Shinken stops doing anything intermittently #1636
Comments
|
Did you try without the redis retention module ?
|
|
@olivierHa Part of the things we tried was to switch to Redis, we previously used Memcached retention. |
|
Have you tried to launch a daemon using the cli to see more "output/debug" 2015-05-19 20:41 GMT+02:00 dmsimard notifications@github.com:
|
|
There's no obvious errors in the logs, even in debug output. We don't want to lose the retention (acknowlegements, service statuses, etc.) across shinken reloads. |
|
In debug mode you should see when redis retention is called ('asking ...')
|
|
So further troubleshooting this got me thinking the issue might have been related to the fact that there are two active schedulers in one of my realms (the bulk of the hosts and services are there). My understanding when you have multiple schedulers in one realm is that the arbiter will distribute evenly your highest level of hosts/services (parent hosts) across your schedulers. It looks like this distribution is random and non-determinist and might be the root cause of the problem where hosts and services are shuffled around, causing retention-related issues. Yesterday, I've removed one of the two schedulers in this specific realm and even with the redis retention, I am no longer having the issue where shinken stops doing anything for 10 minutes every hour. |
|
Might be related to #1807 too. Shinken seems not to like many schedulers... |
We have a pretty annoying issue that persists even after upgrading to Shinken 2.4: Every hour or so, Shinken schedulers and pollers will stop doing anything for up to 10 minutes.
We've tried many things in order to try and resolve the issue but running out of ideas right now..
Some insight I believe could be relevant on what the setup and configuration looks like:
The realm configuration looks like this:
Realm "All":
Realm "Default":
Realm "01":
Realm "N":
Some data on the problem:
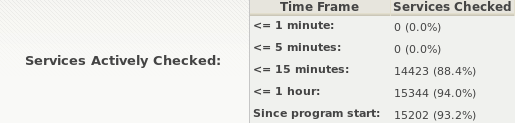
Looking at the logs, this seems to correspond to regular re-distribution of the configuration:
We definitely don't reload the configuration on a regular basis so it looks like this is Shinken's own doing.
There is also what might be related but could be otherwise another issue - our Arbiter often gets timeouts when distributing the configuration to the schedulers and pollers. This isn't a network issue - if you curl the https link directly, it will not respond "OK", it will really timeout and doing a tcpdump, you see that the curl request indeed makes it to the server. It looks like the poller or the scheduler gets stuck on something but eventually comes back available by itself. Stopping and starting the services resolves this but is not a viable solution.
I turned on debug logging on the pollers/schedulers but haven't found anything that seemed relevant.
Any ideas ? I can provide more details if need be, this is a critical issue for us.
The text was updated successfully, but these errors were encountered: