Developing_micro agent_applications
To develop own micro-agent applications you first should be familiar with basic micro-agent concepts which will be introduced before providing code examples. The code examples of this section assume that you have an installed version of µ² as described in Getting started. The comprehensive example code can be found here.
Micro-agents rely on a simple meta-model which is shown in the following figure and explained afterwards.

Core concepts are thus micro-agents (or agents at this point) and roles. The model identifies three role specializations:
- Social Roles - They involve in fast asynchronous communication and are the conceptually more powerful type of roles.
- Passive Roles - They use synchronous communication and reside on the lowest level of agent applications. They are useful to avoid any performance penalty in contrast to object-oriented programming (i.e. have similar performance than method calls in conventional object-oriented applications).
- Groups - Groups are means to allow organisational structures in agent applications. µ² chooses a hierarchical approach of groups to model and manage agent applications which allows the 'modelling of agents from agents'. Agents are in at least one group relationship. They are member of the group of their super-agent and may be owner of an own group which itself can have group members which can have groups themselves and so on. The agent organisation peaks in the SystemOwner agent which resides at the highest level and is the only agent to own his owning group. Its use is essentially to integrate the whole agent organisation and issuing of platform management commands (e.g. shutdown).
The following figure shows the organisational principle in µ².
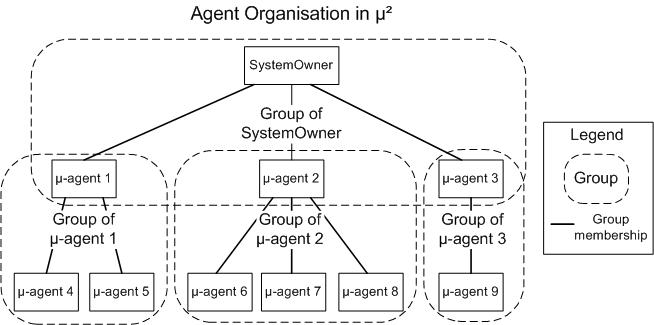
In contrast to conventional agents micro-agents are strongly efficiency-oriented and minimize any performance penalty in contrast to object-oriented development. This is reflected in the different role types and the organisation principle. The organisation principle is only possible because of the high performance of individual agents. This generates the potential to model applications in a fully agent-oriented manner on every level. The different role types (passive and social) support a demand-oriented specialization of agents on different levels.
Given this background understanding the actual micro-agents are functionality containers which provide capabilities to roles and manage the organisational relationships to other agents. Application development in µ² thus mainly involves role implementations and the modelling of agent organisations by defining super- and sub-agents.
Simply create a new Java class with a name of your choice. To bear in mind that you model roles, not agents (agents can have multiple roles), you could append the suffix 'Role' to the name to clarify this.
The figure below shows the social role 'SimpleSocialClientRole'. For social roles simply extend the 'DefaultSocialRole'. Eclipse (or Java itself upon compilation) will then enforce the creation of three method implementations necessary for social roles as shown in the figure below.

The initialize() method holds any code which needs to be executed when the role is initialized (i.e. actually played by an agent). Examples for this include 'Applicable Intents' which can be registered for roles to allow the dynamic binding of role functionality. However, the developer can add any code useful for his application.
The handleMessage() method is the key method for a social role implementation (it does not exist in passive roles). Incoming messages are delivered via this method and need to be processed by subsequent code. Mechanism to support the message-based functionality decomposition (especially Message filters) will be discussed at a later stage. A message (respectively message container) itself, in specific the MicroMessage, is essentially a hash map with various predefined getters and setters (such as setRecipient(), setIntent()). For more detailed information see its dedicated page.
The release() method is executed when the role is released respectively no longer played by an agent. All necessary cleanup code should be put in this method.
Apart from those mandatory method implementations in social roles the developer can add arbitrary further methods for other purposes (e.g. to initiate agent interaction).
Passive roles are created similarly to social roles. Only difference is that they extends the 'DefaultPassiveRole' which enforces a structure as shown in the following figure.

Key difference to social roles is the lacking handleMessage() method. The other methods have the same purpose as with social roles.
In order to decide when to use social or passive roles simply determine whether you need
- non-blocking asynchronous communication,
- an explicit message container,
- interaction with remote agents or
- event subscriptions.
If you need one of those features you should use social roles. In fact in most cases you will use social roles for core application functionality and augment those with passive roles to contribute minor and typically very simplistic short-running logic-centric functionality which might be used by multiple agents (e.g. stateless calculation algorithm). Most of the following explanations will only apply to social roles. The dynamic binding with passive roles will be explained explicitly to contrast the dynamic binding for social roles.
Key mechanisms for the loose coupling of agent-based communication are intents. Intents are abstract statically typed request specifications which are used for dynamic binding of agent functionality. To allow agent interaction based on intents roles (which are played by agents) need to register 'Applicable Intents'. The roles satisfying those registered intent types will receive according requests.
Intent implementations need to implement the Intent interface provided with µ². Intents can include arbitrary Java functionality - as only sender and receiver of intents need to be able to interpret the content it can range from properties to method implementations. The following figure shows an intent for a simple addition operation. This intent does not only include the necessary summands but also the operation to calculate the results. Again, the content of an intent is fully application-dependent and may or may not include operations and/or state.

Applicable intents are typically registered once a role is initialized. The registration should thus be placed in the initialize() method of the service provider's role implementation (the example role is named ServiceProviderRole). Along with the registration it needs to provide mechanisms to actually deal with the request. Requests in social roles will be received via messages, thus needs to be handled in the handleMessage() method. An example implementation is shown below (The code could be more condensed but done in a step by step manner for the sake of understanding). The code includes comments for further explanation.

A service requester (here named ServiceRequesterRole) can send an according request and expect a result or an error message from the platform if his intent request cannot be satisfied. An example implementation of the requester role is shown below. It includes an extra method to initiate the interaction (startInteraction()). Its handleMessage() method processes received messages and extracts the result of its sent request.

Yet all role implementations are defined but the initialization code is yet missing. In a typical agent application the initialization would be done in the main() method. The SystemAgentLoader is responsible for initializing roles on micro-agents. The SystemAgentLoader offers a wide range of initialization options (see the static methods of SystemAgentLoader). In most cases role implementations will be initialized as shown in the figure.
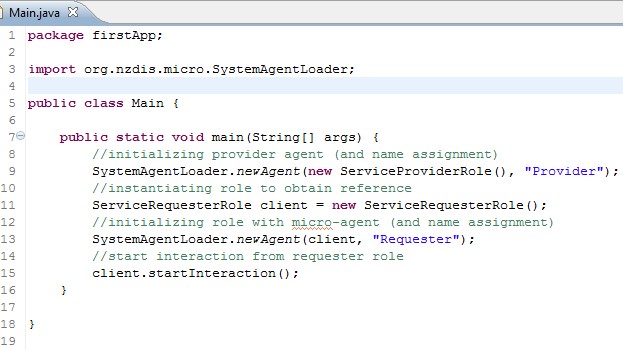
The specification of a name for the instantiated agent is optional. If not provided the platform will automatically assign a name. However, if you rely on intent-based dynamic binding agent names are hardly of concern (though helpful in the case of real-time debugging).
When running this simple example the console output of Eclipse should show something similar to this....

This example shows the loose coupling functionality of µ² along with the large degree of freedom of the developer to define the intents. By relying on Java's casting mechanisms role implementations can distinguish multiple registered applicable intents. The number of registered applicable intents for a given role is not restricted.
In the case of multiple initialized roles being able to fulfill a particular request the platform simple forwards the request the first one found in the registry to minimize the internal registry lookup time. However, depending on duration and load of request processing this might not be optimal for larger systems. Future versions will introduce different configurable dynamic binding strategies.
Taking the example used in the context of social roles the equivalent operation with passive roles will be described at this point. It is significantly simpler and only involves synchronous execution. However, the memory overhead is very low (typically it does not even start the platform itself) and (compared to social roles lower degree of) loose coupling is still maintained.
The service provider role for this example (see figure below) does not have the handleMessage() method and thus implements a dedicated (and freely defined method which handles the according applicable intent and returns the result of the processing. The registration of the applicable intent is not necessary but potentially useful for documentation purposes (or in case of refining a passive role to a social role at a later stage).
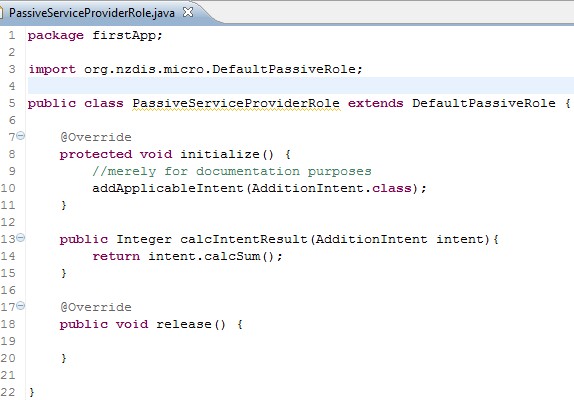
The custom method to process intent requests limits the degree of loose coupling as the requester needs to have a certain degree of knowledge about the role itself (and know what role type can satisfy its request (i.e. role class name)). The next figure shows the passive service requester role.

In fact the dynamic binding is completely undertaken by the developer (in the method startInteraction()) as he needs to have the knowledge about provider role internals and write the actual code (line 17/18). It also clarifies the blocking nature of this call. The result of this call is immediately printed. This shows that passive roles are only useful for rather short-running requests. However, although the developer needs to know a great deal of detail about the service provide the actual service provider (there could be multiple service provider running) is not known at compile time. This retains a more loose binding between the roles than the case for conventional object-oriented programming (but certainly by far less loose as for social roles) without significant performance penalty. This makes the use of agent-based concepts to the lowest implementation levels possible without switching to the conventional object-oriented thinking.
The initialization method is in complete analogy compared to the one for social roles.

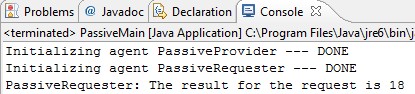
The result is the same but (although not discussed) the output is restricted to three lines. The actual platform (the earlier result output included some lines indicating the platform start (discussed later)) has not been started to perform this operation which explains the significantly lower footprint of passive roles.
The use of dynamic binding is recommended for the agent communication to provide a strong degree of loose binding. For social roles µ² alternatively provides various addressing patterns to model agent interaction if more suitable than intent-based communication (such as in simulations). Unlike intent-based messages the addressing patterns allow content-independent message dispatch. As agents can potentially play multiple roles the use of addressing patterns will result in messages which are received by all roles played by an agent. In the context of dynamic binding social roles can be distinctly addressed as of their registered applicable intents - this does not apply when using the addressing patterns. Please take this into account when using addressing patterns.
With Unicasts agents are directly addressed by name. To achieve this specify the recipient of a message using the setRecipient() method. An example for this is shown below.

Broadcasts address all active agents on the platform, or, in the case of Global Broadcasts all active agents on all connected platforms (via network connections).
For broadcast:
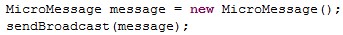
For global broadcast:
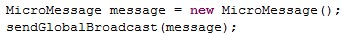
Rolecasts allow addressing of distinct played roles. The method parameter set involves message, role instance and indicator if it should be dispatched globally (i.e. across all connected platforms). However, although roles are specified using a role instance the matching is done on class level (e.g. the example below sends the message to all instances of the ServiceProviderRole).

Groupcasts address all agents inside a specified group.

Groups can be determined by arbitrary mechanisms, e.g. by role-based retrieval ((SystemAgentLoader.findRoles(ServiceProviderRole.class)[0]).getAgent().getGroup()).
Randomcasts allow the addressing of random agents on a platform or across all connected platforms. Additionally it allows the exclusions of specified agents. This functionality is particularly useful where randomization is of importance such as experiments. The Randomcast uses a MersenneTwister implementation for randomization and such allows an equally distributed randomization.
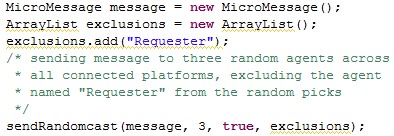
Customcasts represent the combination of many of the above-mentioned addressing patterns and target case in which one of the previous patterns does not satisfy the demands. The Customcast represents an 'AND'-combination which can result in agents being addressed multiple times (e.g. if belonging to specified role and specified group). Future developments target a refinement of those addressing ambiguities.
Parameters for the Customcast (method sendCustomcast()) are described (in the order of use) at this point:
- Message
- Target Group
- Target Role
- Number of random agents
- List of agents which are excluded from random addressing
- Indicator for local broadcast (all agents on local platform)
- Indicator for global broadcast (all agents on all connected platforms)
The event subscription mechanism is similar to the intent-based dynamic binding. Events extend the abstract Event class. In contrast to intents (which is are implementations of a Java interface) a constructor indicating the source of an event - in shape of an agent name - is enforced. The rest of the implementation is up to the developer and can include any Java class elements.
If not using system events (some of which will be described later) the developer needs to implement the according event. An example class called InterestingEvent is shown below.

Subscription to an event is done using the subscribe() method - as shown below for the InterestingEvent. This is most often done upon initialization of a role but can happen at any time of an agent's life cycle.

Events are raised by sending an event instance using the message transport mechanism. The example introduces a custom method (throwEvent()) for this purpose. However, it can be done anywhere in the role implementation.

The actual initialization code (in the main method) for this example is in analogy to the dynamic binding described before.

As a result it simply outputs the object's hashcode in the console, apart from the agent initialization.

As indicated the platform also raises system events. At the current stage those include:
- AgentActivatedEvent - Event when new agent is started
- AgentSuspendedEvent - Event when agent has been suspended
- AgentDyingEvent - Event when agent is dying
- LocalPlatformShutdownEvent - Event raised when local platform is shut down.
- RemotePlatformChangePropagationEvent - Event indicating the propagation of changed agent information by another platform (e.g. new agent started on remote platform)
- RemotePlatformConnectedEvent - Event indicating that a remote platform has connected to the local one.
- RemotePlatformDisconnectedEvent - Event indicating that a remote platform has disconnected.
- RemotePlatformShutdownEvent - Event indicating the shutdown of a remote platform.
- RemotePlatformSynchronizedEvent - Event indicating the a remote platform directory is synchronized with the local one.
Agents can freely subscribe to those events. Events in general represent yet the only plug-in-like mechanism (e.g. react upon agent registration or connected remote platform) to allow developers to add platform functionality.
Clojure as role implementation language
Apart from the principle of developing roles the other core feature is the agent organisation in µ². The agent organisation, enabled by the notion of sub-agents can be specified using the AgentLoader and MessageFilter both of which are described in the following.
Every agent on µ² contains an AgentLoader. AgentLoader allow the instantiation of agents from a given context. From an organisational perspective the newly instantiated agents are sub-agents of the agent which loads those. One example is the SystemAgentLoader. This loader operates in the context of the SystemOwner, the peak of the agent organisation in µ². All agents loaded via SystemAgentLoader are sub-agents of the SystemOwner. Agents loaded via the SystemAgentLoader represent the highest organisational level for developed agents. In analogy sub-agents can be loaded by resolving an agent's AgentLoader and loading sub-agents using the same methods provided with the SystemAgentLoader. The code example below shows the initialization of three agent levels (excluding the SystemOwner agent - which always resides on the highest level). It will be explained in detail.

The scenario deals with four agents (with a dedicated role implementation for each one). The only agent initialized by SystemAgentLoader is playing the SuperAgentRole. Two agent's are loaded as sub-agents, SubAgentRole1 and SubAgentRole2. The use of an AgentLoader returns an AgentController instance which allows the control of an agent's life cycle but also the retrieval of a direct reference to the agent (via getAgent()). As a next step an agent's group (his sub-group) is retrieved (getGroup()). If not existing it will be created at this point (via lazy instantiation). An agent's group holds the AgentLoader reference (getAgentLoader()) which offers the same methods as the SystemAgentLoader to instantiate sub-agents with given roles (e.g. newAgent()). Thus both the agent playing SubAgentRole1 and SubAgentRole2 are running on the same level. As a last step, to show the unlimited specification of levels a further agent (playing the SubSubAgentRole1 is loaded as sub-agent to the agent playing SubAgentRole2. Talking about roles, this example shows the initialization of agents without specified names (as an alternative to the code snippets shown earlier). All initialized agents automatically receive the name prefix 'AnonymousAgent' with an incremented number to allow unambiguous identification (i.e. AnonymousAgent1, AnonymousAgent2 and so on).
The mechanism of AgentLoaders allows the organisation of agents playing arbitrary role types (social and passive). However, it does not specify internal semantics; how those agents interact and how they decompose functionality is not of concern. If the specification of decomposition is of concern and only social roles are used MessageFilter can be more appropriate to allow Agent Organisation. However, both mechanism can be used in conjunction (e.g. to append passive roles to message filters on the lowest level of agent organisation for a given application).
MessageFilters serve as an alternative to agent initialization via AgentLoader. They only apply for social roles but allow an effective decomposition by means of messages. Implementations can be done using regular Java classes or inner classes.
To do this agent instances provide the method addMessageFilter() which allows the specification of a MessageFilter (role) and initializes it on a sub-agent of the according agent.
MessageFilter's only use is in fact the matching of incoming messages against patterns. A pattern itself is thereby specified as a MicroMessage instance (e.g. Sender: "Agent1", Content: "Data"). However, the matching can be done in two approaches. The class DefaultMessageFilter provides a validation based on simple full String matching. The abstract class MessageFilter allows the implementation of a custom validation function for matching messages which gives the developer more flexibility.
At this place decomposition using the DefaultMessageFilter class is shown. For this purpose the role implementation from the previous organisation example is taken:
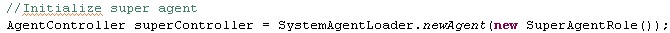
In fact the message filter is a role, in particular an extension to the social role which is reflected in his structure. One option is to define a message filter as inner class. A full example for this approach is shown below. It implements a filter on all incoming messages with the "REQUEST" performative (the constructor new MicroMessage("REQUEST") effectively calls setPerformative("REQUEST")).

As indicated before this message filter is automatically initialized as sub-agent for the micro-agent to which it is added (in this case the agent playing the SuperAgentRole). Message filter allow actions upon successful matching (onMatchSuccess()) as well as failed matching (onMatchFail()).
This approach allows cascading to an arbitrary depth by initializing further message filters in the initializeMessageFilter() method. A full example extending the previous example with a second level is shown below. On the second level (after the first message filter check) all messages from agent "AgentA" are caught to be processed by the according message filter.

Bearing the concepts of levels in mind this simple example shows the decomposition of functionality based on incoming messages to an arbitrary level.
Using inner classes, as shown those two listings, the agent functionality can be clearly structured but still be maintained in a single file.
However, the implementation in a regular class file extending the (Default)MessageFilter and its instantiation using addMessageFilter() is equally possible. The prototypical initialization is shown below.

With regards to the pattern please bear in mind that the DefaultMessageFilter checks on existing and equal values for all specified fields. The pattern message can thus be arbitrary complex.
In contrast, the MessageFilter merely demands for the implementation of the validateMessage() function which provides the incoming message as well as the specified pattern as parameters and expects a boolean return value. True indicates the successful match of the incoming message against the pattern. An implementation stub for a custom message filter is shown below.

Overall, message filters are a more functionality-oriented way of decomposition than the explicit specification of organisation with the AgentLoader which does not deal with the functional aspects of decomposition. However, if passive roles are involved the use of AgentLoader cannot be avoided. But still both mechanisms can be used at the same time. The developer does not need to exclusively commit to either one approach.
Along with the development of local agent applications the platform allows the distributed use. In distributed mode all the functionality mentioned before is available across platform instances connected via network. The network connection is TCP-based. The port on which a platform is listening for new connections can be specified in the configuration (see later).
In order to facilitate the use across platforms, connected platforms share their directory of registered agent entities which makes increases the lookup performance for a specified agent name.
Connections are thus established in two steps:
- Establishment of connection via TCP/IP
- Synchronization of agent directories
During runtime the agent directories are kept synchronized in case of instantiated or dying agents. However, directories are not cached if a network connection is lost. Upon reconnection the platforms need to resynchronize.
The only conceptual restriction of agents on distributed platforms is that an agent's primary group relation (i.e. the group managing (owning) the agent) must reside on the same host as the agent. This way agents cannot get disconnected from the SystemOwner of the local platform they are running on.
To allow the distributed operation of platforms ensure to set the configuration option DISTRIBUTED_MODE to true. The network port can be specified using the option NETTY_MICRO_PORT.
To initiate a network connection developers can either rely on automatic network discovery provided by the platform (and described in the next subsection) or dedicated functionality to have full control about the connection establishment in environments where discovery might be unsuitable (additional network traffic) or not working (e.g. across firewalls).
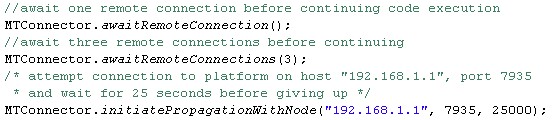
To manage the platform the following static methods of the MTConnector are of key concern:
- initiatePropagationWithNode() - This method initializes the connection with a specified remote node. Parameters include the remote node's IP address, its port (if not given assumes the same port as for the local platform) and time out (time in milliseconds upon which the connection will be considered as failed (default: 20000)).
- awaitRemoteConnection() - This method blocks the application code until a connection with a remote platform (per default one platform) has been established. As parameter the number of platforms which should be connected before continuing execution can be specified.
The screenshot below shows code examples.
To keep developers from explicit dealing with network issues the platform allows the use of network discovery to establish connections between two platform instances running on the same IP subnet. Each platform can use an arbitrary port for the connection between platforms which allows to run multiple instances on one machine.
The discovery itself comes in two flavours: Multicast- and Broadcast-based
Multicast-based discovery is useful when platform instances running on the same pc should automatically detect each other. However, Multicast has found less popularity which can result in non-functioning implementation of particular network cards or in specific configurations (such as virtual machines).
Broadcast-based discovery is useful in exactly this case as it is typically better supported. However, as broadcast binds to a particular port (specified in the configuration (see later)) in a local machine two platform instances cannot use Broadcast-based discovery as the port will already be reserved by one. In this case Multicast is the only option.
The configuration is done as described in the following configuration section. They include indication if discovery is to be started (START_DISCOVERY), the selection of the discovery mode (BROADCAST or MULTICAST), the according broadcast port (DISCOVERY_BROADCAST_PORT) respectively the Multicast group (DISCOVERY_MULTICAST_ADDRESS) and port (DISCOVERY_MULTICAST_PORT).
Additional to this the DISCOVERY_FREQUENCY can be configured (in seconds). Here the trade-off lies between rapid detection of platforms versus unnecessary network traffic (and processing).
Please be aware that discovery will only work if the distributed mode of the platform (DISTRIBUTED_MODE set to true) is enabled.
As of the numerous Platform Features with a pervasive duality of used technology it extensively relies on configuration to optimize application performance ('tuning by configuration').
Configuration generally takes place using the configuration file but can also be done in-code. Both will be described in detail in the next subsections.
The configuration options include:
- Platform Name - Name by which the platform should identify itself
- Internal Message Passing Framework - Options are
- Jetlang
- MicroFiber
- Number of Schedulers (for the MicroFiber message passing framework)
- Number of Worker threads (for the MicroFiber message passing framework)
- Clojure support - activates Clojure support (role implementation in Clojure)
- Distributed mode - Allows the connection of multiple platforms via network
- Network port - TCP port for network connections (via the Netty NIO framework)
- Network serialization - Options are
- JAVA - Java serialization
- JAVA_COMPATIBILITY - compatibility version of Java serialization for older/different JVMs
- XSTREAM - XStream-enabled XML serialization
- Network discovery - Activates network discovery of platforms
- Discovery mode - Options are
- Broadcast
- Multicast
- Broadcast port for network discovery (used if Broadcast is chosen as Discovery mode)
- Multicast port for network discovery (used if Multicast is chosen as Discovery mode)
- Multicast group for network discovery (used if Multicast is chosen as Discovery mode)
- Discovery frequency - Frequency of network discovery in seconds
- MicroMessage validator - Definition of a Message Validator (specified as fully qualified class name).
- Lazy initialization - Indicates if platform components (e.g. message passing) is started lazy or immediately
The configuration file is located in the root folder of the project and is named 'platform.xml'. The XML structure including all available options is shown below.
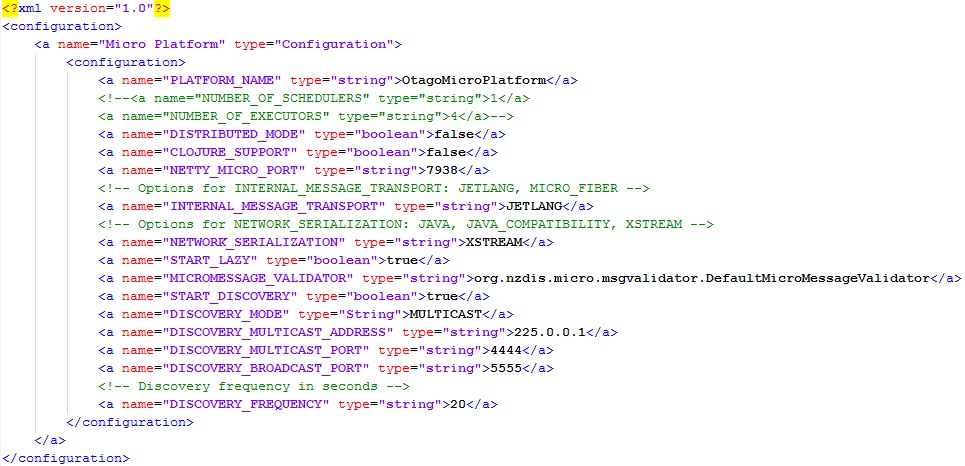
It can be extended with further configuration sets (wrapped in an own node) in an application-dependent manner. Yet the file provided with the distribution includes configuration sets for the Conversation Manager as well as OPAL, a FIPA-compliant agent platform.
Alternatively to configuration via file it can be done directly in the application code. However, its use is intended for ad-hoc tests with different configurations (e.g. debugging) or the use in environments where the configuration file cannot be used (such as in mobile systems). The downside of in-code configuration is that it confuses application code and parameterization. To limit the use of in-code configurations it can only be done prior the initialization of the first social role or the platform itself. The configuration cannot be changed at runtime (at least not by the application developer).
Configuration is generally done by a call to an according method in MicroBootProperties. Example methods can be seen in the selector screenshot shown below.

Along with the actual functionality the platform provides various management functions along with further conveniences for the application developer. All of them are accessible via the MTConnector (e.g. MTConnector.initializePlatform()), with bare core functionality provided via PlatformController (start, shutdown). Check the API documentation for detail.
Key platform management functions include
- initializePlatform() - This method overrides all setting (e.g. lazy initialization) and initializes the full platform. This is not generally necessary as the system itself with start necessary components.
- shutdown() - This method shuts down the platform. All agents are notified and killed properly before shutting the platform down. However, the System.Exit() is not called. It is up to the application developer to kill the whole JVM instance.
- setRandomNumberGeneratorSeed() - This sets the seed for the pseudo random number generator provided with the platform (and used for the Randomcast). Please note it is fairer than Java's default implementation. Its use for general application development is thus recommended (see convenience functions).
Convenience functions are not of core relevance for the platform but ease the developer's life. Some of those are:
- getRandomNumberGenerator() - This returns the random number generator instance and can be called from agents at any time to receive random numbers for the application use.
- printApplicableIntents() - prints all registered applicable intents
- printEventSubscriptions() - prints all event subscriptions on the local platform
- getUptime() - returns the platform's uptime
- getCurrentTime() - returns the current time (as Date object)
- getCurrentTimeString() - returns the current time as String. The boolean parameter indicates whether date information should be included or not.