[20211121] Weekly AI ArXiv 만담 #30
Comments
|







|






|
Survival-oriented embeddings for improving accessibility to complex data structures
Arxiv: https://arxiv.org/pdf/2110.11303.pdf NeurIPS 2021 accept된 논문 공유해드립니다. 의료 인공지능 분야에서 딥러닝을 이용한 생존분석, 즉 어떤 현상이 언제 일어날 것인지에 대한 예측 관련 논문이 많이 연구되고 있는데 LMU Munich 영상의학과와 통계학과에서 liver tumor CT scan에서 영상을 직접 input으로 사용해 생존분석을 하는 방법을 제시했습니다. VAE를 사용해서 영상의 feature를 추출하는 역할을 수행하도록 하고 Cox loss를 조합해서 생존 확률 예측을 하도록 했는데 이는 기존의 딥러닝 기반의 생존분석 모델은 영상 정보로부터 end-to-end 예측을 하기 어려웠기 때문에 학습 안정화를 하는데에 크게 기여했다고 생각됩니다.
VAE의 latent vector를 보았을 때 실제로 tumor가 영향을 미치는 것으로 보입니다(?). 아쉬운 점은 영상 정보를 사용했음에도 불구하고 훨씬 단순한 tabular information을 사용한 방법과 성능이 크게 다르지 않다는 점입니다. 하지만 여전히 image data에서 survival prediction을 비교적 안정적으로 할 수 있는 방법을 제시해준다면 의의가 있다고 생각됩니다.
|



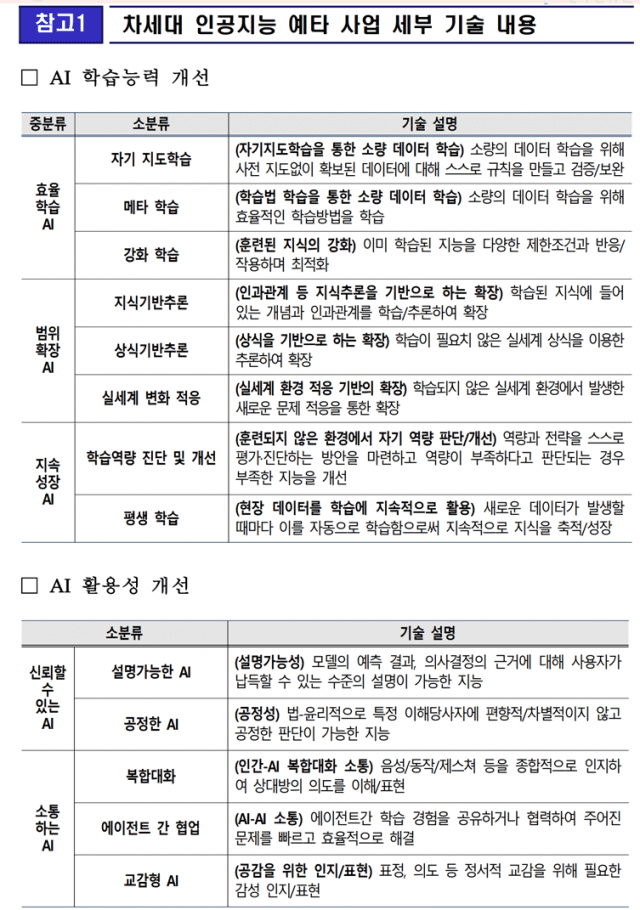
뷰노 이준형님 대한영상정보학회 Emphysema challenge 수상[단독] 정부가 ‘연구용’ 줬더니, 얼굴 영상 10만건 빼돌렸다https://www.hani.co.kr/arti/economy/it/1019612.html 차세대 인공지능 연구개발에 5년간 3천18억원 투입http://www.mtnews.net/news/view.php?idx=12233
기후 변화의 가공할 미래 위협...생성적 적대 신경망(GANs)이 잘 보여준다http://www.aitimes.com/news/articleView.html?idxno=141547
IEEE, 2022년 이후의 기술 impact에 대한 조사https://virtualizationreview.com/articles/2021/11/19/ieee-tech-study.aspx?m=1
Thanks to its AI system, Grammarly is now one of the most valuable US startups
|

Masked Autoencoders Are Scalable Vision Learners
Swin Transformer V2: Scaling Up Capacity and Resolution
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
Pre-training Graph Neural Network for Cross Domain Recommendation
November 2021 Edition: Rapid Advancements in Digital Transformation in Journal of Innovation (by AI미래포럼 임채성 위원님)
The text was updated successfully, but these errors were encountered: