You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
typeRaftstruct {
mu sync.RWMutex// Lock to protect shared access to this peer's statepeers []*labrpc.ClientEnd// RPC end points of all peerspersister*Persister// Object to hold this peer's persisted statemeint// this peer's index into peers[]deadint32// set by Kill()// Your data here (2A, 2B, 2C).// Look at the paper's Figure 2 for a description of what// state a Raft server must maintain.currentTermintvotedForintlogs []LogEntry// Volatile state on all serverscommitIndexintlastAppliedint// Volatile state on leadersnextIndex []intmatchIndex []intvoteCountintstateuint64grantedchanstruct{}
AppendEntrieschanstruct{}
electWinchanstruct{}
applyChchanApplyMsg
}
Raft 实现(MIT6.824 Lab)
Background
本篇是基于MIT6.824课后实践实现的一个简单Raft,包括三个部分:Leader选举,日志复制,持久化。整篇的核心在raft paper里面的figure2中,这张图可以直接理解为编程语言了,是整个raft的核心。
Leader选举
状态机
Leader选举的概念状态机再重新贴一下:
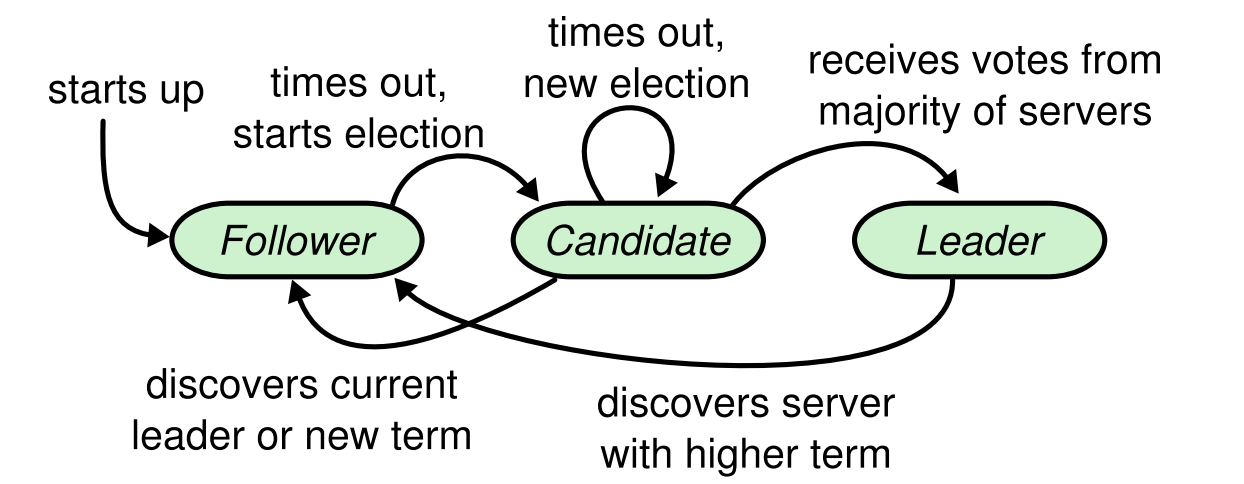
先理清楚两个timeout:electionTimeout以及heartbeatTimeout。
状态机的变化对照figure 2即可进行转化,这里我们只关注leader选举的部分。
Follower:
Candidate:
Leader:
Raft 结构体:
状态机里面的electionTimout设置为随机值是为了避免选举 split vote 情况。
为了调式方便,写了一个带时间戳的Log,输出的日志看的比较方便
投票请求 RequestVote
RequestVote接口是发起投票用的RPC接口,只能由candidate发起。默认理解为每个Raft 集群的Node上都会这么一个接口用来接收candidate发起的投票请求。
Candidate给其他节点发送请求,处理response也在这个函数里面。
sendRequestVote里面加入了RPC的timeout,是因为测试用例里面会模拟网络不可达的情况,如果一个请求一直hang下去,系统会更加复杂。虽然paper上说的是可以无限重试,但是实际生产环境中外部RPC调用都是需要加上一个timeout来保护资源泄漏。
心跳维持 AppendEntries
心跳包的维持是每隔一段时间(heartbeat timeout)去发送的,函数名为AppendEntries,因为log之后的数据每次同步也都是在这里面发送的。
Leader在发送RPC请求的时候也需要带上一个timeout,这样方便控制整个流程。
被调用方收到的请求处理流程
日志复制
日志复制应该算是整个Lab里面最复杂的一部分,先简单回顾下paper内容。
相较于leader选举,根据figure2可以知道会增加几个变量,先解释几个参数的意义:
Log可以定义为
[]LogEntry, 里面的command是Lab所需要的,这么一来Log的定义就完成了。RequestVoteArgs 里面会新增LastLogIndex和LastLogTerm,用来判断当前leader是否是最新的。
另外RequestAppendEntriesArgs里面也有所改变
PrevLogIndex对应的Leader中的nextIndex数组减去一,PrevLogTerm同理。
接受写请求 Start
这里唯一需要注意的一点就是Lab与raft paper不同,每次是直接在append之后就返回,没有等待其他Leader的append。
Log发送 AppendEntries
相较于上次的Leader选举,新的AppendEntries会去同步日志,主要需要构建 PrevLogIndex以及Entries,Entries为空的话发送一个心跳包即可。
在看具体发送逻辑, 在每次成功响应后都会去提交日志, 更新Leader本地的
rf.nextIndex以及rf.matchIndex。RetryIndex是用来优化的一个点,下个函数会讲到。Commit的逻辑也很简单,遍历peers,如果超过半数以上的matchIndex都等于当前Leader Log的结尾,则认为这是一次有效的Append,进行提交。
接受方的逻辑,使用retry index进行优化,当收到的request是有效之后,覆盖有冲突的Logs,直接从
rf.logs[:args.PrevLogIndex+1]开始,然后进行提交。持久化
根据Paper的内容,需要持久化的内容有三个:

currentterm,votedFor,log[]这就意味着每次当raft结构体内上诉三个变量发生改变的时候我们都需要将其持久化。persisth和readPersist都很简单。
至于Persist调用的地方只要完成了前面两个实现,添加也很简单,这里就不再贴代码了。
小结
在调测试的时候其实是很懵的,需要仔细看看测试代里面的内容,然后在调试的时候带上时间戳以及当前节点的信息,这样看起来就会容易许多。实现部分的代码其实没有多少,最精华的部分应该是这部分的测试代码,从模拟分区再到split over,再到节点的网络失效,有兴趣的可以仔细看下实现。
reference
The text was updated successfully, but these errors were encountered: