Unable to reproduce Fig 1A #2
Comments
|
I should note that I originally attempted to reproduce this work in Tensorflow here. However, after achieving similar results I wanted to sanity check that I could at least reproduce the results with the provided Caffe code. |
|
From the paper:
The current super-convergence/architectures/Resnet56Cifar.prototxt Lines 113 to 116 in 45330fd Are these correct? Are there any other changes to the network I should make before trying to reproduce? |
|
Josh, Thank you for your efforts at reproducing our results. I hoped it would be much simpler to do. You might take a look at the x.sh file. I created that shell script to make modifications to the files and submit them to our GPU system. It shows the change to moving_average_fraction from 0.999 to 0.95 for Figure 1. This script might answer some of your questions. Based on your comments, I plan to upload the output for a job that created the super-convergence run for Figure 1 (my server is currently down). That should help answer your questions and make reproducing the results easier. Thanks, |
|
@lnsmith54 Thanks! I'll take a look and I'll review the script in closer detail tomorrow. If I am able to reproduce after making these changes I'll be sure to make corresponding edits on OpenReview as well. I'll let you know how it goes. |
|
Josh, I've uploaded the output files to a new results folder. Please look at the clr3SS5kFig1a file for your reference. Good luck and I look forward to hearing how it goes. Leslie |
|
I think I'm getting much closer. After changing For CLR training with Caffe I get a final accuracy of 84%
For multistep training with Caffe I get a final accuracy of 91.5%
I'll diff your output files against mine and see if I'm missing anything else. |


|
Your CLR curve looks qualitatively similar to mine. It is my guess that running with 8 GPUs makes a major difference and you won't be able to reproduce the CLR results without similar hardware. Please prove me wrong! |
|
One difference I've noticed is: The super-convergence/Results/clr3SS5kFig1a Lines 144 to 156 in ecc5615 The super-convergence/architectures/Resnet56Cifar.prototxt Lines 68 to 92 in ecc5615 Should I be removing these params when reproducing? |
|
That is curious. The params should be there. My server has been down all week but when my server is fixed, I will rerun this example with the Resnet56Cifar.prototxt just to double check this. |
|
Sounds good. In the meantime, I've updated my reproducibility report with these stronger results. Thanks for your help! |
I'm trying to reproduce evidence of superconvergence in Figure 1A shown below:
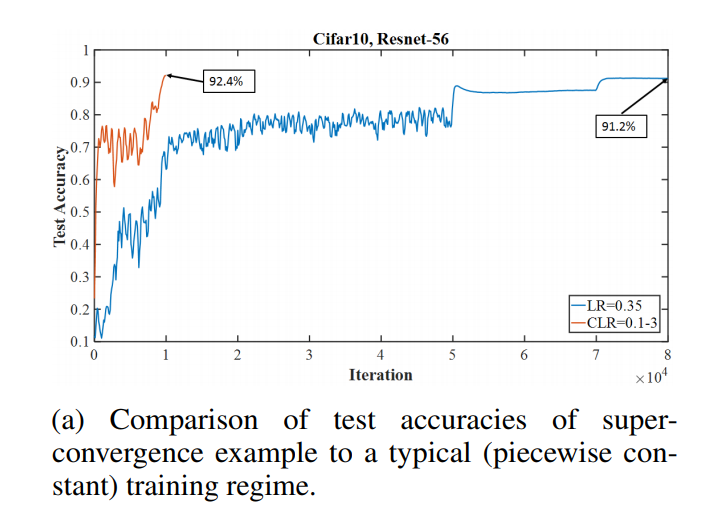
I am using the following values for the
solver.prototxtI have implemented
triangularcyclical learning in Caffe as specified here.I am using
Resnet56Cifar.prototxtas the network.I am achieving final training accuracy of ~90% but final test accuracy as low as 10-20%.
I note that the paper specifies that you achieve these results with large batch sizes of ~1,000 images. However, I wouldn't expect smaller batch sizes (125, as specified in
Resnet56Cifar.prototxt) to completely destroy the results.Are there any additional steps I must take to reproduce this work?
The text was updated successfully, but these errors were encountered: