[20210829] Weekly AI ArXiv 만담 #22
Comments
Paper
|




Tesla AI day (8/19)
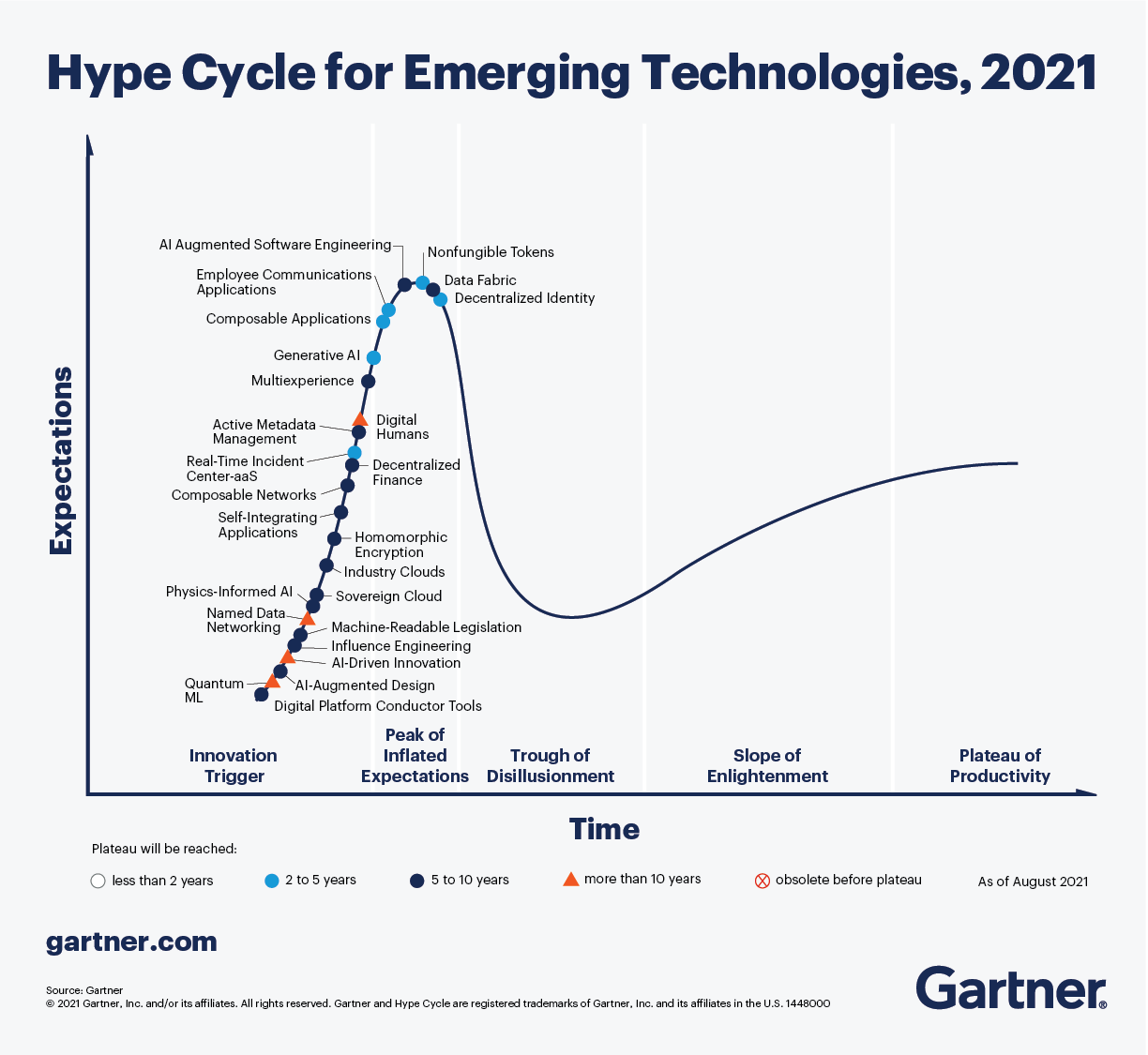
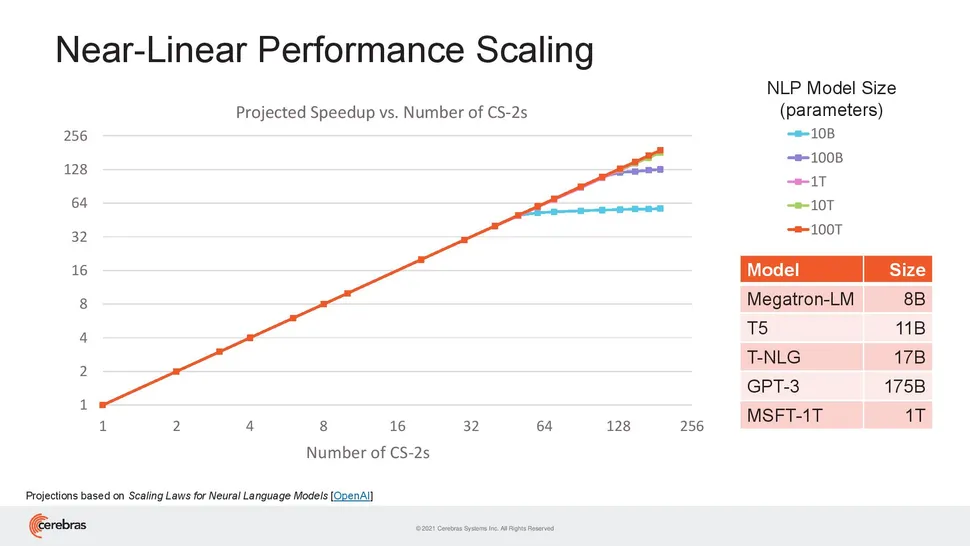
가트너의 2021년도 emerging technology hype cycle (8/24)세레브라스 시스템즈(Cerebras Systems), 인간 뇌 크기의 AI 모델을 구현할 수 있다는 시스템 개발 (8/25)
북한, 인공지능 기술로 금 가격 예측
[고학수 칼럼] ‘공정한 인공지능’의 어려움
20 QUIRKY AND INTERESTING MACHINE LEARNING INTERVIEW QUESTIONS
How to avoid machine learning pitfalls: a guide for academic researchers
|
|
드디어(?) 표절 사건이 터졌습니다...
같아봐야 얼마나 같을까요? ㅎㅎㅎㅎ (저 분 ECCV도.... 걍 상습범이신듯...?) |


|
또다른 Long-tail + Noisy label: Robust Long-Tailed Learning under Label Noise |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
News
Arxiv
On the opportunity and risks of foundation models
Weakly Supervised Continual Learning
Learning From Long-Tailed Data With Noisy Labels
Rethinking Why Intermediate-Task Fine-Tuning Works
A Survey on Automated Fact-Checking
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models
LocTex: Learning Data-Efficient Visual Representations from Localized Textual Supervision
The text was updated successfully, but these errors were encountered: