Confused about sidekiq enqueued keys and memory usage #3978
Comments
|
hawaiian_ice_sidekiq_jobs_development is a Redis namespace. One of your
developers possibly accidentally used a production Redis URL as their
development Redis. unique means that's a key for the unique jobs feature
in Sidekiq Enterprise. I suspect it is safe to remove all `
hawaiian_ice_sidekiq_jobs_development` keys but I would double check with
the rest of the team first.
…On Tue, Sep 25, 2018 at 11:21 PM Alex Evanczuk ***@***.***> wrote:
Ruby version: 2.3.5
Sidekiq / Pro / Enterprise version(s):
enterprise, "4.2.10"
I'm looking into some issues we are having on our production application
where starting a month ago our application started using redis excessively
even when nothing special was happening:
[image: screen shot 2018-09-25 at 10 03 26 pm]
<https://user-images.githubusercontent.com/3311200/46060690-09f20800-c119-11e8-8733-6d6c127ec7e6.png>
This corresponds to an operation where queued up millions of sidekiq jobs,
exceeding the redis memory and causing sidekiq to drop jobs. We ended up
having to manually try to delete jobs using the sidekiq API. However, it
appears that maybe some jobs are left over. A couple of days ago sidekiq
queued up and tried to run 500 instances of the jobs that were queued up
more than a month ago (all immediately failing because the worker class has
since been deleted).
The sidekiq API is not showing anything, so I looked at our redis keys to
see what I could find.
all_keys = []$redis.scan_each(match: '*') do |key|
all_keys << keyend
HawaiianIce RO PRODUCTION 27> all_keys.count18539
all_keys.map{|k| k.split(":").first}.group_by(&:itself).transform_values(&:count)
{
"hawaiian_ice_sidekiq_jobs_development" => 14095,
"cache-production" => 4370,
... [ OTHER UNRELATED THINGS ] ...
}
$redis.mget('hawaiian_ice_sidekiq_jobs_development:unique:f93b7540c29b11e99cb33d08d6ec191538bf8ab8')
[
[0] "4692669172.565897"
]
workers = Sidekiq::Workers.new
workers.each do |process_id, thread_id, work|
if Time.at(work['run_at']).to_datetime < 1.month.ago
puts "ProcessId: #{process_id}, Q: #{work['queue']}, JID: #{work['payload']['jid']}, Retry: #{work['payload']['retry']}, RunAt: #{work['run_at'] ? Time.at(work['run_at']).to_datetime : 'nil'}, EnqueuedAt: #{work['payload']['enqueued_at'] ? Time.at(work['payload']['enqueued_at']) : 'nil'}"
endend
[
[0] "0:15:439b379dfc19",
[1] "1:15:ee39c095b9dd",
[2] "2:14:e4bb2d1626fe",
[3] "3:15:5a02e3edfdd5"
]
What is going on here? Why do we have 14K sidekiq jobs that have the
development suffix? Why aren't they showing up in the API, and why are
their values just a decimal type?
Is this something that Sidekiq::Workers.new.prune would help with?
Thank you!!
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#3978>, or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAALX1ALY_guf3bd6QVnFXSYRR7CLuRoks5uexzMgaJpZM4W5-Rv>
.
|
{kind=link}
|
Thanks @mperham. I knew there was something fishy going on and that seems clear to me now that you say it. Appreciate your quick response and all the hard work on this service. |
|
Hi @mperham - I am opening this up again because we realized that these keys were actually production keys based on our configuration: I definitely realize this is not a good practice and it was likely a mistake in our initial configuration, and migrating to a new namespace is a future project for us. For now, we'd like to analyze what is using so much space, and maybe clear out any cruft data. Does sidekiq offer any first-class ways to analyze redis usage? If not, how might you recommend doing this? Based on the graph above, I think it might have to do with a huge increase in the number of processed jobs. However, I would have thought that sidekiq would just have a single key that holds the number of processed jobs and other stats in O(1) space. Any advice on this would be greatly appreciated. Alex |
|
Sidekiq does not offer such tools. You are looking for a Redis RDB analyzer: https://github.com/mperham/sidekiq/wiki/Using-Redis#notes Your inclination is correct, processed jobs are discarded and do not take memory. |
|
Thanks for the reference to that tool. I hooked up a snapshot of our DB to these analysis tools and found that the vast majority of keys are taken up by sidekiq related keys of the form: I do not think that the 12K unique keys are necessary, although I don't know the internals of sidekiq. We have less than 2K jobs scheduled, and very often we drop to 0 jobs, yet our memory usage has remained constant. is it possible sidekiq is holding onto unique keys for some reason? Is there some way to look into what jobs, if any, are using the unique keys? I also found that sidekiq jobs and their parameters seem to be stored across a number of different keys. For example, instead of a single key, value for a job, it looks like sidekiq holds the parameters across many different key, value pairs with keys that reference the unique job ID. Does this sound accurate? Is there (internal?) documentation on this, as I am curious about how sidekiq uses redis. Thanks again, |
|
Unique keys can linger if jobs die or are stuck in the retry queue. They will persist until the stat:* is normal, those keys are how we track the jobs processed/failed per day for the Dashboard. Sidekiq does not duplicate job data in Redis, job data is only ever in one place at a time: in queue, retry, dead, or private queue (with super_fetch). |
|
Thanks for the explanation. In our organization we use practically infinite
(many years) unique for values to attempt to limit us to only once job
execution. This means those keys would never be cleaned up it sounds like.
Is it possible to find what jobs those unique keys are for? If not and we
just delete them, would it cause any corrupt data issues as far as sidekiq
is concerned, or will it simply allow jobs to run that otherwise weren’t
allowed to? I was thinking of waiting until our queue is at 0 then deleting
the unique keys, since if our queue can reach zero it implies those unique
keys are dangling as far as I understand.
|
|
Using a long expiry is not a good idea, the wiki tries to make it clear that unique locks are best effort and shouldn't be used as a replacement for idempotency. The unique lock is a lock that is only removed (by default) when the job succeeds. If the job is lost somehow or dies, the lock will (effectively) never expire and unlock. I will add an expiry validation that unique locks longer than X hours are discouraged, where X is maybe 48. It's not possible to map a unique lock back to the job that created it as it's a one-way hash. If you delete the locks, you'll be able to run those jobs again. |
|
The reason we are doing this is as a debouncing mechanism. Namely, we use a "always unique" unique_for value and then perform_in 10.minutes. This debounces for 10 minutes. It sounds like it is suggested to instead use another debouncing mechanism. For example, postgres offers locking strategies that could be used similarly, where we only queue up the job if there is no postgres debouncing lock (and the lock gets dropped after the job completes). Thanks for the information regarding lock -> job identification. I think I might just delete the unique keys in this case. |
|
Sure, if you want to debounce for 10 minutes, set |
|
@mperham I have 2 questions if you don't mind! It looks like the increase is a result of queues that have hundreds of thousands of jobs in what my colleague is telling me is a reliable queue. Also possible to use the redis ruby client: Ideally I'd like to just delete these queues using Another question -- if the scheduled set is empty, is it generally safe to delete all unique keys? I don't have a deep enough understanding of sidekiq to know if this will cause unexpected consequences beyond simply unblocking jobs from running. No jobs should run though when deleting the keys if there is nothing in the scheduled set. Can you confirm if deleting keys has any other side effects beyond unblocking jobs from running? |
|
Jobs can be in scheduled set, dead set, retry set, etc. while holding a unique lock. It's safe to delete a unique lock from Sidekiq's perspective -- all that might happen is a duplicate enqueue. Those queues are private queues from reliable_fetch. reliable_fetch has been deprecated for two years now in favor of super_fetch. The UI does not show the contents of private queues. If you are still using reliable_fetch, I'd urge you to update Sidekiq Pro and upgrade to super_fetch immediately. |
Ruby version: 2.3.5
Sidekiq / Pro / Enterprise version(s):
enterprise, "4.2.10"
I'm looking into some issues we are having on our production application where starting a month ago our application started using redis excessively even when nothing special was happening.
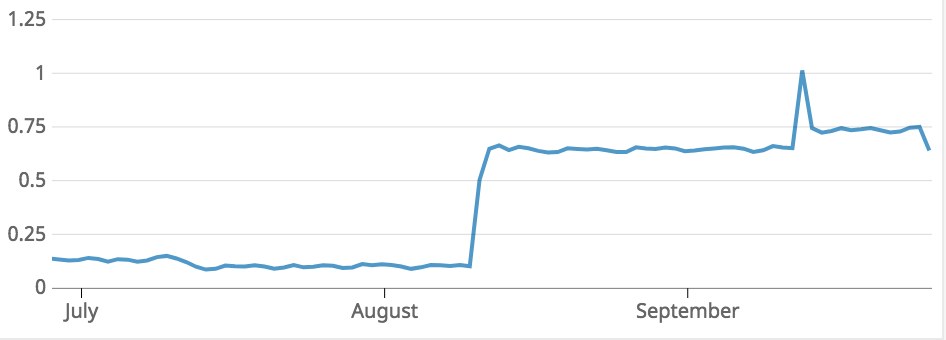
This corresponds to an operation where queued up millions of sidekiq jobs, exceeding the redis memory and causing sidekiq to drop jobs. We ended up having to manually try to delete jobs using the sidekiq API. However, it appears that maybe some jobs are left over. A couple of days ago sidekiq queued up and tried to run 500 instances of the jobs that were queued up more than a month ago (all immediately failing because the worker class has since been deleted).
The sidekiq API is not showing anything, so I looked at our redis keys to see what I could find.
What is going on here? Why do we have 14K sidekiq jobs that have the development suffix? Why aren't they showing up in the API, and why are their values just a decimal type?
Is this something that
Sidekiq::Workers.new.prunewould help with?Thank you!!
The text was updated successfully, but these errors were encountered: