Building Scalable Consumers 🍽
Table Of Contents
- Consumer: How It Works?
- Batching Message Consumption
- Committing Messages
- Java Consumer Options Example
- Multi-threaded Consumers
Kafka consumers are typically part of consumer groups, each consumer group has a group coordinator associated with it.
- The group coordinator is a Kafka broker in the same Kafka cluster. The controller designate a group coordinator when a new consumer group is used to access Kafka.
- It keeps track of all the active consumers in the consumer group.
- It receives heartbeats from the consumer. When a consumer connects to Kafka, it established this heartbeat with the corresponding group coordinator. When the heartbeat stops, the coordinator senses that the consumer has done and proceeds to trigger re-balancing of the partitions among other consumers in the same consumer group. Similarly, when a new consumer is added to the group, re-balancing is triggered.
Each consumer group has a consumer leader.
- A consumer leader is
- A consumer in the same consumer group.
- The first consumer to join the group.
- It receives information about all the other consumers in the group through the group coordinator.
- It is responsible for assigning partitions to all consumers in the group.
- It works with the group coordinator for re-balancing. When the group coordinator sees a new consumer being added or an existing consumer going down, it requests the group leader for reallocation of partitions. This is then propagated to the individual consumers and they start listening on that new set of assigned partitions.
- When the group coordinator or the group leader themselves go down, that responsibility is transferred to other brokers and consumers in the group respectively.
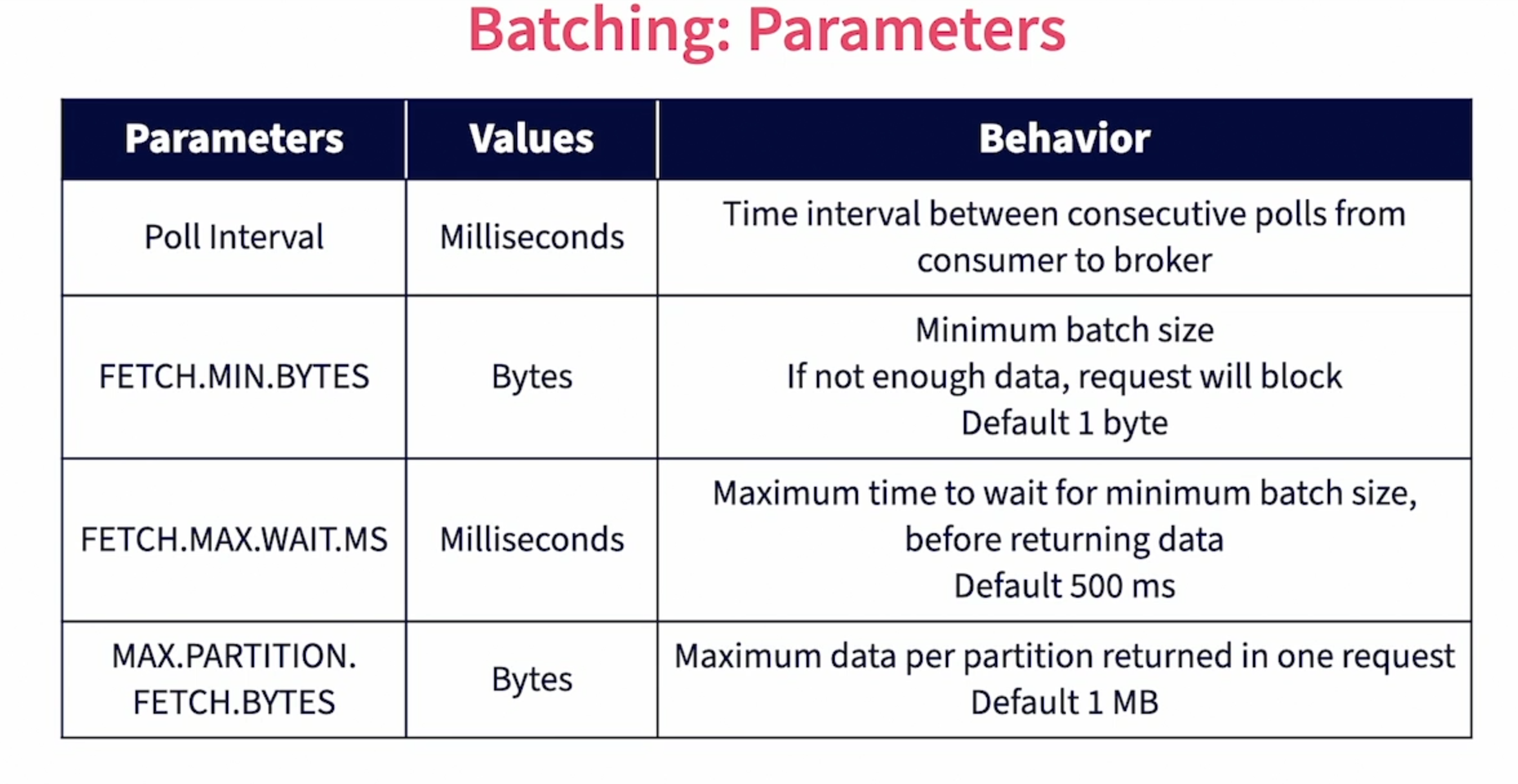
- Consumers Poll Kafka periodically for new messages. The poll interval is configurable through the poll method.
- Each consumer is allocated a set of partitions to work with. Consumers poll corresponding partition leaders for new messages.
- When a consumer poll, a batch of messages are returned from Kafka when new messages are available. The bigger the batch sizes and higher the poll interval, the lower of the round trips and request overloads (Batching helps optimize network round-trips).
- Large sizes and poll intervals directly impact the latency of processing.
- It is required to choose the right parameters (based on the use case) to balance between round-trips and latency.
( Source [1] )
Please refer to the official documentation available at https://kafka.apache.org/documentation/#consumerconfigs for more information
By default, consumers are configured to auto commit messages on receipt. When a message is committed by a consumer in a consumer group, Kafka marks that this message has been delivered to this consumer group and does not send the message again to a consumer in the same consumer group. It is controlled by 02 parameters :
enable.auto.commit ( true ) : Determines if it is automatically committed on receipt or the consumer needs to manually commit. By default this is set to true.
auto.commit.interval.ms ( 5000 ) : Determines the interval at which the consumer auto commits messages. The default is 5000 milliseconds. If the consumer commits on receiving messages, it does not guarantee that the consumer has successfully processed the message as the processing may involve a number of steps on the consumer side based on the use case. If the consumer dies after auto committing a message and before processing , the message will never be received again by a consumer in this group so it will never be processed.
Manual committing of a message after successfully processing would mean that if the consumer does go down after committing the message, the message would again be delivered to a consumer in this consumer group and will get a chance to be processed again. Handling duplicates in much easier than handling missed events.
Determine if auto or manual commit is needed based on the use case.
There are 02 options available : Synchronous and Asynchronous.
- It Is done by calling the commitSync method on consumer.
- It is done after processing every batch after all messages in the batch are processed.
- The thread is blocked until all commits are successfully performed by the brokers.
- It Is done by calling the commitAsync method on consumer.
- Commits happen in a separate thread and do not block the main thread. This method can have an optional callback to handle any errors.
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class KafkaConsumerWithOptions {
public static void main(String[] args) {
//Setup Properties for consumer
Properties kafkaProps = new Properties();
//List of Kafka brokers to connect to
kafkaProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"localhost:9092,localhost:9093,localhost:9094");
//Deserializer class to convert Keys from Byte Array to String
kafkaProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
//Deserializer class to convert Messages from Byte Array to String
kafkaProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
//Consumer Group ID for this consumer
kafkaProps.put(ConsumerConfig.GROUP_ID_CONFIG,
"kafka-options-consumer");
//Set to consume from the earliest message, on start when no offset is
//available in Kafka
kafkaProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,
"earliest");
/**********************************************************************
* Set Batching Parameters
**********************************************************************/
//Set min bytes to 10 bytes
kafkaProps.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG, 10);
//Set max wait timeout to 100 ms
kafkaProps.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG, 100);
//Set max fetch size per partition to 1 KB. Note that this will depend on total
//memory available to the process
kafkaProps.put(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG, 1024 );
/**********************************************************************
* Set Autocommit Parameters
**********************************************************************/
//Set auto commit to false
kafkaProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
//Create a Consumer
KafkaConsumer<String, String> simpleConsumer =
new KafkaConsumer<String, String>(kafkaProps);
//Subscribe to the kafka.learning.orders topic
simpleConsumer.subscribe(Arrays.asList("kafka.learning.orders"));
//Continuously poll for new messages
while(true) {
//Poll with timeout of 100 milli seconds
ConsumerRecords<String, String> messages =
simpleConsumer.poll(Duration.ofMillis(100));
//Print batch of records consumed
for (ConsumerRecord<String, String> message : messages) {
System.out.println("Message fetched : " + message);
//Sleep for 1 second
try {
Thread.sleep(1000);
}
catch(Exception e){
e.printStackTrace();
}
}
/**********************************************************************
* Do Manual commit asynchronously
**********************************************************************/
//Commit Async
// This is an asynchronous call and will not block.
// Any errors encountered are either passed to the callback (if provided) or discarded.
// For each iteration in the for-loop, no matter what will happen to simpleConsumer.commitAsync() eventually,
// the code will move to the next iteration.
// The result of the commit is going to be handled by the callback function you defined (if any).
simpleConsumer.commitAsync();
}
}
}Note to myself
- For God's sake, consider horizontal scaling as defined in The Twelve Factor App Methodology 🔥
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
public class ScalableConsumer {
public static void main(String[] args) {
//Setup Properties for consumer
Properties kafkaProps = new Properties();
//List of Kafka brokers to connect to
kafkaProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"localhost:9092,localhost:9093,localhost:9094");
//Deserializer class to convert Keys from Byte Array to String
kafkaProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
//Deserializer class to convert Messages from Byte Array to String
kafkaProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
//Consumer Group ID for this consumer
kafkaProps.put(ConsumerConfig.GROUP_ID_CONFIG,
"kafka-scalable-consumer");
//Set to consume from the earliest message, on start when no offset is
//available in Kafka
kafkaProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,
"earliest");
//Set auto commit to false
kafkaProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
//Create a Consumer
KafkaConsumer<String, String> simpleConsumer =
new KafkaConsumer<String, String>(kafkaProps);
//Subscribe to the kafka.learning.orders topic
simpleConsumer.subscribe(Arrays.asList("kafka.learning.orders"));
//Create a Thread Pool of workers
System.out.println("Starting worker threads for parallel processing");
List<SampleWorker> workerList = new ArrayList<SampleWorker>();
//create 5 worker threads
for (int i=0 ;i< 5; i++) {
SampleWorker worker = new SampleWorker("Worker_" + i);
Thread newThread = new Thread(worker);
newThread.start();
workerList.add(worker);
}
//Continuously poll for new messages
while(true) {
//Poll with timeout of 1 second
ConsumerRecords<String, String> messages =
simpleConsumer.poll(Duration.ofMillis(1000));
//Print batch of records consumed
for (ConsumerRecord<String, String> message : messages) {
System.out.println("Message fetched : " + message);
//Add to Queue
SampleWorker.addToQueue(message.value());
}
//Wait for processing to complete across threads
while( SampleWorker.getPendingCount() > 0) {
try {
Thread.sleep(100);
System.out.println("MAIN: Waiting for Processing to complete...");
}
catch(Exception e) {
e.printStackTrace();
}
}
//Commit messages manually now.
simpleConsumer.commitAsync();
System.out.println("All messages successfully processed. Proceeding to poll more");
}
}
}import com.yammer.metrics.stats.Sample;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;
public class SampleWorker implements Runnable {
private static BlockingQueue<String> requestQueue
= new ArrayBlockingQueue<String>(100);
private static final AtomicInteger pendingItems = new AtomicInteger();
private String workerId;
public SampleWorker(String workerId) {
super();
System.out.println("Creating worker for " + workerId);
this.workerId =workerId;
}
public static void addToQueue(String order) {
pendingItems.incrementAndGet();
try {
requestQueue.put(order);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static int getPendingCount() {
return pendingItems.get();
}
@Override
public void run() {
while(true) {
try {
String order = requestQueue.take();
System.out.println("Worker " + workerId
+ " Processing : " + order);
//Do all required processing
Thread.sleep(100);
//After all processing is done
pendingItems.decrementAndGet();
}
catch(Exception e) {
e.printStackTrace();
}
}
}
}© 2024 | Lyes Sefiane ![]()
![]() All Rights Reserved | CC BY-NC-ND 4.0
All Rights Reserved | CC BY-NC-ND 4.0
