Replies: 8 comments 31 replies
-
|
1-First, I don't understand why the storage on the bridge server is a limited resource? 2-I'm somewhat confused, I think the real data UTXO node should point to the leaf, not to the root right? |

Beta Was this translation helpful? Give feedback.
-
|
1 - Pollard right now is only used on the CSN side, so this is not about the bridge nodes. (Reducing sizes for bridge nodes is also nice but not as important. 2- There are some problems with pointing to siblings in that diagram. It could be possible, but:
|
Beta Was this translation helpful? Give feedback.
-
That's what I meant by using the two Null pointers in the leaf nodes, we could make one point to the sibling & the other points to aunt/uncle, by adding a flag telling this is a leaf node. -If we can find a way to get the rest of the proof from just the first aunt we are done, It could be easier now recursively with all nodes of the same kind? -Otherwise we need one extra pointer in each internal node ( yes the same problem of making internal nodes different than external) |
Beta Was this translation helpful? Give feedback.
-
|
If every node has 2 pointers, one for sibling and one for aunt, that might work. But there's no space savings compared to now. It might simplify code a bit. But then we still need a way to find those bottom leaves. |
Beta Was this translation helpful? Give feedback.
-
|
Thinking & talking about this more, a direction that looks promising is: The root then has a pointer to nil. Instead of pointing to siblings at the bottom, instead we keep track of the siblings directly. If we want a proof for 02, whatever is storing that proof starts with 03. Then there's the matter of how we keep track of those proofs. Currently if you keep track of the roots, those point all the way down to the leaves and give you a way to get there. If the pointers only point up, we lose that ability. Instead, we can just have a map; the simplest would be a map from uint64 to *polNode pointers. I think this is still a bit less data. Say the number of leaves is n, with 2n total nodes. Right now we have 2 pointers per node, so 4n pointers. With 1 pointer per node & a map, we have 2n pointers in the tree, and then n pointers in the map, for a total of 3n. (The map is probably a bit larger though because who knows how those work) If you were doing this in a full pollard implementation for a bridge node, then the bottom wouldn't need to be a map, it could just be a slice, since every position would be populated. Then it's like a hybrid forest / pollard... It's fun to think about though. Say the bridge node just had a Even without that problem, as the bridge node followed pointers up to the root, it wouldn't know if it was going left or right as it ascended, and so even though it got the hashes of the proof, it couldn't tell the left/right-ness to CSNs. There are ways to make the left/right-ness not matter (like taproot merkle trees), but that is a whole other thing to think about. I think |
Beta Was this translation helpful? Give feedback.
-
|
Do u mean something like this? |

Beta Was this translation helpful? Give feedback.
-
|
That diagram doesn't describe what I was talking about. Storing every non-leaf node twice doesn't seem efficient. Also I don't know what "internal node" means. |
Beta Was this translation helpful? Give feedback.
-
|
External nodes =leaves -Sorry again, if u drew an example for ur map idea, I may understand it better
|

Beta Was this translation helpful? Give feedback.
-
|
While I was trying to calculate & write a Pseudocode for the 1-link to aunt tree by drawing the original tree and see how to map the links; it could be by some power of 2 formula since u r storing log n subtree roots anyway. I will draw a figure, but rightnow from ur 7 nodes //add the rest thru loop |

Beta Was this translation helpful? Give feedback.
-
|
I think I found a confirmation to my method from this MIT lecture about heaps (although it is not heaps the solution, but it is mentioned in the lecture) You can find he specifically says when we want to save the pointers space of a full binary tree, we can store it as an array & access it using the following equations Only, I made it variable size 2D array to make it more easy to visualize the tree view, besides it's more easier to fetch proofs this way; a detail specific to our problem. |

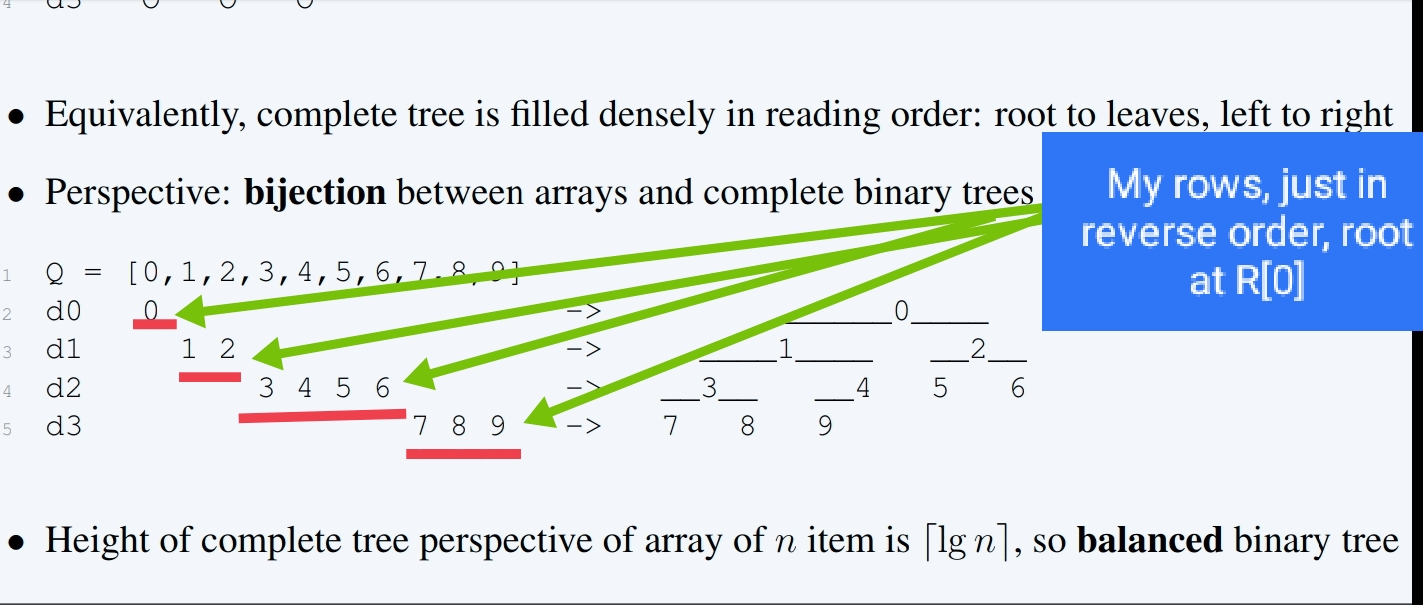
Beta Was this translation helpful? Give feedback.
-
|
Are you familiar with BIP-98? I think what you are attempting to implement here already exists, with a mature implementation: https://github.com/bitcoin/bips/blob/master/bip-0098.mediawiki |
Beta Was this translation helpful? Give feedback.
-
|
@maaku -Since your work mainly uses ( was the pioneer in using the Trie as a Merkle which was adopted by Ethereum till very soon), in Bitcoin I think it would be more comparable to Bolton Bailey work he also suggested a Trie in Mar2021 -I also have to re-read what Andrew Miller (Socrates) said about ur work as he did carried out his Red-Black Tree Merkle idea after and within your project and you two got into a lot of discussions and brainstorming together back in 2012-2014 |
Beta Was this translation helpful? Give feedback.
-
|
Yes but note you only need the hashes for the other nodes you're not verifying, not the whole contents of those entries. In general you should expect a proof of M items from a N-sized utxo set to have approximately The added storage on a bridge node is in theory 32*N, where N is the number of utxos. For any balanced binary tree the number of internal nodes is very close to the number of elements in the tree, and we need to store one hash per inner node. In practice it's a little bit higher because of both data structure and database metadata. But for an order-of-magnitude estimate it approximately doubles the size of the UTXO database, which is in line with expectations. Technically speaking the proof size is exactly the same as the UTXO set size, as you don't need to convey the inner-node hashes when you prove all the elements of a sub-tree. But the bridge node explicitly stores the inner node hashes so that it doesn't have to recalculate them for every update. I'm not sure what's confusing about re-orgs? You walk the tree state back to the way it was before the block was processed, and then process the alternate block. Walking back the state is done the same as it is with bitcoin today: you delete the new utxos and insert back in those which were spent. For a stateless node that needs to "rewind" a proof, it is symmetrically the same. It gets, from the bridge node, an "undo proof" which it applies just as it would a forward proof. That said, there's good reason to operate stateless nodes with proofs based on epoch blocks (e.g. a new epoch every week) and then bridge nodes handle the update to the current block as necessary. Proofs against old epochs are generated via reading from a database snapshot, and deltas from the current and last epoch and intervening blocks are maintained. In this case the stateless nodes don't really need to worry about reorgs as they wait until the new epoch block has 100+ confirmations before migrating their proofs to it. This was the design that seemed most performant when I last looked at this in 2015. Back when I worked on this in the 2013-2015 timeframe, what killed the idea was not proof sizes or utxo database bloat, but proof update performance. To update M utxo values of a N-sized utxo tree, you need to update a number of internal node hashes that scales with Besides the production-ready proof verification code I pointed to above, I do have some old code somewhere that implemented parts of a database-backed Merkle tree for the bridge nodes. But that part of bitcoind has changed so much since 2015 that honestly it would be easier to implement from scratch. The design is pretty simple and bolts right on top of the existing bitcoind utxo database code. |
Beta Was this translation helpful? Give feedback.
-
I think this value, length of M proofs, is bounded in Utreexo by You can see that |
Beta Was this translation helpful? Give feedback.
-
|
They have exactly the same scaling properties because it’s the same type of data structure. Look I was trying to help, but I have no interest in giving any further assistance if you’re going to be so actively confrontational and defensive. Good luck on your project. |
Beta Was this translation helpful? Give feedback.
-
|
I'm not a part of the project!!!! The way I understand it M & N are not of the same order, u define M as the number of UTXOS u need say per block and that's definitely not in the same order as N the total number of UTXOS; ie |
Beta Was this translation helpful? Give feedback.
-
|
Yes, I’m familiar with the idea. I implemented basically the same thing back in 2013. You can read more about that prior project here:
https://bitcointalk.org/index.php?topic=88208.0 <https://bitcointalk.org/index.php?topic=88208.0>
An essential aspect of this “blockchain compression” (stateless validation, as we would call it now) is having a compact proof format which is able to prove inclusion of multiple randomly-selected items from a very large Merkle tree, without duplicating inner-node hash values. This data structure was later used in my 2017 proposal for Merklized Alternative Script Trees (MAST), which is the context for BIP-98. Since last year it has been in production use in yet another application, merge-mining.
I was pointed towards this issue tracker by someone who wanted me to know that the utreexo project needed help designing a compact multi-element proof for Merkle trees. Which surprised me, because I believe this to be a solved problem. Why re-invent the wheel?
You can find an up-to-date implementation of BIP-98 multi-element Merkle tree proofs here:
https://github.com/tradecraftio/tradecraft/blob/16/src/consensus/merkleproof.h <https://github.com/tradecraftio/tradecraft/blob/16/src/consensus/merkleproof.h>
https://github.com/tradecraftio/tradecraft/blob/16/src/consensus/merkleproof.cpp <https://github.com/tradecraftio/tradecraft/blob/16/src/consensus/merkleproof.cpp>
https://github.com/tradecraftio/tradecraft/blob/16/src/rpc/misc.cpp#L454 <https://github.com/tradecraftio/tradecraft/blob/16/src/rpc/misc.cpp#L454>
It’s a complete consensus-safe implementation of BIP-98 multi-element proof validation, and a limited ability to construct those proofs via a “createmerkleproof” RPC. The only thing that is missing is the ability to construct and extract proofs from prefix-ordered trees (“trie”), mainly because that hasn’t seen a production use yet. Admittedly that’s probably what utreexo is interested in, but we’re talking about utility code that should only take a few days to write up.
… On Oct 1, 2021, at 9:15 PM, Shymaa-Arafat ***@***.***> wrote:
I'm not from the Utreexo team, so this is not their official reply (I just tried to learn & suggest/discuss some ideas). So,
I think BIP98 you are referring to related to how full nodes verifies transactions and go through their inputs (by tracing where they was once UTXOS)
-While the Utreexo project was originally for Stateless nodes that do not maintain the whole Blockchain in their drives or even the complete UTXO set in their main storage, but instead validate transactions by contacting a bridge server with the UTXOS that becomes spent in the transaction they are trying to validate & the bridge server sends them the proof. The Utreexo proofs is distinguished by a worst case upper bound of O(log N) because it maintains a collection of must be complete trees (a forest) think of it as a binary representation of the number of UTXOS where a 1bit corresponds to a full tree of this depth this way any proof is a max of logN roots the full trees that are there(the number of bits), and one regular proof of only one of those trees that corresponds to the bit that became 1 when inserting that UTXO to the set.
.
-Add to this as the designer says in his replies, what he discussed here is an even more compact design to be used by lightning nodes (not stateless node & a bridge)now he is trying to store the forest in a CSN Pollard node where storage, unlike the bridge node, is still a scarce resource we need to optimize it's use and 2 left & right pointers for each node in the tree was too much as he says (now, after this brief, you can follow the designer's own words)
|
Beta Was this translation helpful? Give feedback.
-
|
Till I complete reading the whole reply, I did not say Utreexo needed help designing compact proofs pls do not mis use my words, Utreexo was awarded for the design and it's finished for Stateless nodes the discussion here is about the extension to it into light nodes where the design is the same but the Pollard CSN corresponding to bridge nodes make them have to compact the implementation data structures in coding not just the abstract design |
Beta Was this translation helpful? Give feedback.
-
|
Now I recalled this part of the survey: Also, and sorry to use the Utreexo Discussions, may I know what do you think about an idea of mine to partition the UTXO set into subsets whatever is the Underlying strucutre? |
Beta Was this translation helpful? Give feedback.
-
|
Hi, sorry for not following this thread for a bit -- Discussion about hash-tree designs is cool but I was interested in ideas about the "pollard representation" -- how to possibly revamp the pollard data structure. I started by pointing out some of the problems with how pollard works. It does work though! But, I didn't really describe the requirements for what pollard is. Pollard is a sparse subset of a full set of perfect binary trees. For simplicity's sake we can think of it as just one perfect binary tree. We want to store some subset of the tree, such as storing only 04, 11, 12, 14 in the initial example. The code does this now with pointers to nieces, which works but can be a bit confusing to work with. @Shymaa-Arafat, you've mostly posted about storing complete trees. We already have a implementation for that, called @maaku The proof update performance of the current utreexo accumulator is pretty fast. I don't have an exact number on hand (I could get one) but each block causes a few thousand deletion and additions, and something on the order of 10K hash operations, so much less than 25X. The locality of having UTXO created at the same time adjacent to each other in the tree greatly reduces proof sizes and hash operations, as @kcalvinalvin has shown here: #257 -- This is also the reasoning behind changing the accumulator design, discussed here #249 I don't think there's wheel re-invention going on here. From reading the BIP it seemed to describe a one-off construction where one could take an initial set of elements, process them into a tree, and then later create inclusion proofs of elements in that set. In the BIP and code you've linked, I didn't see anything about subsequently deleting from, adding to, or modifying the set, and how to batch those operations (that is, to delete several items from the set faster than deleting them one at a time). If you do have code or ideas for that part it would be great to check it out. Maybe the #249 thread or a separate thread though. I do still think there could be improvements to how pollard is implemented (with pointers pointing up instead of down) but I maybe should make a new discussion topic for that. |
Beta Was this translation helpful? Give feedback.
-
|
With that approach you also can't prove the absence of a UTXO, making fraud proofs not possible. That's a pretty big downside, and one of the core motivations of committed UTXO trees in the first place. |
Beta Was this translation helpful? Give feedback.
-
|
-First, the term sparse Merkle tree led me to this 2016 swedish funded paper in case anyone is interested 2- I meant the nodes [4,11,12,14] , the proof of leaf 5, are not connected to be called a "tree" or subtree; anyways it doesn't matter the names the point is how to store&link those nodes. I think I'm having trouble understanding why u need to store a pointer to aunt or niece, instead of reaching them with an indexing formula according to how ur Forest arranged in memory. 3-and this maybe like a philosophical dilemma I hope u can be patient enough to think about it: |
Beta Was this translation helpful? Give feedback.
-
Yeah Utreexo doesn't support proof of non-inclusion. |
Beta Was this translation helpful? Give feedback.
-
What? From
In any case, for consistency with Bitcoin Core, I think u could have used exactly the same UTXOS set hash strucutre that is used there with just adding a field pointing to the leaf in the forest (whether a real pointer or an index value) This will follow the standard & will be less than the map fields |


Beta Was this translation helpful? Give feedback.
-
|
Closing this thread as it's gone off-topic. This discussion section of the repo is for discussion about implementation, not about the design goals of utreexo. @Shymaa-Arafat, I'd ask that you please get a better understanding of the general goals of the project before commenting. Instead of incredulity that we aren't aware that go maps support deletion, consider that we might be well aware of that, and deletion from the accumulator is a separate problem. I'd also ask that if you want to paste code, use markdown and not jpgs. I'll leave this up but will delete future posts like this. |
Beta Was this translation helpful? Give feedback.
-
There's a struct in the accumulator called
Pollard. It's the main data structure that contains the utreexo hash forest, but unlikeForest,Pollardcan contain a partial forest, with branches chopped off (hence the name).In fact with a swapless design it probably makes sense to move both bridge node and CSN functionality over to using
PollardThe problem with pollard
There's some other stuff, but mainly pollard is made up of nodes. Nodes have a hash, which is 32 bytes long, and 2 pointers, which are probably 8 bytes long on most computers. (There's now also a bool for whether the node should be remembered! Temporarily...) The pointers point down to other nodes, so that if you only have the root node you can follow those pointers down and get to any node in the tree that way.
There are several problems here, mostly with the pointers. If you're storing a full binary tree, half the nodes are at the bottom (call them leaves) and half the nodes are on upper rows (not leaves. We don't have a catchy name for a node that's not a leaf. // TODO: make catchy name for those.)
The leaves don't need pointers, as there is nothing below them. That means half the nodes have 16 bytes of wasted data; out of all the pointers in the forest, half of them are wasted. So 8 bytes per node. Since the nodes are only 48 bytes in total, that's pretty significant.
Memorability of nodes is also something we need to keep track of. You can do that with an extra bool variable in the node struct, but that has a similar problem to the pointers: half the nodes don't need it. All the non-leaf nodes would then still have a bool but it wouldn't do anything.
Pollard pointers
There are more annoying things about pollard. The pointers point down, from the root towards the leaves. But they don't point down the way you might expect.
Going off of this tree:
14 is the root, and it has 2 pointers. The left pointer goes to 12, and the right pointer to 13. OK.
12 has 2 pointers as well. But 12's pointers go to 10 and 11, while 13's pointers go to 8 and 9. 0 through 7 have pointers that don't point to anything.
This is kind of confusing because the root has pointers that go to the left and right children, but nodes that are neither roots nor leaves have pointers that go to the nieces: the children of siblings. It needs to work this way though, since you want to keep proofs, and that's how proofs work. For example, you might retain a proof of 03 in the pollard. That would consist of 04, 11, 12. With the niece pointers, this is possible: 12.right -> 11, 11.left-> 04.
If the pointers were to children, we'd need to store 13 and 10, which aren't needed. In this case having child pointers instead of niece pointers would nearly double the number of nodes needed.
Some pollard ideas
How can we fix these problems? Here are some things to try, or that I already tried.
interface nodes
Since there are 2 different kind of node (leaf & non-leaf), let's use 2 different types, and use an interface pointer.
Then we define polInterface so that both the leaves and non-leaves implement it, with polLeaf returning an error on .Left() or .Right()
I actually tried this and it worked but it doesn't help; the pointers become twice as big since there is a pointer to the actual data in memory, and also a pointer to the type. That seems to be how the compiler deals with interface pointers. It's unfortunate because we know what the actual type will be at all times. In our code there's never any question of "hey is this a leaf or not?" because we can just look at the position to find out. So if there were a way to omit the type pointer, we could cast or assert the type correctly every time.
remember pointers
Instead of a bool for memorability, we can have the pointers on a leaf node point to a dummy node that means "memorable" if you point to it. This would save some space instead of using a bool.
remember bit
Instead of a bool or pointer tricks, we can say that the hashes are now 255 bits long, and the last bit indicates whether the leaf is memorable or not. In theory this reduces cryptographic strength, but not by much, and 127.5 bit security is fine.
keep track of memorability somewhere else
Use a map or something to track which leaves are memorable. Might end up taking up a bunch of space, but maybe not. You only need 1 bit for each leaf, so you could use a bitmap for that. It'd be 8 or 9 megabytes. If the pollard is very sparse and only holds a few branches, it's wasteful, but if the pollard is reasonably dense then that's pretty efficient.
parent pointers
The pointers point down, but pretty much everything we want to do (prove things, verify proofs) goes from bottom to top! So it's annoying; you start at the root, follow pointers to the bottom, and either cache the nodes along the way, or follow the pointers again to get to one higher than last time. If you do that (which is dumb but happens in the code!) it's log(n) * log(n)/2 operations per proof.
So could we instead have parent pointers? Or aunt pointers? Like 5 could point to 11, 11 could point to 12, 12 points to 14. 14 would have a pointer that doesn't point anywhere, but there's only one root that has that, instead of all the leaves.
But 5 also needs to point to 4, and 4 also needs to point to 11. So leaves would need 2 pointers (sibling, aunt) and non-leaves would only need 1. So that distinction is still there. But maybe this is a better way to do it! Or maybe it doesn't work at all; I think I remember trying this and giving up on it and sticking with niece pointers. But I didn't try very hard & didn't write anything about it, so it could be worth looking into.
There's are some of the annoyances with pollard, and things to try in order to improve it. Comments & ideas welcome!
Beta Was this translation helpful? Give feedback.
All reactions