactical representation, i.e [ cut & knife, words that occur in the same context ]
-
It is language agnostic, but requires a large corpus to be trained on to achieve good results
-
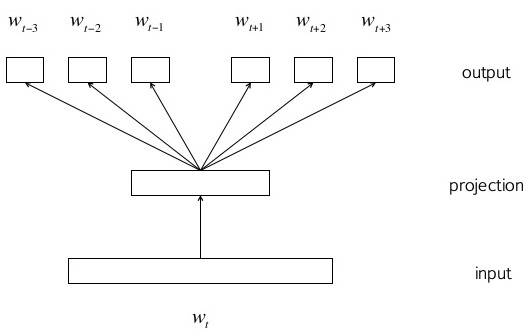
Skip gram: Skip gram is a neural network model, which takes one word and gives the context around this word. It works using back propagation, and as a side effect produces word vectors which we can cluster to obtain semantically similar groups of words.
{kind=link}
-
Word Vector properties
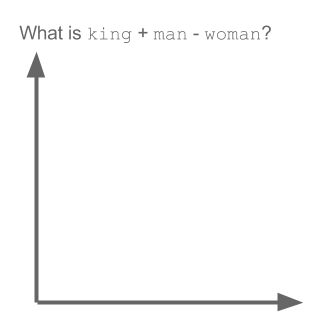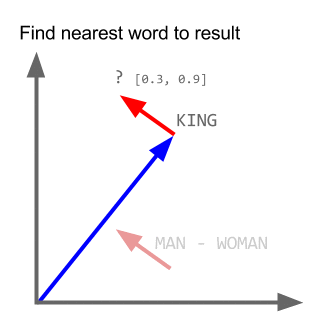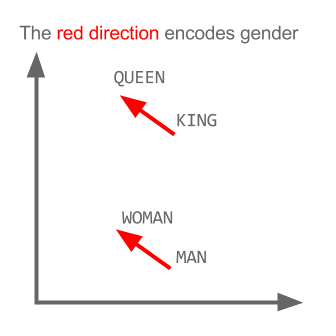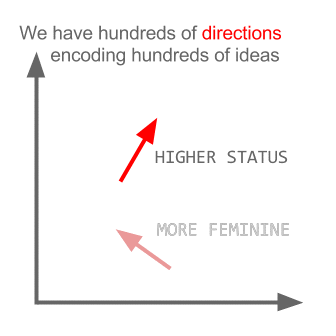
Source: 'A Word is Worth a Thousand Vectors', by Chris Moody
- K-Means based clustering: We resorted to K-Means to form groups of words from the word vectors.
- K-means from scikit-learn [number of random centroid inits = 20, Euclidean distance measure]
- Many cluster sizes were tried (50, 75, 100, 150, 500), results were better when the sets were more homogeneous (semantically), comparatively larger sets performed better in reducing entropy faster as we step down the levels in the tree.
- Here a couple of interesting word clusters generated by clustering Word2Vec vectors using K-means
cluster1 = "fabric, leather, fleece, velvet, silk, fabrics,
wool, satin, cloth"
cluster2 = "coleman, miller, ellis, gilbert, bradford, rick,
greene, dave, lucas, bobby, sox, joseph..."
We took 800 most common words from here and constructed a complete graph using 1-cosine similarity distance measure between each pair of word vectors. We computed a minimum spanning tree for this complete graph and then chose a threshold and removed all edges that had a distance measure more than this threshold. The connected components in the graph were now considered as a word groups.
We abandoned this approach, because of the following:
- There were only few connected components formed, with only few nodes in them.
- Obtaining the threshold was a problem.
- Most of the nodes were clustered in 1 component, rest of the components were very small size.
The images below are a few interesting parts of the minimum spanning tree formed.
![Word2Vec [Semantic Relatedness]](https://github.com/iisc-sa-open/trsl/wiki/images/mst-1.png)
Semantic relatedness - nodes represent words
![Word2Vec[Semantic-Relatedness]](https://github.com/iisc-sa-open/trsl/wiki/images/mst-2.png)
Semantic relatedness - nodes represent words
- We considered Word Net a curated web of words which can be used to retrieve Syn sets (Synonym sets) of words. But Wordnet ignores functional categories such as prepositions and also, we thought that this would make this process of getting groups of words language dependent, as Wordnet isn't available for many languages.
- So we had a need for constructing word groups in a language agnostic way, computationally. We found a solution in Word2Vec
- Reduction from parent [ not utilized now ] If the child node has a reduction greater than a certain reduction threshold, then the node is split, else the node is not split.
- Reduction from root - If the difference of the entropy of the root and the sum of all probabilistic entropy of all leaf nodes is greater than a certain reduction threshold then the leaf node with the highest reduction is chosen and split.
- Number of Samples - If the node has greater than a certain number of samples, only then split to child nodes is allowed. Number of samples is the frequency of occurrences of all the words in the ngram table, for a predictor variable
Xithat satisfies the question (Xi belongs to Si) and likewise for the ones that do not satisfy the question (Xi does not belong to Si)
- Utilization of word space for the algorithm will produce a probability distribution of the probable target word at the leaf node, this causes the predictions and tree walk to start mirroring the corpus, this requires the corpus to be really large to produce any feasible generic predictions, besides higher the predictor variable size utilized, lower the no of target variables which are actually followed by all those predictor variables.
- Utilization of set space for the same algorithm, causes the trsl to predict at the end of traversal, the set which is most probable rather than a specific word. This incorporates a lot of generality for the prediction however this is a feasible solution if only the sets are homogeneous, and the words in the set can be used interchangeably without violating the grammatical structure of the sentence.
- Possibly the set space utilization of the algorithm might help us detect grammatical structure of the language if the sets are tagged by their respective parts of speech.
- Utilization of the set space for the same algorithm causing the trsl to produce a probability distribution of sets over the leaf node, selecting the set and traversing through the corpus again to produce a word probability over this set will probably give us the advantages of both the techniques, incorporating generality for obtaining a homogeneous generic set at the leaf node, and computing the word probability over this set, to obtain the word probability based on any corpus not necessarily the same to obtain word predictions
- Building the tree over a large generic corpus using set space, and applying word space over the set achieved based on a specific domain can improve the results of predictions for that domain while maintaining some amount of generality.
We measured, and tuned the following:
- Input parameters – number sentences in the corpus, ngram, number of sets, size of vocabulary
- Measurements – number of leaf nodes in the tree, entropy at root node, Depth at which there is a 30%, and 60% reduction in entropy from the root node
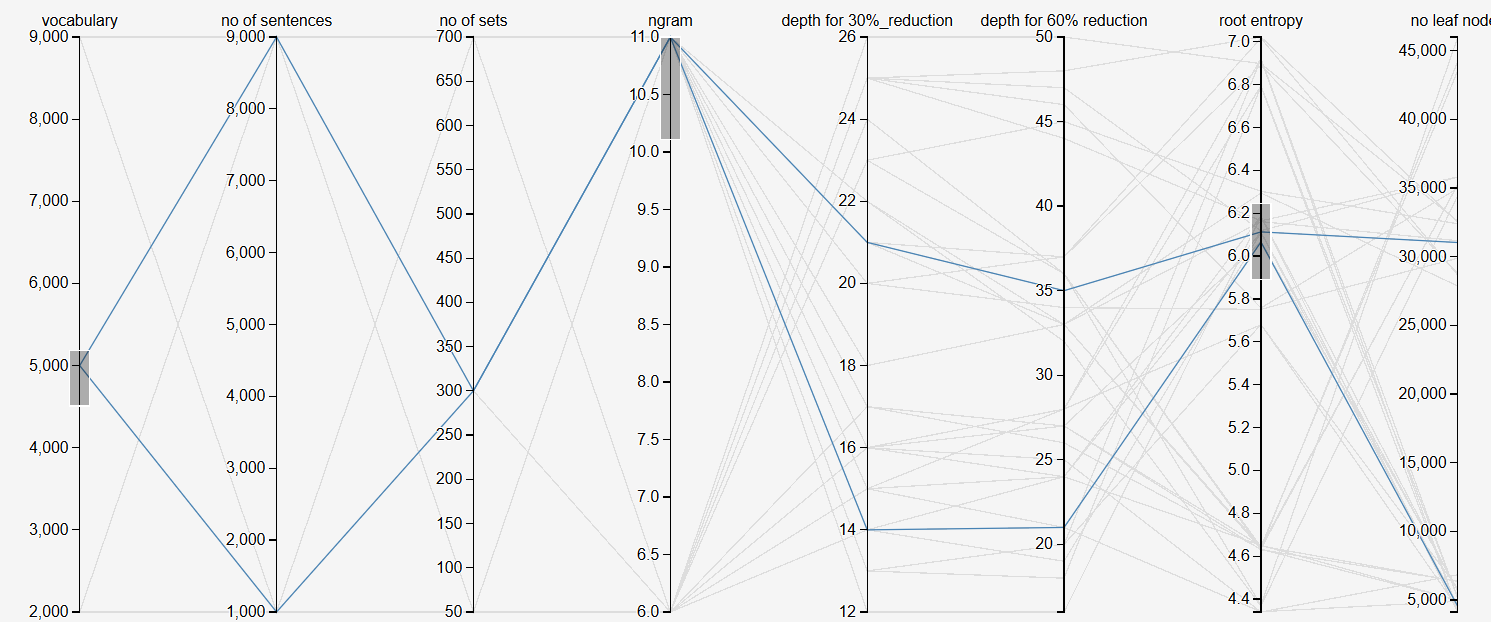 To make sense of the data, we used a data exploration tool called 'Parallel Coordinates'.
Explore the data here
To make sense of the data, we used a data exploration tool called 'Parallel Coordinates'.
Explore the data here
Corpus: Collection of all the inaugural speeches given by the US President since the 1700's
2015-08-03 05:49:14,255 INFO Depth Reached: 87 u'humanity never brought this upon as constitution found them the the direction and discipline of the church if state authorities acknowledged by which several religious societies which aborginal inhabitants of these countries i may regarded with the commiseration their history inspires endowed with the faculties and the rights of men breathing an ardent love of'
2015-08-03 05:52:10,558 INFO Depth Reached: 33 u'one day we shall not try to placate an aggressor by the false and wicked bargain of trading honor the security of americans have just free men remember that from the final choice a soldier's pack is neither heavy a burden as a prisoner's chains 3 knowing and not a united states be is strong'
### Prediction
Corpus: Collection of all the inaugural speeches given by the US President since the 1700's
Enter predictor words to predict the next: but you must look within Ten most likely words:[(u'the', 0.15789473), (u'them', 0.0526315), (u'men', 0.0526315), (u'accession', 0.0526315), (u'accession', 0.0526315), (u'it', 0.0526315), (u'normalcy', 0.0526315), (u'soverenignty', 0.0526315), (u'aspect', 0.0526315), (u'beseems', 0.0526315), (u'one', 0.0526315)]
Enter predictor words to predict the next: our enemies have always made Ten most likely words:[(u'.', 0.2058823), (u'the', 0.0882352), (u'to', 0.0735294), (u'is', 0.0441176), (u'of', 0.0441176), (u'as', 0.0294117), (u'are', 0.0294117), (u'have', 0.0294117), (u'we', 0.0294117), (u'u that', 0.0294117)]
----
## Future work
* Build Word2Vec training datasets and pre-computed models for Indian languages
* Pylons - the paper suggests the need for asking composite questions, at every node in the decision tree, and how Pylons can help there.
* Smoothing word probabilities on leaf nodes - again, as suggested by the paper
* Non-disjoint sets - build sets which have some intersection, vs the current implementation's disjoint sets. We believe this may improve the prediction of the target event. The means to be adopted to build such sets are:
* Using Agglomerative clustering on Word Vectors
* Using [UnsuPOS](http://wortschatz.uni-leipzig.de/~cbiemann/software/unsupos/)
-----
## References
#### Libraries
* [Word2Vec](http://code.google.com/p/word2vec/) - useful for set building, because of its relatedness properties
* [WordNet from NLTK](http://www.nltk.org/howto/wordnet.html) - considered for its synsets (synonyms, and semantic similarity properties), but later dropped because we found Word2Vec to be more effective; Word2Vec is language agnostic.
* ~~[NetworkX](https://networkx.github.io/)~~ - Used to construct spanning tree of words.
* [KMeans from SKLearn](http://scikit-learn.org/stable/modules/clustering.html) - Used for clustering word vectors.
#### Links
+ [numpy histogram](http://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.html) to calculate the probability distribution of words in the target column
+ [Scikit learn's feature extraction](http://scikit-learn.org/stable/modules/feature_extraction.html) could be useful in counting the number of occurences of words and also tokenizing the vocabulary into numbers.
+ [Numpy select](http://docs.scipy.org/doc/numpy/reference/generated/numpy.select.html) and [Numpy where](http://docs.scipy.org/doc/numpy/reference/generated/numpy.where.html) for querying arrays.
+ [Requests Docs](http://docs.python-requests.org/en/latest/) A great example of nice and clear documentation.
+ [Time it](https://docs.python.org/2/library/timeit.html) Useful Python module to measure execution time of code
+ [A very interesting application of Word2Vec](http://multithreaded.stitchfix.com/blog/2015/03/11/word-is-worth-a-thousand-vectors/)
+ [Hellinger Distance](https://en.wikipedia.org/wiki/Hellinger_distance) used to quantify similarity between probability distributions. Might come in handy.
#### References
+ [A Tree-Based Statistical Language Model for Natural Language Speech Recognition (1989) by L R Bahl, P F Brown, P V de Souza, R L Mercer](http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=32278)
+ [Efficient Estimation of Word Representations in
Vector Space](http://arxiv.org/pdf/1301.3781.pdf)
+ [Distributed Representations of Words and Phrases
and their Compositionality](http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf)
+ [Word2Vec Parameter Learning Explained - Xin Rong](http://www-personal.umich.edu/~ronxin/pdf/w2vexp.pdf) - An explanation of continuous bag of words and skip-gram models used in Word2Vec