API call latency regression #76579
Comments
|
/assign @oxddr |
|
@wojtek-t: GitHub didn't allow me to assign the following users: oxddr. Note that only kubernetes members and repo collaborators can be assigned and that issues/PRs can only have 10 assignees at the same time. In response to this:
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository. |
|
I'll have a look. |
|
I took a quick look into this one and looked into PRs merged between runs when it started failing: So I looked a a bit into graphs and my current hypothesis is that the regression actually happened before. This is based on looking into some graphs in perf-dash:
Both tend to suggest that the regression happened one run before (and we were just lucky in the first attempt after regression). |
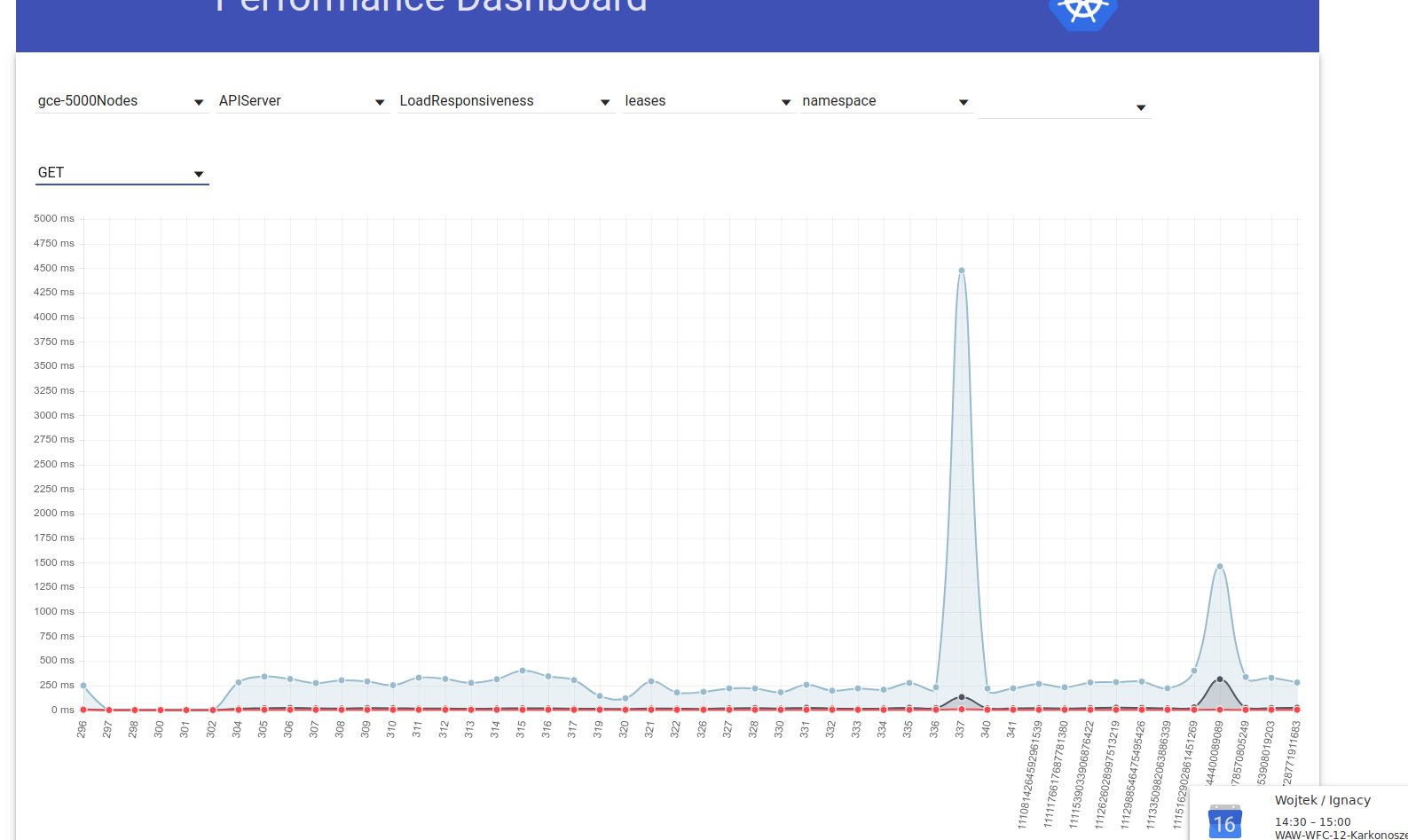
|
I took a look into those 93 PR merged in the period mentioned above. And there are exactly 6 that which impact I couldn't exclude immediately (though in most cases I highly doubt they may cause it): |
|
Last two runs have also failed density tests. Interestingly 5000 kubemark tests are passing just fine. I'll have a look at PR listed above and try to narrow down them down. |
|
At this point, we are still not sure, what is the last good commit. Assuming that the regression has happened before f873d2a and we may get lucky so that load test doesn't fail, the last good run may go back up to f6c51d6. Next steps:
|
|
The first re-run wasn't successful - master become unreachable, causing test to crash. I am going to re-run it again. |
|
Reverting commits from #76579 (comment) didn't help and load test has failed. I'll have a look at earliest commits then. |
|
In the meantime I am re-running tests at 51db0fe (another green run) to verify what was the last good run. I suspect the regression has happened earlier on and this was just a lucky run. |
|
I had problems with my machine and results from yesterdays run are lost. I am rerunning tests now. I am also having a look whether there are any traces of increased latency in smaller tests (ideally for 100 nodes cluster). Being able to run against smaller cluster will reduce feedback loop. |
|
I'm not convinced this is reflected in 100-node tests. That said, I tried to looked around if I can find something else around that time that regressed.
The increase is really visible there.
|

|
BTW, assuming I'm correct above, there are only 15 commits in that range: |
|
Obviously, assuming that it's not test-infra change or sth like that... |
|
I checked test-infra and there weren't any changes for our jobs in this period (we enabled prometheus stack in the previous run, but the last good one already had that). |
|
FYI: I am going to run kubemark tests now with 1cca3f9 revert to check whether it's culprit. |
|
1cca3f9 is the merge commit of a PR updating several dependencies (each in their own commit), and won't revert cleanly on master. If I had to pick a likely candidate, I would try reverting the golang.org/x/sys dependency to its previous version |
|
I see. Looking through the list of updated dependencies in that PR, only the golang.org/x/sys and golang.org/x/text seem likely possibilities for having any performance implications. If you wanted to try on master with the previous levels of those dependencies, you could do this: Note that the level of those dependencies we were previously on was ~18 months old and not in sync with go 1.12, so I'd be concerned about leaving those at those levels indefinitely. |
|
Thanks Jordan - although other PRs does seem to be suspicious, we should first try to prove that it's really this PR that caused regression. Once we know that for sure, we should find the exact commit and then think what do do with it. |
because that bump only changed a single line: func parseOpenSSHPrivateKey(key []byte) (crypto.PrivateKey, error) {
- magic := append([]byte("openssh-key-v1"), 0)
- if !bytes.Equal(magic, key[0:len(magic)]) {
+ const magic = "openssh-key-v1\x00"
+ if len(key) < len(magic) || string(key[:len(magic)]) != magic {
return nil, errors.New("ssh: invalid openssh private key format")
} |
|
got it - thanks makes a lot of sense now Unfortunately, I just realized, that the results when test run locally (those for kubemark-5000) will not really be comparable, because:
@oxddr So the fact that those will be higher doesn't mean anything - you need to compare the results relatively to other when running your test locally... |
|
I did a number of experiments over the weekend. As I also wrote above, I'm not entirely sure if it's a good thing to look, but it was easy to leave tests to run. Here are the results (below 50th, 90th and 99th percentile in microsecond):
The above seem to suggest that this is really the offending PR. So I did a bit more:
[The results look really similar to the bad ones]
And i have troubles with interpreting these results - lower 50th percentile in 3/6 attempt may suggest it's here, but it still looks visibly worse than b8b7ab3 But I will risk, and in the background will try to run tests with all golang.org deps reverted leving all others not-reverted (if the change is really in that second batch of reverted commits). |
It looks better, but that is likely due to the revert restoring the bug that artificially reports lower latencies at small sample sizes. I expect #77735 (which fixes that reporting bug) will likely shift those reported latencies higher again. Note that it is not regressing actual latency, just making the reported latency more accurate at small sample sizes. |
@liggitt - as you expected, the revert increased it again: But that proves that this is not a cause of regression, but the real bug. [Sorry for delay, I was OOO since Wednesday]
@dcbw - it's probably because we are not setting limits for kube-proxy in any setup, thus it may eat the whole memory on the machine. |
agreed. opened #77809 to restore the version prometheus expects to use |
Ref. kubernetes/kubernetes#76579 As the regression is cleary visible in the density tests, we'll disable the long taking (~10h) load tests and run the density tests more frequently until we make them pass.
Ref. kubernetes/kubernetes#76579 As the regression is cleary visible in the density tests, we'll disable the long taking (~10h) load tests and run the density tests more frequently until we make them pass.
Ref. kubernetes/kubernetes#76579 As the regression is cleary visible in the density tests, we'll disable the long taking (~10h) load tests and run the density tests more frequently until we make them pass.
|
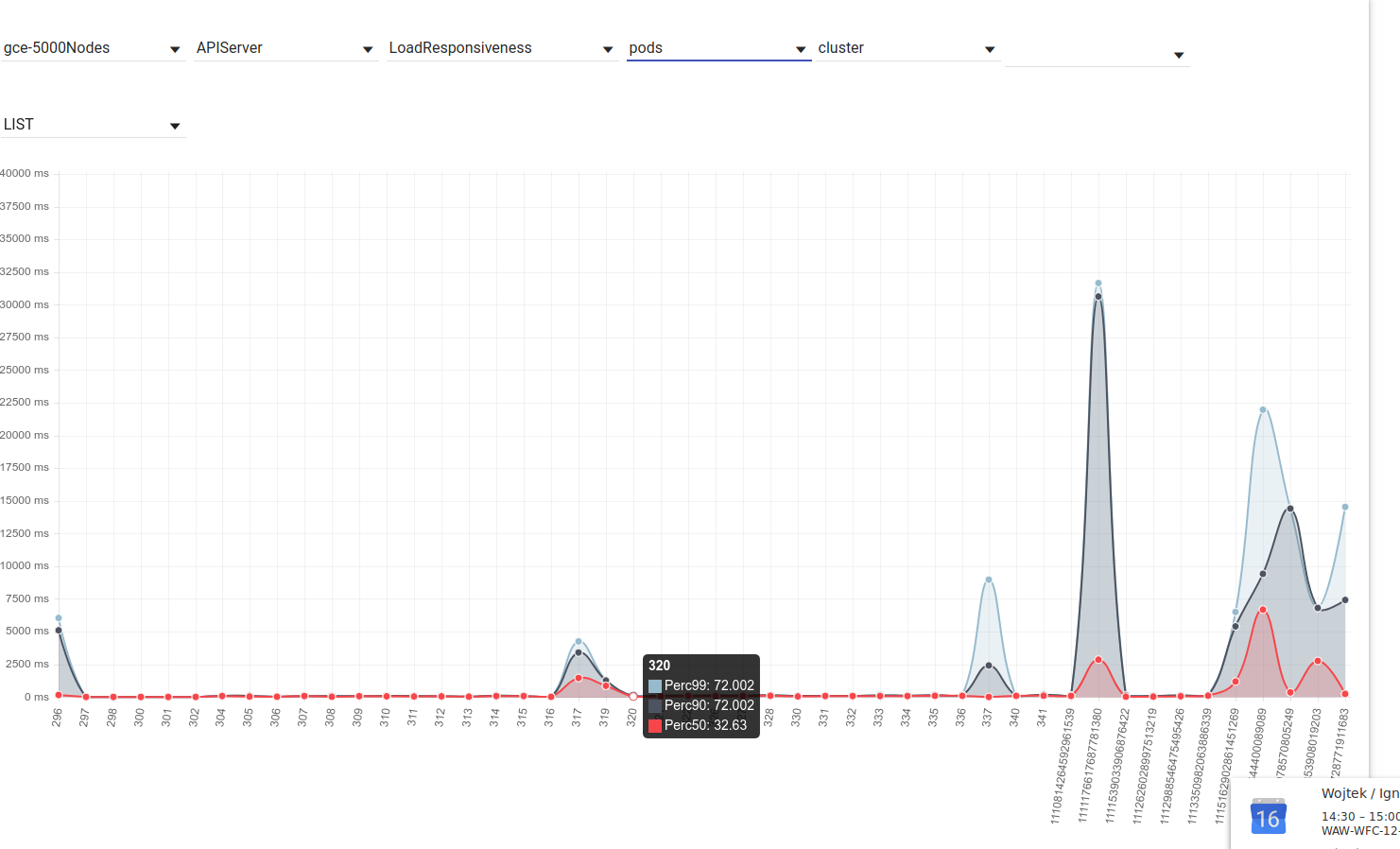
This is what we should focus on going forward probably: The latency of "LIST pods (scope=cluster)" latency was visibly increased. This may be related to the fact the the number of those calls were also increased. Understanding where are those coming from may help us understand the problem. @mborsz @mm4tt |
This is essentially reverting kubernetes/kubernetes#77224 in our gce 5000 performance tests. We believe it may be related to kubernetes/kubernetes#76579
|
Reg. kubernetes/test-infra#12686 and why we believe it may help with this regression (one of these regressions). We've noticed an increase in memory used by coredns between runs 328 and 329 This memory increases causes coredns to OOM (due to 170MB memory limit) which in turn has a negative impact on api latency (coredns gets restarted then lists all pods/endponts/etc.) We run two tests. One on the exactly the same configuration as run 330 and another with reverted #75149. 330 330 with reverted #75149 |



We've ruled out that the prometheus was a cause of the regressions a long time ago. Actually it helps a lot when debugging. The positive side effect of this change will be a mitigation of the faster MIG startup problem, in the end it will add an O(a few minutes) delay before running the tests. Ref. kubernetes/kubernetes#76579
|
I forked the CoreDNS problem to a separate issue: #78562 With that, this one can be closed. |
Ref. kubernetes/kubernetes#76579 As the regression is cleary visible in the density tests, we'll disable the long taking (~10h) load tests and run the density tests more frequently until we make them pass.
This is essentially reverting kubernetes/kubernetes#77224 in our gce 5000 performance tests. We believe it may be related to kubernetes/kubernetes#76579
We've ruled out that the prometheus was a cause of the regressions a long time ago. Actually it helps a lot when debugging. The positive side effect of this change will be a mitigation of the faster MIG startup problem, in the end it will add an O(a few minutes) delay before running the tests. Ref. kubernetes/kubernetes#76579
|
/cc |
There is yet another regression for API-call latencies for 5k-node test:
https://testgrid.k8s.io/sig-scalability-gce#gce-scale-performance
The last 3 runs of load test failed there.
I didn't yet have time to look into it deeper, but (especially the last run) seems suspicious, due to this one:
It seems some nodes were added during the test, which isn't expected.
@kubernetes/sig-scalability-bugs
The text was updated successfully, but these errors were encountered: