| date | comments |
|---|---|
2023-04-15 |
true |
这里记录每周值得分享的生信相关内容,周日发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。

@kkjtmac 目前利用ChatGPT进行套话的编写、给个初步代码思路以及大段英文的概括总结。
@ShixiangWang 最近利用 ChatGPT 进行英文写作和基金摘要英文的翻译,能解决很多头疼的问题,推荐大家都试试。
1、Science | 表观遗传学和数学结合,预测癌细胞行为
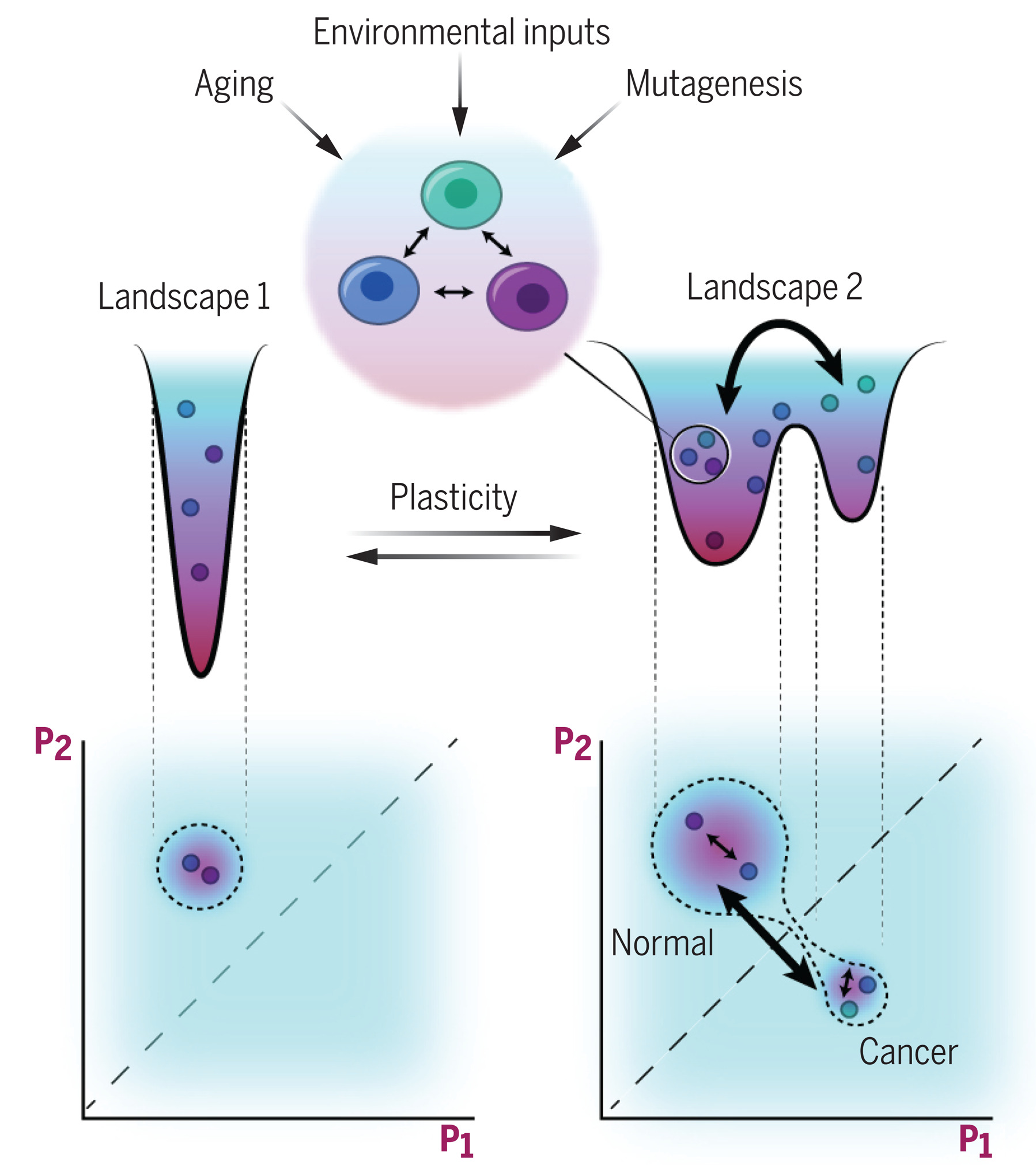
这篇综述文章指出,通过数学建模可以将癌症的表型可塑性与驱动癌症的表观遗传变化联系起来。这种新的表观遗传定量方法可以更好地定义和测量基因功能中的表观遗传学缺陷及其与癌症遗传景观的相互作用,从而更好、更早地诊断癌症并预测其行为。
2、Nat Genet | 血浆代谢组基因组图谱突出代谢物与人类疾病的联系

加拿大戴维斯夫人医学研究所对1,091个血液代谢物和309个代谢比率进行了基因组关联分析,分别识别了248个位点,690种代谢物和69个位点,143个代谢比率的关联。整合代谢物——基因和基因表达信息,作者识别了109种代谢物和48个代谢比率的94个效应基因,进一步地,作者识别了与12种性状和疾病存在因果关系的22种代谢物和20个代谢比率。研究描述了代谢物的遗传结构,为研究代谢物在基础疾病中的作用提供了宝贵资源,也为治疗靶点的寻找提供线索。
3、Science Advances | 基于DNA 测序的机器学习模型解码测序读数编码数据值

2023年1月4日不列颠哥伦比亚大学和东京大学的研究人员在《Science Advances》上发表了A universal sequencing read interpreter的文章,报告了 INTERSTELLAR(interpretation, scalable transformation, and emulation of large-scale sequencing reads,大规模测序读数的解释、可扩展转换和仿真), 成功地从一系列短读长和长读长测序读数中提取了信息,并翻译了单细胞 (sc)RNA-seq、scATAC-seq 和空间转录组学的那些数据,从而方便研究人员用不同软件工具进行分析。INTERSTELLAR 将极大地促进基于测序的实验的开发和数据分析管道的共享。理论上,它可以解码任何类型的测序读数中编码的数据值,并将它们转化为另一种选择结构的测序读数。
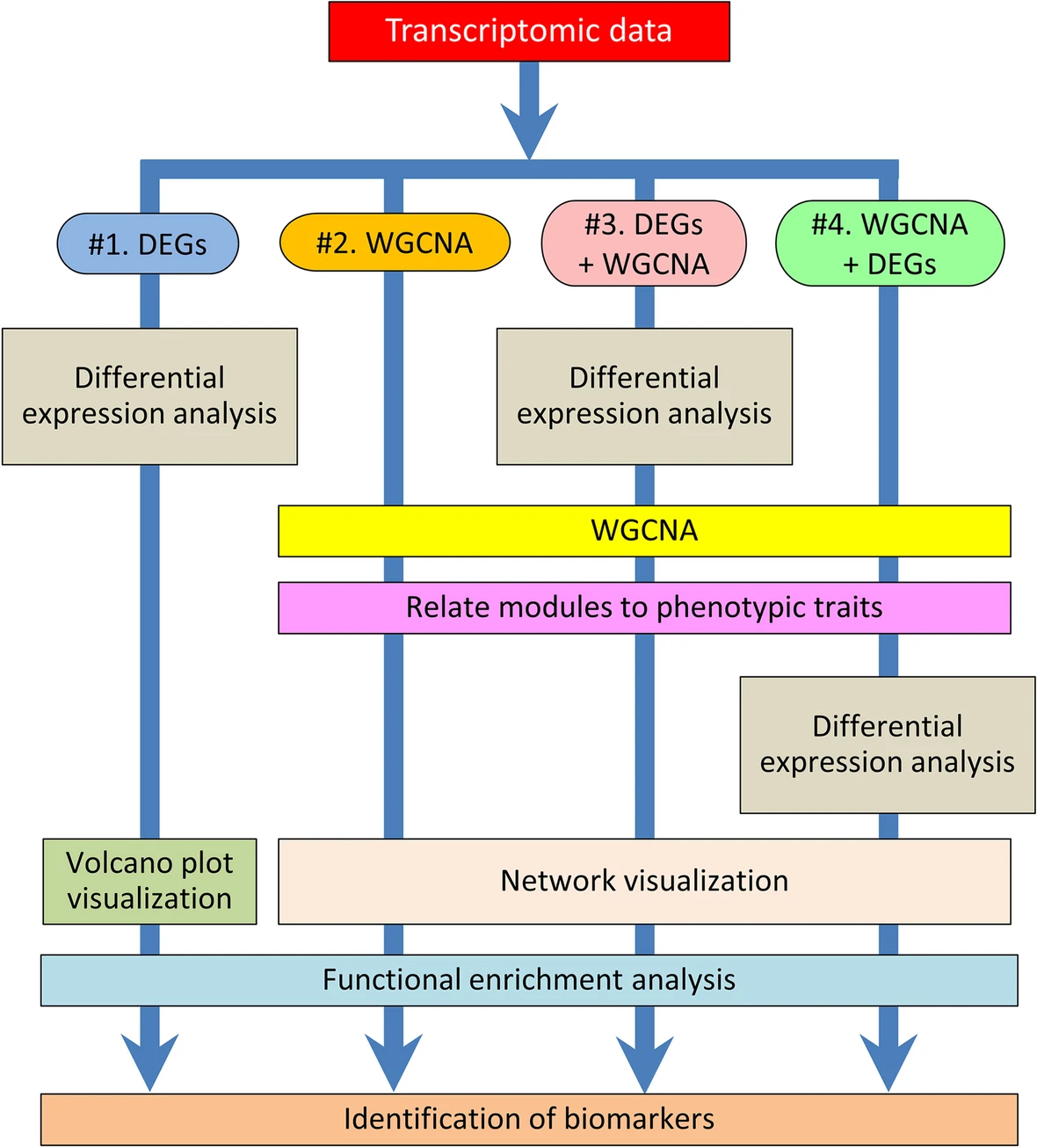
转录组的数据分析中,WGCNA分析是一种比较常用的手段可以协助我们快速寻找到特定模块中的hub gene,目前市面上对转录组的分析主要是4种:1,直接差异分析;2,全部基因WGCNA; 3, 差异分析然后再WGCNA;4全部差异基因WGCNA再差异分析。有研究者对这几种方式进行了有效的评估,得出结论:在所有情况下,WGCNA + DEGs的表现明显优于DEGs + WGCNA。另,对于DEGs+WGCNA,作者指出:DEGs+WGCNA会影响网络的结构并导致错误的结论。此外,这种方法的有效性从未被证实,官方也并不建议在WGCNA之前应用DEGs。
5、 使用 Openbiox Hiplot (ORG) 在线开源绘图工具绘制发表级网络图

网络图是科学数据分析中最常用的图形之一。Openbiox Hiplot (ORG) 开源绘图工具在基础模块中提供了基于 igraph 的发表级网络图绘制功能 Network (igraph)。更复杂的网络图考虑使用 Cytoscape 进行绘制。
- 工具链接:https://hiplot.cn/basic/network-igraph
- 源代码下载:https://github.com/hiplot/plugins-open/tree/master/basic/network-igraph

计算机学中抽象的马尔科夫链、主成分分析以及条件概率等概念往往让人很难深入地去体会和理解。通过本文将这些抽象的理论概念进行可视化,还可调节相应参数来改变结果,使这些抽象概念生动而立体化。

瑞典私募股权基金Summa Equity收购了三家生信软件公司:Pierian、Seven Bridges 和 UgenTec,将其整合成了新公司Velsera。这篇文章讲述了这三家生信公司的主要业务和发展历史,并讨论了未来生信软件公司的发展逻辑。
8、 我们开发了第一款中英双语ChatGPT检测器,还有...
开发一套ChatGPT检测工具,同时收集第一手宝贵的人类-ChatGPT对比数据集,来助力相关学术研究。 主要计划: 收集一批有价值的人类和 ChatGPT 对比的中英双语问答语料,这对于我们研究人类和大型语言模型(LLM)很重要,可以帮助我们研究LLM的特点、跟人类的差距、未来LLM改进的方向; 对大量的人机对比语料进行细致的分析,并进行多方面的人工评测,探究人类和ChatGPT分别具有什么有趣的潜在的模式。这些探索将有助于思考LLM未来应去往何方; 最后,基于对比数据集以及语料分析,开发应对不同场景的一系列检测模型,这些模型可帮助普通用户和UGC平台来识别、监管 AIGC (AI Generated Content)。
- 工具链接:https://huggingface.co/spaces/Hello-SimpleAI/chatgpt-detector-qa
- 项目主页:https://github.com/Hello-SimpleAI/chatgpt-comparison-detection

科研者之家上线了Medreading板块,文献数据同步Pubmed,界面进行最彻底的汉化,并具有极致的检索速度和多样化的文献分析特点。
10、shinyhelper | 一款帮助Shiny添加帮助文档的R包
这个R包可以使用Markdown文件向Shiny添加帮助文档。
11、MIT 生信机器学习课程

12、自学是门手艺
# pseudo-code of selfteaching in Python
def teach_yourself(anything):
while not create():
learn()
practice()
return teach_yourself(another)
teach_yourself(coding)这本书核心两个概念“自学”+“编程”。
不夸张地讲,这可能是当前世界上最硬核的鸡汤书了 —— 因为,虽然它就是鸡汤(李笑来自认就是个鸡汤作者),但它不是 “只是拿话糊弄你” 那种,也不是 “只不过是善意的鼓励” 那种,它是那种 “教会你人生最重要的技能” 的鸡汤,并且还不仅仅只有一种技能,起码两个:“自学能力” 和 “编程能力”…… 而这两个能力中的无论哪一种,都是能确定地提高读者未来收入的技能,对,就是 100% 地确定 —— 有个会计专业的人求职的时候说 “我还会编程” 且还能拿出作品,你看看他可不可能找不到工作?你看看他是不是能薪水更高?
- 第27期:真与假的界限在哪里
「Openbiox 生信周刊」运维小队:
@ShixiangWang(王诗翔)@kkjtmac(阚科佳)@NiEntropy(赵启祥)@He-Kai-fly(何凯)@JnanZhang(张佳楠)@Tomcxf(陈啸枫)@wangdepin(王德品)@kongjianyang(空间阳)
这个周刊每周日发布,同步更新在微信公众号「优雅R」(elegant-r)上。
微信搜索“优雅R”或者扫描二维码,即可订阅。

(完)