You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
{
"data": {
"article": {
"id": "3",
"createDate": "2016-08-01",
"title": "GraphQL基础概念",
"subtitle": "A query language created by Facebook for decribing data requirements on complex application data models",
"content": "省略...",
"tags": [{
"name": "graphql",
"label": "GraphQL"
}]
}
}
}
Motation,执行修改操作。
mutation addArticle($input: Article!) {
addArticle(input: $input) {
id
title
}
}
{
hero {
...NameAndAppearancesAndFriends
}
}
fragment NameAndAppearancesAndFriends on Character {
name
appearsIn
friends {
...NameAndAppearancesAndFriends
}
}
GraphQL技术分享(上)概念篇
目录大纲
1、什么是GraphQL
2、GraphQL核心概念
3、能为团队带来什么
一、GraphQL介绍
1、什么是GraphQL?
简单的说,GraphQL是由Facebook开源的一套**“用于API的查询语言”,全称是“Graph Query Language”**。

不同于数据库的SQL,GraphQL是一种前后端数据交互的规范,只是通过类似SQL查询的方式,对后端提供的接口数据,进行自定义查询,但是它的数据源需要开发者自己定义,而不是任由前端人员传入GraphQL语句,直接读取数据库。
它不局限于编程语言,任何语言都可以实现这套规范。
https://graphql.cn/code/
2、GraphQL生态
awesome-graphql上列举了Github上面开源的并且十分有用的graphql相关的服务端、客户端以及生态链相关的其他工具。
https://github.com/chentsulin/awesome-graphql
GraphiQL:
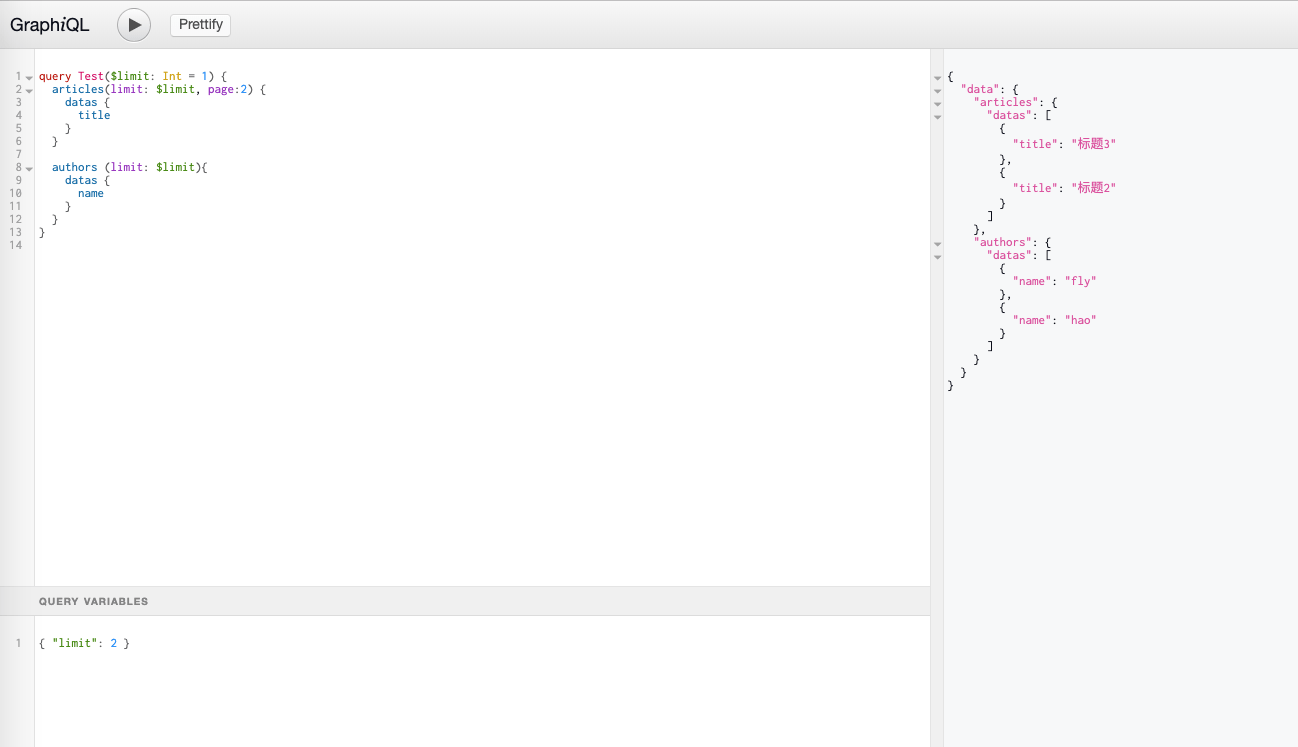
Graphql-Network:

GraphQL-Voyager:
二、GraphQL核心概念
1、Type System
GraphQL 的强大表达能力主要还是来自于它完备的类型系统,与 REST 不同,它将整个 Web 服务中的全部资源看成一个有连接的图,而不是一个个资源孤岛,在访问任何资源时都可以通过资源之间的连接访问其它的资源。
总而言之,GraphQL中的Type,就是描述和表达这些视图模型最基本的要素。
GraphQL 不单单支持简单类型,还支持一些其他类型,如 Object, Enum, List, NotNull 这些常见的类型,还有 Interface, Union, InputObject 这几个特殊类型。
2、Query & Mutation
GraphQL的查询语法同我们现在所使用的有一大不同是,传输的数据结构并不是 JSON 对象,而是一个字符串,这个字符串描述了客户端希望服务端返回数据的具体结构。
Query,查询操作。
{ "data": { "article": { "id": "3", "createDate": "2016-08-01", "title": "GraphQL基础概念", "subtitle": "A query language created by Facebook for decribing data requirements on complex application data models", "content": "省略...", "tags": [{ "name": "graphql", "label": "GraphQL" }] } } }Motation,执行修改操作。
{ "data": { "addArticle": { "id": "3", "title": "GraphQL基础概念" } } }在查询字段时,是并行执行,而变更字段时,是线性执行,一个接着一个。
3、Resolver
GraphQL的执行过程:
参考链接:https://juejin.im/post/5ceb1e28f265da1bb80c0b70
现在让我们用一个例子来描述当一个查询请求被执行的全过程。
{ "data": { "human": { "name": "Han Solo", "appearsIn": [ "NEWHOPE", "EMPIRE", "JEDI" ], "starships": [ { "name": "Millenium Falcon" }, { "name": "Imperial shuttle" } ] } } }你可以将 GraphQL 查询中的每个字段视为返回子类型的父类型函数或方法。事实上,这正是 GraphQL 的工作原理。每个类型的每个字段都由一个 resolver 函数支持,该函数由 GraphQL 服务器开发人员提供。当一个字段被执行时,相应的 resolver 被调用以产生下一个值。
如果字段产生标量值,例如字符串或数字,则执行完成。如果一个字段产生一个对象,则该查询将继续执行该对象对应字段的解析器,直到生成标量值。GraphQL 查询始终以标量值结束。
4、Introspection
我们有时候会需要去问 GraphQL Schema 它支持哪些查询。GraphQL 通过内省系统让我们可以做到这点!
5、Validation
通过使用类型系统,你可以预判一个查询是否有效。这让服务器和客户端可以在无效查询创建时就有效地通知开发者,而不用依赖运行时检查。
片段不能引用其自身或者创造回环,因为这会导致结果无边界。
{ "errors": [ { "message": "Cannot spread fragment \"NameAndAppearancesAndFriends\" within itself.", "locations": [ { "line": 11, "column": 5 } ] } ] }三、能为团队带来什么
1、GraphQL能提供哪些便捷?
单一入口
简化了**“版本管理”和“路径管理”**。
数据聚合
这里的数据聚合,分前端和后端两种意义:
从前端的意义上来讲,可以做到多个查询接口合并成一个请求,后端解析后并行执行。
从后端的意义上讲,是封装了多个服务提供的数据。
避免数据冗余
我们在传统的 RESTful 处理冗余的数据字段大约有这么三种处理方式:
在GraphQL中如何去做:
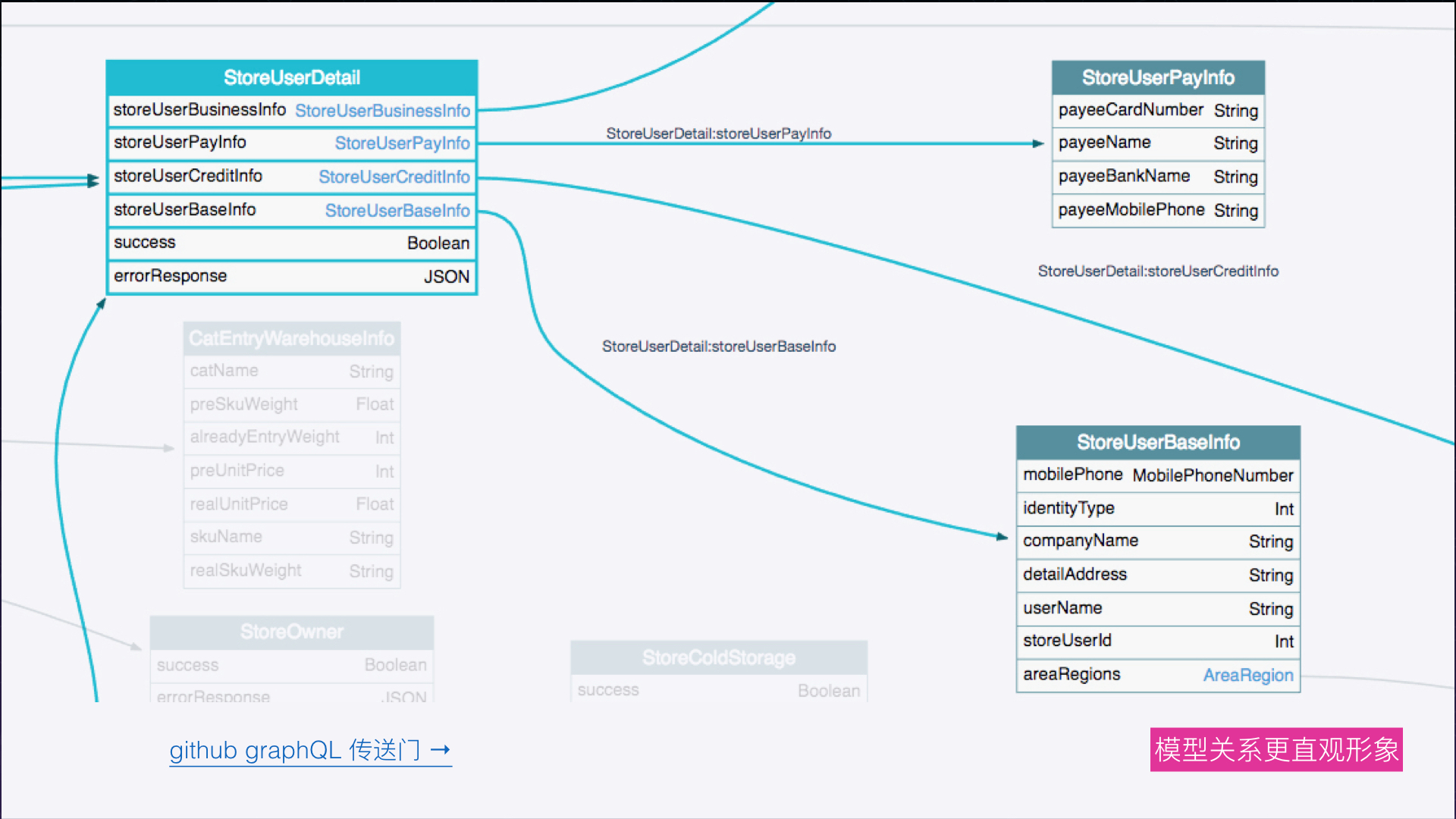
接口文档和模型关系
GraphQL 类型定义的时候我们可以对类型以及类型的属性增加描述 (description) , 这相当于是对类型做注释,当类型被编译以后就可以在相应的工具上面看到我们编辑的类型详情。
模型关系演示:https://apis.guru/graphql-voyager/
* 约束规范
### 2、我们需要解决哪些问题
权限认证
基本上,有三种情况会发生:
1、已经登录的用户发出GraphQL查询,未登录的用户不可以。认证在非GraphQL节点完成。
2、所有用户都可以发出GraphQL查询,未登录用户可以使用其中的一个子集,认证在非GraphQL节点完成。
3、所有用户都可以发出GraphQL查询,认证就由GraphQL节点完成。
N+1 问题
这里的 N + 1 就是db operation的次数
为了防止N+1问题,社区为GraphQL提供了一个解决方案: DataLoader。其原理就是,在需要查询数据库的时候将查询进行延迟,等到拿到所有的查询需求之后再一次性查询出来。在graphene里面,批量查询可以这样写:
最终,仅需要两次数据库查询就完成了两个批量查询,即:
缓存
可以提供对象的标识符以便客户端构建丰富的缓存
在基于入口端点的 API 中,客户端可以使用 HTTP 缓存来确定两个资源是否相同,从而轻松避免重新获取资源。这些 API 中的 URL 是全局唯一标识符,客户端可以利用它来构建缓存。然而,在 GraphQL 中,没有类似 URL 的基元能够为给定对象提供全局唯一标识符。
方案:使用全局唯一ID
一个可行的模式是将一个字段(如 id)保留为全局唯一标识符。这些文档中使用的示例模式使用此方法
这是向客户端开发人员提供的强大工具。与基于资源的 API 使用 URL 作为全局唯一主键的方式相同,该系统中提供 id 字段作为全局唯一主键。
如果后端使用类似 UUID 的标识符,那么暴露这个全局唯一 ID 可能非常简单!如果后端对于每个对象并未分配全局唯一 ID,则 GraphQL 层可能需要构造此 ID。通常来说,将类型的名称附加到 ID 并将其用作标识符都很简单;服务器可能会通过 base64 编码使该 ID 不透明。
3、RPC vs REST vs GraphQL
RPC
REST
GraphQL
The text was updated successfully, but these errors were encountered: