For my English speaking friends: a fun project comparing word usage by real Tomio Okamura (Czech xenophobe of Japanese descent) and a fake account operated in his name by an unknown prankster.
As this project is relevant mainly to the Czech Republic the description will continue in the Czech language.
Pro mé česky hovořící přátele: malý projekt, který si klade za cíl technickou analýzu twitterové timeliny skutečného Tomio Okamury (@tomio_cz) a jeho fejkového alter ega (@Tomio_Okamura).
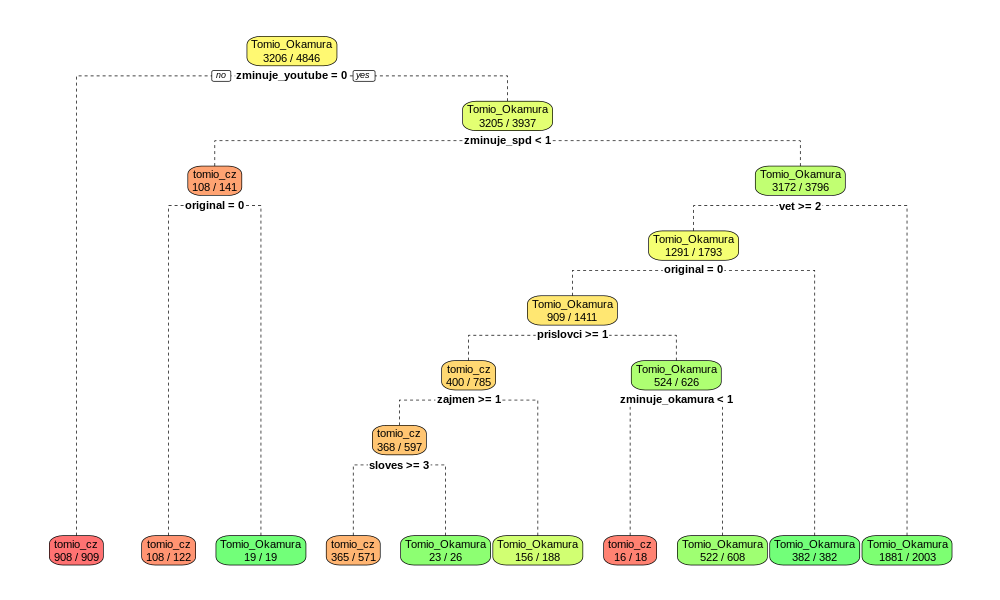
Dle vypozorovaných odlišností navrhuje klasifikační algoritmus, který dokáže s vysokou mírou jistoty z textu rozpoznat, zda jeho autor má na profilovce v rohu vlaječku nebo, hm..., něco jiného.


- pracuju ve světě
tidyverse, takžedplyraggplotmísto base R - pro stažení dat používám
rtweet - pro rozbití textu na slova
udpipe - pro úvodní klasifikaci
rpart- což je rozhodovací strom; zejména proto, že se dobře ukazuje - pro sofistikovanější klasifikaci
keras- což je neuronová síť; přesnější než strom, ale trošku black box

- erkový kód na stažení timeliny obou Tomiů (celkem je to necelých 5000 tweetů), rozbití do slov (78 tisíc slov, to je obsah tak čtyř, na VŠE možná pěti diplomek)
- porovnání relativní četnosti (účty mají nestejný počet tweetů, takže absolutní hodnoty jsou neporovnatelné) hlavních slovních druhů oběma účty
- dvě varianty rozhodovacího nástroje - strom s přesností ~90% a neuronka s přesností ~92%
Erkový kód, rozdělený pro přehlednost do pěti kroků v samostatných souborech:
- stažení dat z twitteru; vyžaduje vlastní přístupové heslo (v duchu hesla piju za svý) - tento krok lze přeskočit
- tokenizaci textu z tweetů do slov
- frekvenční analýzu po slovních druzích a přípravu obrázků do adresáře /img
- zpracování podkladu pro klasifikaci, včetně lehkého feature engineeringu dle poznatků z předchozí odrážky
- klasifikace pomocí stromu (rpart)
- klasifikace pomocí neuronky (keras)
V adresáři /data jsou podkladová data aktuální k začátku prosince 2018. Takže repo bude fungovat i bez hesla k twitteru, jenom nebude tak žhavě aktuální.