-
|
After generating a VTT file, the subtitles sometimes get hastened, and scroll by much faster than the actual audio. They usually get fixed within about 30 seconds (after one chunk of audio is processed), but if the audio is long, they start scrolling faster again after a short duration. |
Beta Was this translation helpful? Give feedback.
Replies: 3 comments 12 replies
-
|
I've personally observed this behavior more on the |
Beta Was this translation helpful? Give feedback.
-
|
I had a 90 mp3 file go several minutes out of sync in large. I had switched to small mp3 and the issues went away but I sure would like to return to the large model with confidence when a get a GPU. I had assumed the issue was with mp3 time code tracking issue, so I hope it isn't somehow a large model problem. |
Beta Was this translation helpful? Give feedback.
-
|
This is happening to me as well, using the Medium model, and generating a VTT for a video in Brazilian Portuguese. |
Beta Was this translation helpful? Give feedback.
-
|
This is one of the failure mode of the hacky long-form heuristics (in Lines 220 to 222 in 2d3032d and you can modify this block to always reset the context to mitigate the tendency of going out of sync. In the paper, we have seen a slight improvement when using this previous-text conditioning than not:
but it didn't always help (WER increased in TED-LIUM3). It might be worth making this previous-text conditioning as an optional flag, if the failure case is common in practice. EDIT: just added |
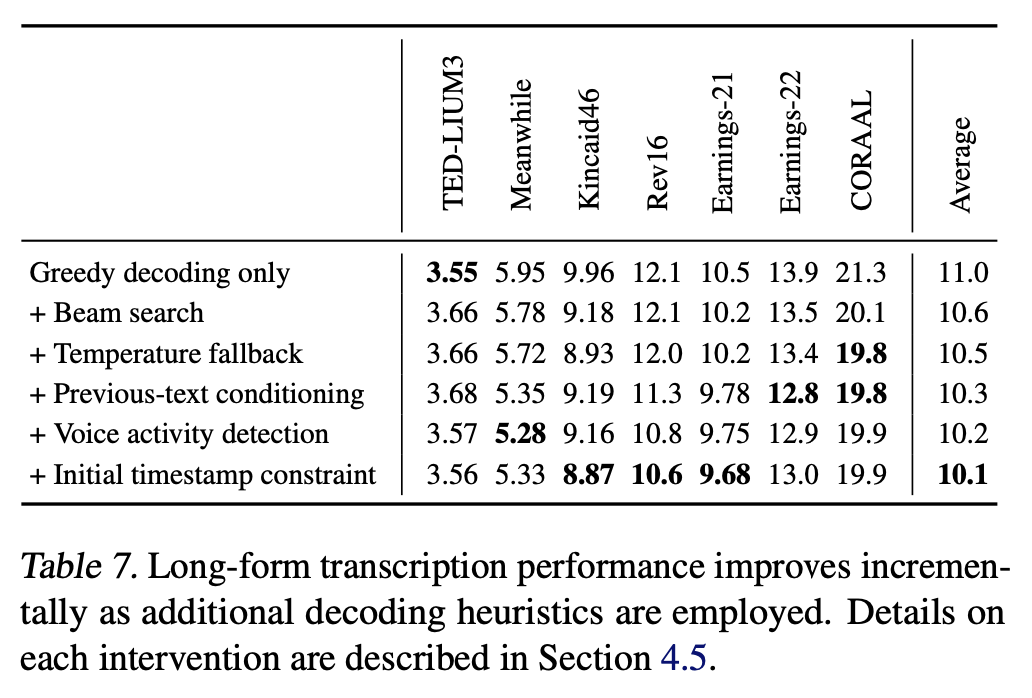
Beta Was this translation helpful? Give feedback.
-
|
@flesnuk Thanks! This clarified my question! Really appreciate it. |
Beta Was this translation helpful? Give feedback.
-
|
@jongwook - appreciate the detailed response! Just to be super clear, in Table 7 - does this shows the impact of setting Lines 220 to 222 in 2d3032d A bit confused by the complex semantics 😄 Thanks! |
Beta Was this translation helpful? Give feedback.
-
|
yes, after this thread I added the condition, and the three lines above now looks like this: Lines 235 to 237 in 0b1ba3d The row "Previous-text conditioning" in Table 7 and below used the setting equivalent to |
Beta Was this translation helpful? Give feedback.
-
|
As an interesting failure mode, attempting to transcribe this with the I found that setting Either way, I'm glad the EDIT: on the whole, I think EDIT 2: It is amazing how much difference skipping the intro music makes for Whisper. |
Beta Was this translation helpful? Give feedback.
-
|
I've also noticed that sometimes the smaller than large models seem to do just as good of a job if not better in many scenarios. |
Beta Was this translation helpful? Give feedback.
This is one of the failure mode of the hacky long-form heuristics (in
transcribe.pyand discussed in Section 4.5), where the timestamp offsets sometimes accumulate over time, because the transcription from the previous 30-second window including the timestamps are fed to the model as conditioning input. This is currently controlled by a currently hard-coded constant here:whisper/whisper/transcribe.py
Lines 220 to 222 in 2d3032d
and you can modify this block to always reset the context to mitigate the tendency of going out of sync.
In…