Improve performance of Record.into(Table) and related calls #11058
Comments
|
Thanks a lot for your report, and I'm sorry for the inconvenience about the removed comment on the manual. We hadn't removed only your comment, but all comments from the website, see #10962. I replied to your comment, and you should have received a notification message. You can still access it on disqus.com: If you haven't received a notification, this just shows once more that disqus does not work well enough for us. I've lost way too many notifications myself, with messages having gone unanswered for months! You're right, we should extract a mapper for the duration of the loop instead of looking it up on every record. We already do that for a variety of other mappings (e.g. |
|
Related: #6639 |
|
I'm not sure how to read your flame graph, but in a profiling session, it seems obvious that a lot of CPU cycles are wasted in wrapping the
Another hot spot is looking up fields in the fields array with the O(N) lookup algorithm:
Both can obviously be improved. |
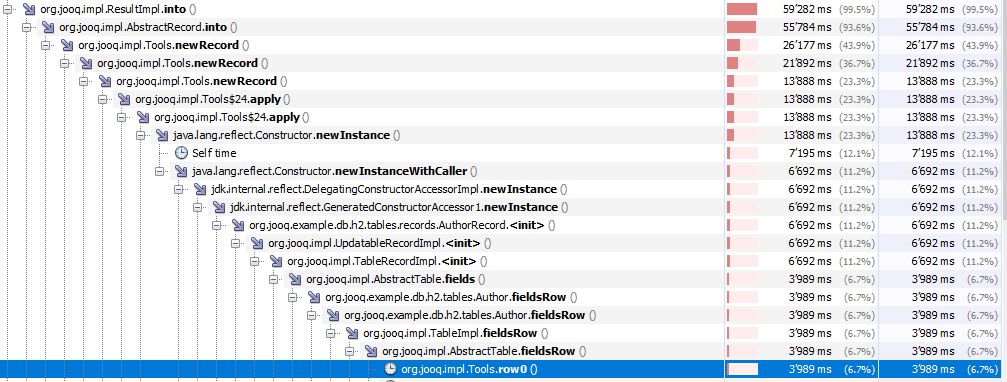

|
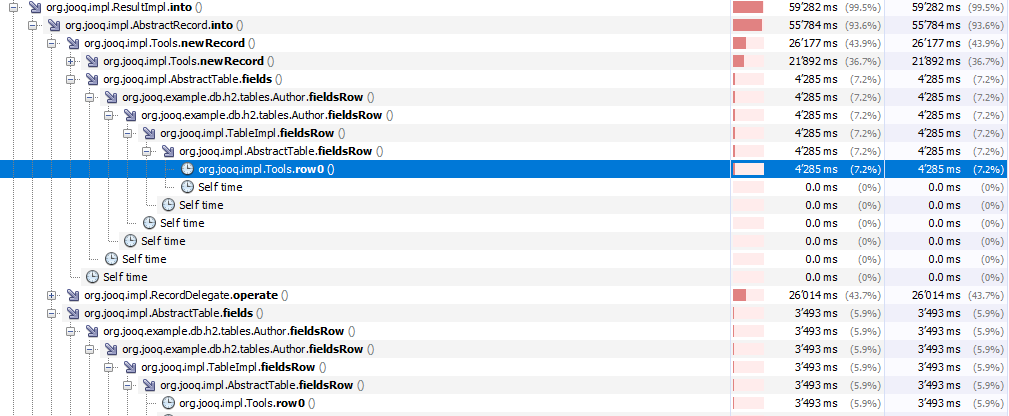
Well, caching the BeforeAfterOther mapping benchmarks seem unaffected by the change, neither positively nor negatively. |
|
With the cached
Further improvement can be seen: |
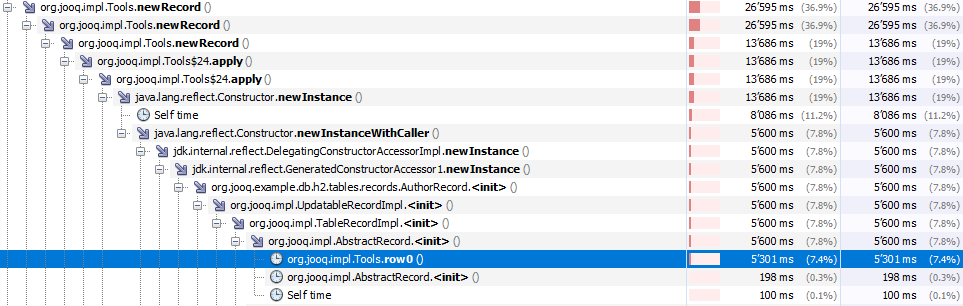
|
These were the low hanging fruit, which brought a 30% improvement, which isn't bad. Now the elephant in the room is the unnecessary, repeated call to
|

|
It's not worth looking at
Did you have anything specific in mind? |
|
Some improvements will be backported to 3.14.5 (#11060) |
|
I probably missed the notification, but had guessed you migrated away from that comment system. Github does have its many flaws but it does an OK job at reporting and discussing issues! Thanks for your super-prompt action on this, and it seems I'd be more getting in your way than anything else, but please do let me know if I can do anything that would help! |
Well, nothing clear obviously since I don't know the inner working of jOOQ very well, but basically hoped to compute the "mapping" of the kind of records returned by the actual query to the kind of records I want once, then apply that mapping 200 times, as my investigation led me to believe constructing the mapping was the slower part, and moving the data around was fast. |
|
Hmm, something that isn't being measured currently in our benchmarks is your usage of non- |
Yes, the remaining bottleneck is the lookup of source column index -> target column index, which is done on each iteration. |
If you could add the query leading to your flamegraph, that would be very useful |
|
Here is the SQL query in my debugging case. It lets us do a batch query for all messages in several conversations ("experiences", here 60 of them), with pagination (order by ... limit 6) of messages inside each conversation. SELECT "tmp_table"."target_id",
"message"."id",
"message"."uuid",
"message"."created_at",
"message"."event_time",
"message"."text_content",
"message"."experience_id",
"message"."type",
"message"."starred",
"message"."doctor_id",
"message"."visible_to_patient",
"message"."file_upload_id",
"message"."retry_counter",
"message"."reply_message_id",
"message"."is_reply",
"message"."sender_type",
"message"."is_automatic",
"message"."has_deleted_content"
FROM (VALUES (1),
(2),
(3),
(4),
(5),
(6),
(7),
(8),
(9),
(10),
(11),
(12),
(13),
(14),
(15),
(16),
(17),
(18),
(19),
(20),
(21),
(22),
(23),
(24),
(25),
(26),
(27),
(28),
(29),
(30),
(31),
(32),
(33),
(34),
(35),
(36),
(37),
(38),
(39),
(40),
(41),
(42),
(43),
(44),
(45),
(46),
(48),
(47),
(49),
(50),
(51),
(52),
(53),
(54),
(55),
(56),
(57),
(58),
(59),
(60)) AS "tmp_table" ("target_id"),
LATERAL (SELECT "public"."message"."id",
"public"."message"."uuid",
"public"."message"."created_at",
"public"."message"."event_time",
"public"."message"."text_content",
"public"."message"."experience_id",
"public"."message"."type",
"public"."message"."starred",
"public"."message"."doctor_id",
"public"."message"."visible_to_patient",
"public"."message"."file_upload_id",
"public"."message"."retry_counter",
"public"."message"."reply_message_id",
"public"."message"."is_reply",
"public"."message"."sender_type",
"public"."message"."is_automatic",
"public"."message"."has_deleted_content"
FROM "public"."message"
WHERE "public"."message"."experience_id" = "tmp_table"."target_id"
ORDER BY "public"."message"."event_time" DESC, "public"."message"."created_at" DESC
LIMIT 6) AS "message";This query returns 168 records here: Then we manually group the resulting rows by conversation (target_id) and convert them into I can try to inspect the jOOQ Query object right before executing it too if that would help. |
|
A minor, related improvement would be if |
|
A lot of improvements have been committed to 3.15 and 3.14 branches. If any of you, @alacoste and @arlampin are interested in verifying if this fixes your issues, early feedback would be very useful prior to releasing. You can build the jOOQ Open Source Edition from github, or access snapshots builds from here, if you're licensed:
I think this issue here is still not fixed, as I haven't benchmarked any |
|
Will give it a try this afternoon! |
|
OK, I am running 100 times the same block of code linked earlier and exhibiting the performance issue, measuring on each run the time taken by On that metric I can't see any major difference between jooq v3.14.4 and my locally built v3.15.0-SNAPSHOT. There is quite a bit of variance, but both take ~50ms on average. Here is the profiling results on 3.15.0-SNAPSHOT: server_[run]_2020-12-04-200049.jfr.zip Screenshot of the interesting part: |
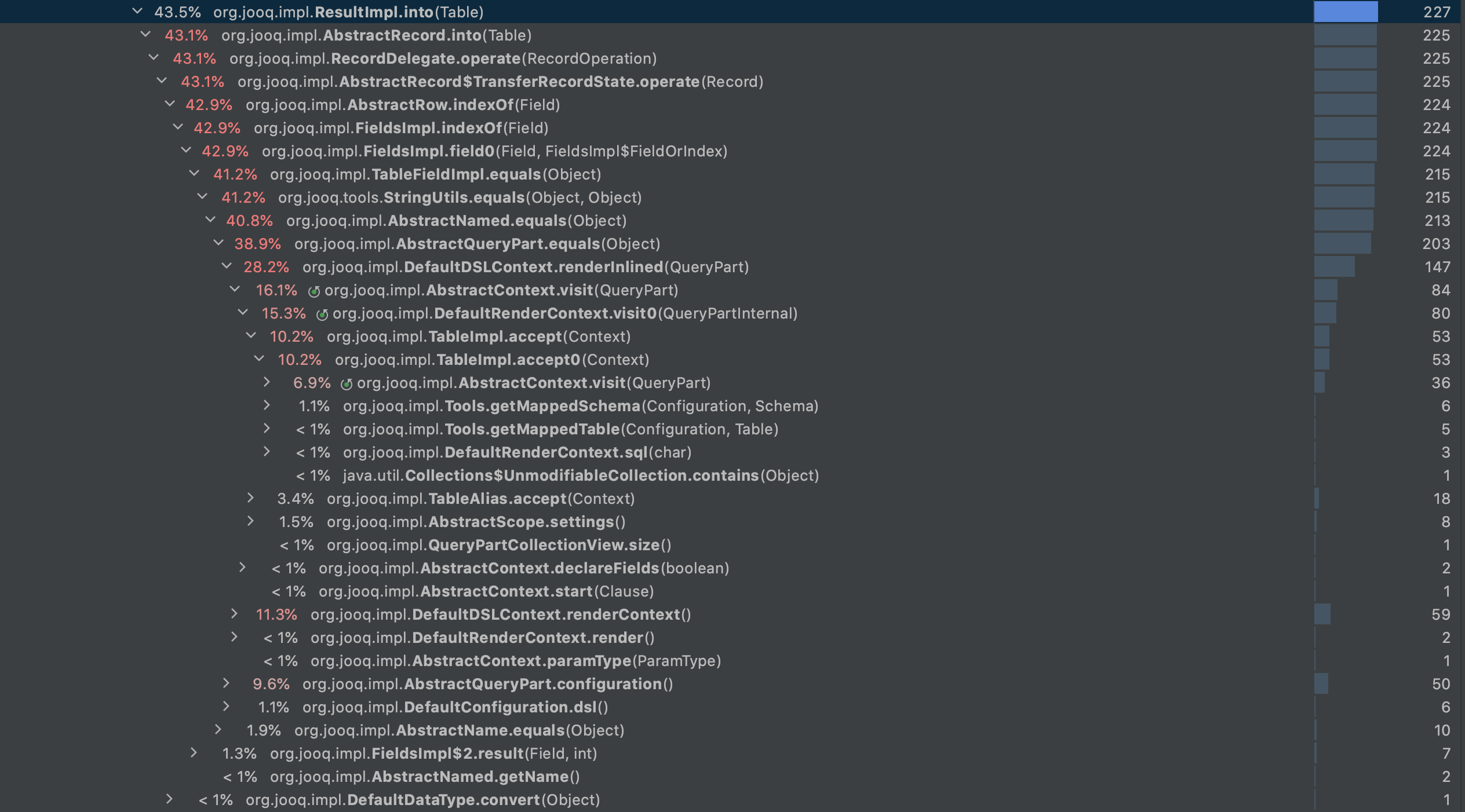
|
Thanks for the feedback, @alacoste. I'll be looking into this further. There are a few other, related issues I'm benchmarking, currently, including #11099 and also #8762. It seems the caching of |
|
Looking into the JFR file now with VisualVM. As mentioned elsewhere, we should absolutely try to avoid calling A lower hanging fruit might be to use a cached version of
We already have a global instance in |
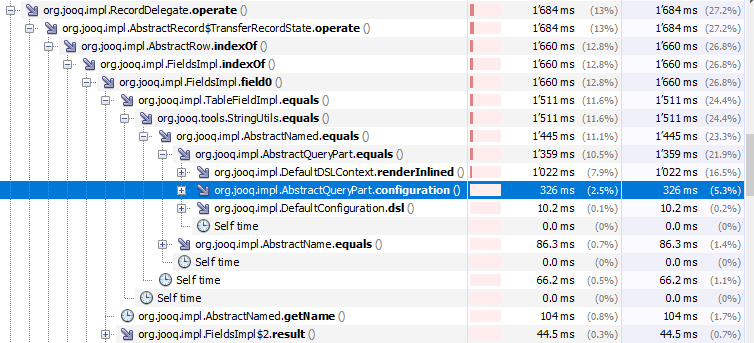
|
Will fix this in a separate issue: #11125. |
|
Thanks again @lukaseder, please do lmk if I can be of assistance! |
|
Well, if you have time, an self-contained MCVE (we have a template here: https://github.com/jOOQ/jOOQ-mcve) for the reproducer here would be very useful: #11058 (comment) Otherwise, I'll be able to look into generally improvable things, but maybe not the exact thing you're running into... |
|
For the record, I'll investigate all the locations where we call |
|
Without a full MCVE, you could put a breakpoint in |
|
Hi @lukaseder and sorry for the long radio silence over the holiday break! I just checked again since you already merged a couple of fixes but our use-case still exhibits the performance problem, so I finally got around to creating a MCVE :) Here it is: https://github.com/nabla/jOOQ-mcve I'm running it against a local postgres DB, and the setup is the following:
On my machine it takes ~100ms to perform As always let me know if I can be of any additional help :) |
Hi, and first of all thanks for a this great tool, we've been able to do almost everything we wanted so far on top of this clean abstraction that is jOOQ!
We are starting to run into performance issues as our DB fills up, and I tracked down part of it to what I believe is an inefficiency when converting "untyped"
Records into "typed"MyTableRecords.During my debugging, I found out that
Record.into(Table)takes a small but non-negligible time, in my example debugging case ~200us. Unfortunately on a query returning 200 results this quickly adds up to ~40ms, a very large overhead for this simple query that itself takes ~10ms.Profiling and looking at the code itself, it seems that most of the time is spent computing the mapping between the fields in the resulting Record and the target MyTableRecord:
From that observation, I think it should be possible to greatly reduce the overhead for queries returning relatively large result sets by only computing this mapping once and re-using it for all resulting records, h and I hoped this would be implemented in
Result<Record>.into(Table), but unfortunately all this does is looping over all resutling record and callingRecord.into(Table).Obviously I know quite little of the jOOQ codebase so please lmk if I missed something obvious, or if there is a reason preventing to factorize the mapping computation to happen only once per query as opposed to once per record.
I'm planning to try and implement an alternative version of Result<>.into to try and do that as a PoC/workaround when I have the time, but obviously it would be lovely if the library itself supported it, and if I'm right a lot of other jOOQ users would benefit too!
Thanks,
-Arthur
Note:
I had posted a probably better written version of this as a comment on https://www.jooq.org/doc/latest/manual/sql-execution/performance-considerations/ a couple weeks ago, but it seems the discussion threads on the documentation pages have been entirely removed basically right after :(
So sorry if this issue is a bit less precise than it could be, I'm reconstructing my findings mostly from memory.
The text was updated successfully, but these errors were encountered: