InfluxDB Connector Issue #8
Comments
|
Hi @gefaila,
Yes, but Google Data Studio requires static schema. The connector internally uses pivot function to determine schema for GDS. Schema query: You could prepare Task that normalize your data into new Measurement. See - https://github.com/influxdata/influxdb-gds-connector/tree/master/examples#performance Regards |
|
Hi @bednar, The Schema query runs fine on the data in my bucket, 2020-11-09-10-50_chronograf_data.xlsx Is there anything wrong with this data it's returning to GDS? If, not, are there any documented guidelines for what this data should conform to? I checked out the link you sent above
However, there is no actual definition of acceptable and unacceptable data, Just a single example of a very long flux query that is apparently returning something that is OK for GDS. Maybe some clarification is needed for the general case? |
|
Hi @gefaila, The schema query should produce only one table, because the GDS needs consistent schema. Based on your export You could find all your tags by:
Yeah, you are right. We need clarify how to data should looks like to use in GDS. Could you export result of schema query to CSV? Regards. |
|
In that case I'd like to create a filter in the GDS connection page that allows me to select the tag filters that I'm interested in. That way I can drop the tags. Furthermore, the querying of InfluxDB data with |
A good way of giving the user the ability to make sure the data returned was suitable for GDS would be to allow the user to write a flux query that returned data in the format GDS needs it. E.g. one table with agreed structure. Presumably, users of the tool are able to do this, otherwise they wouldn't be connecting InfluxDB? |
The query with this For getting data we use range specified in report - https://support.google.com/datastudio/answer/9272806?hl=en. By default, the date range provided will be the last 28 days excluding today. If a user applies a date range filter for a report, then the date range provided will reflect the user selection.
We use two type of queries: GetSchema
GetData
What do you think about ability to specify Flux filter? You will be able to specify something like: Regards |
I quite like that.
|

|
However, stepping back a bit, I see no reason why I would not want to build a dashboard that allowed the filtering to happen 'afterwards'. Again, this is parallel to the Chronograf dashboards with a variable. On one of my dashboards I can select the host that I'm interested in viewing. To me that seems much more sensible and usable functionality to aim for in GDS. What do you think? |

Yeah, of course. We use this type of filter here: https://datastudio.google.com/s/p19vh-b82Sw - "Country Filter". Do you think that update our docs to clarify required schema for GDS will be enough? Something like: Required schemaThe Google Data Studio requires know schema of your data. Each column requires a data type that should be consistent across whole table (= measurement in InfluxDB). For that reason the InfluxDB Connector needs to determine schema from your InfluxDB by this Please be ensure that the query above could be successfully use in your InfluxDB. LinksRegrads |
Well I don't see why it's necessary for the user to specify flux filters. You've already confirmed that filtering is possible after building the dashboard
So why compel the user to filter so that you can even make a connection! The fact is that a normal bucket will contain data with multiple tags. Therefore your schema will not normally work. |
No not really. I think the real problem is this:
Actually InfluxDB only requires that data types are consistent within tables as defined by a set of tags. The root assumption that the data type should be consistent for all tables returned where measurement = "data" is not what InfluxDB assumes at all. |
|
What I don't quite understand is the actual tags that GDS doesn't like in my data tables. And I can't run the flux query you specify for the reasons I give above. i.e. you are forcing a search through all data from 1970 to current day. Apart from the fact that this takes longer than the timeout, the query will in most cases run out of memory. It's impossible in the general case where people are using InfluxDB for what it's designed for GB of data every day. |
|
I can only get the flux query to run by considering less time:
Then this delivers a single table Even querying 30d causes InfluxDB cloud to run out of memory. This will be the case for most customers who have significant data in their tables |
|
Querying 30days runs out of memory |
The
The key problem here is that the Flux doesn't have
Yes, it scan whole your measurement :(
Try to insert this line protocols into database: If we specify the range to
So we have to add an advance option into Connector configuration that will limit range in Schema query. |
|
New option in Configuration screen: The range that is used for determine your InfluxDB data schema. - https://todo_link_to_doc What do you think? |
|
It's the
that's taking the time and killing the query time and memory. But the good news is you don't need it.
It contains tables that show data types for everything in the database Can you work with that to build the schema you need? |
|
@gefaila nice catch 👍 Thanks! I think the following query could be a solution: Could you try it with your data? If you could share a result of query it will be awesome. |
|
It works! 👍
you only need
For me this returns the following |
|
Hi @bednar |
|
Hi @gefaila, I want start works on this as soon as possible ... probably at Thursday or Friday. Thanks a lot with your help, the query is fine and we will use it 👍 Regards |
|
Really really cool!
Thanks for delivering this. I think lots of people will love it!
I enjoyed oiling the creative cogs!!
Cheers
Andrew
On Fri, 20 Nov 2020 at 09:47, Jakub Bednář <notifications@github.com> wrote:
Hi @gefaila,
you could track progress at #9
Regards
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or unsubscribe.
|
|
Hi @gefaila, there is prepared a test version of the Connector: Could you test it with your schema? |
|
Hi Jacub,
I'm sure it's a small thing .. but it's doesn't quite yet work.
I get this in return:
…Community Connector Error
There was an error caused by the community connector. Please report the issue to the provider of this community connector if this issue persists.
Connector details
"GetFields from: https://eu-central-1-1.aws.cloud2.influxdata.com" returned an error:Exception: Argument too large: value
Error ID: 943f700f
|
|
It is caused by too large schema. We have to change how we cache the produced schema. |
I see. |
|
Hi @gefaila, the commit 118edfe fixes: Could you try the fixed version?
It is true, but Google Data Studio is like other visualisation and analytics tool - their loves well-structured data. Here is nice article from Tableau - https://www.tableau.com/learn/get-started/data-structure |
|
I think influx tables fulfill all of that. Can you explain what GDS needs the influx data to conform to? Do you have an example influx bucket that conforms to this? Can you give us a list that outlines in plain language the restrictions on influx buckets?
|
|
I'm failing to see how our industrial IIOT data doesn't conform to this. Is there a specific problem that our data doesn't conform to that you can point to and clarify? |
|
From my experience with GDS there are these constrains: 1. Avoid unnecessary data
2. Avoid
|
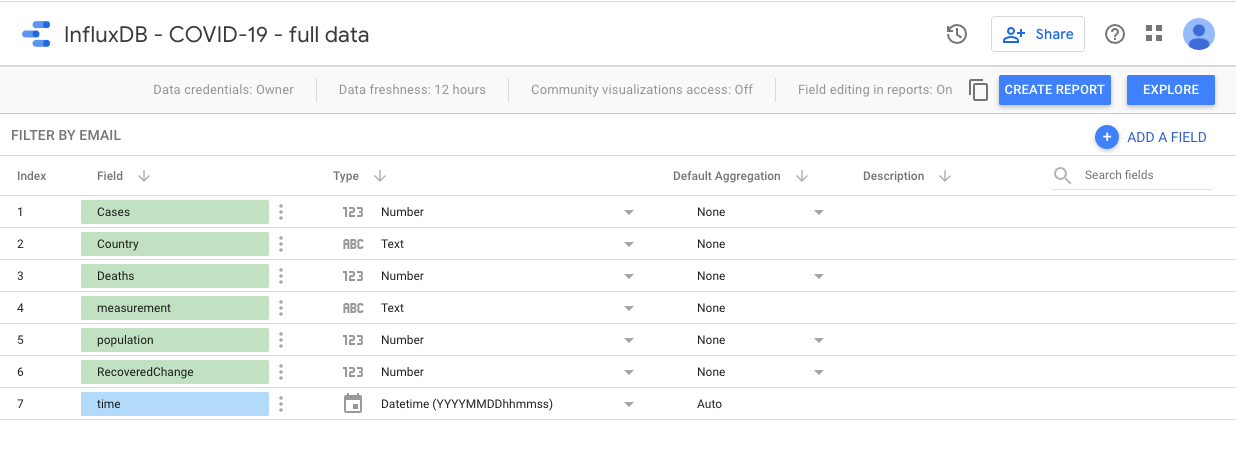
|
Hi @bednar ! We meet again. You are very active on Influx! As before, we have IoT data and of course some of it is Boolean and some is Float and some are integers. But the connector doesn't like this "normal" Bucket. But I'd really like to use your connector. Can we fix it? |

|
I'm sure you may ask what data is yielded by the query above .... Gives the following file. It would be better if you could let the customer write the flux so that the data came in the way your connector needs it. |
The #9 improve a schema query and currently is in approving. You can try this version by following link: https://datastudio.google.com/u/0/datasources/create?connectorId=AKfycbySDF4eD7wmA_awZ6aoCwENuXs1Opw_T0DIJ8F-MVI
There is a problem with requirements from GDS. The GDS expects static tabular schema. So we are not able to supports scheme where field has a different types.
Currently we don't support this type of configuration. How will looks your query according to your provided data - |
Very excited to try this connector.
I have a bucket with a lot of data in. It seemed to make the connector 'fall over'
I'm quite experienced on InfluxDB and there is nothing fundamentally wrong with having _value as being int and float for different _field values. In fact it's fairly fundamental. There must be something that the connector is assuming about InfluxDB 2.0 data that is (in general) not always true.
Any ideas how I'd move forward to use this excellent tool?
The text was updated successfully, but these errors were encountered: