Results
We captured some metrics to see if we can spot a pattern, and also captured the actual output of the algorithm. These are list below
For details on this topic, refer to https://github.com/iisc-sa-open/trsl/wiki/Algorithm-in-the-implementation#word-space-vs-set-space
-
Mapping Average Entropy <-> Level or Depth of the tree - the tree is constructed by asking questions based on sets ( does a word belong to a set of adjectives ). The sets are constructed, keeping a cluster size in mind. The intention was to understand if there is a correlation between the number of clusters, the depth of the tree, and the average entropy.
-
50 clusters, 70 reduction, 8851 vocabulary
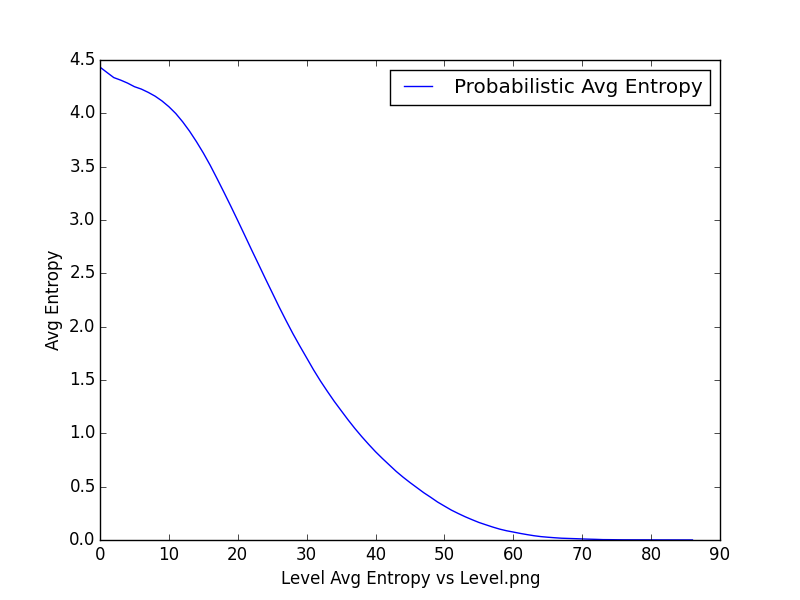
-
100 clusters, 70 reduction, 8851 vocabulary
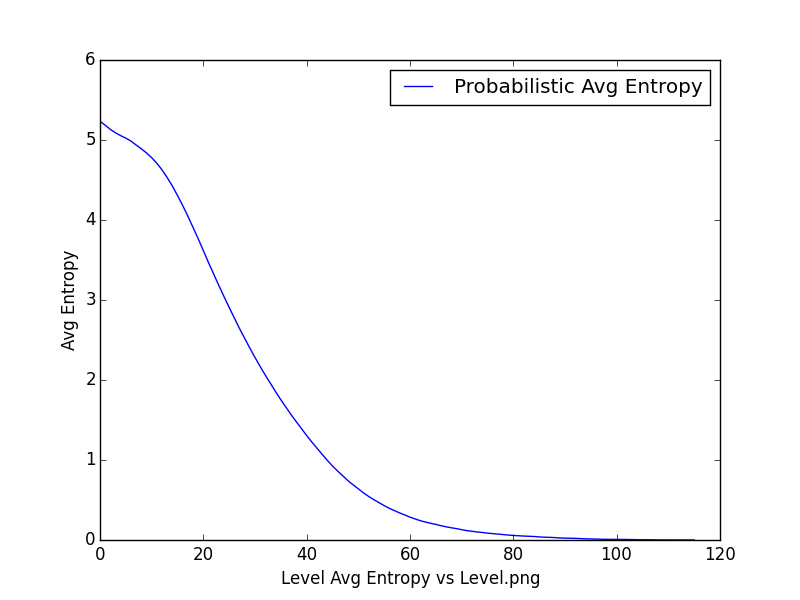
-
500 clusters, 8851 vocabulary
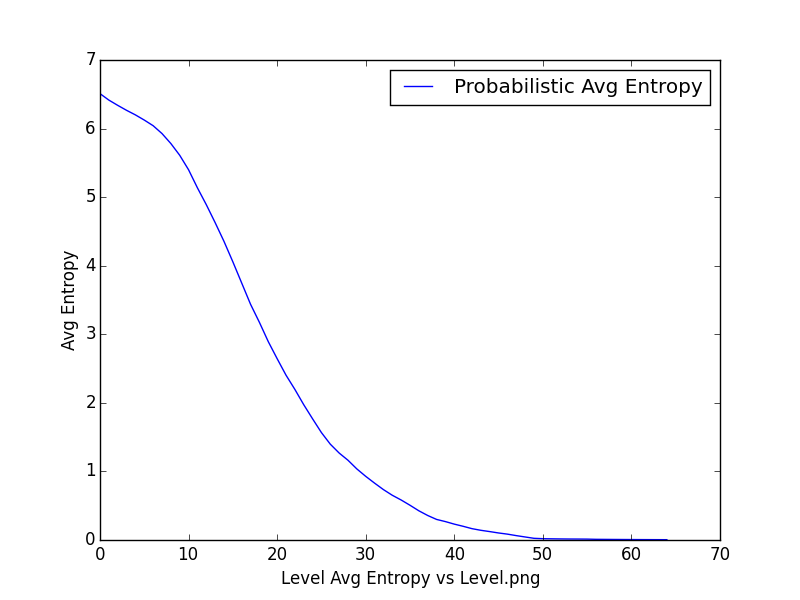
-
-
Depth v/s No of Fragment Indices
-
500 clusters, 100 reduction, 8851 vocabulary, 10 samples
-
-
No of Nodes v/s Level
-
50 clusters, 70 reduction, 8851 vocabulary
-
100 clusters, 70 reduction, 8851 vocabulary
-
-
Random Tree Walk
Corpus utilized is a collection of all the inaugural speeches given by the US President since the 1700's
-
Prediction
Corpus utilized is a collection of all the inaugural speeches given by the US President since the 1700's





