Three-dimensional (3D) human modeling is the process of creating virtual representations of the human body using computer software. This technology has seen widespread use in various industries, including film and video game production, medical research, and fashion design. The use of 3D modeling has revolutionized the way human beings are represented in various media, providing unprecedented levels of realism and detail.
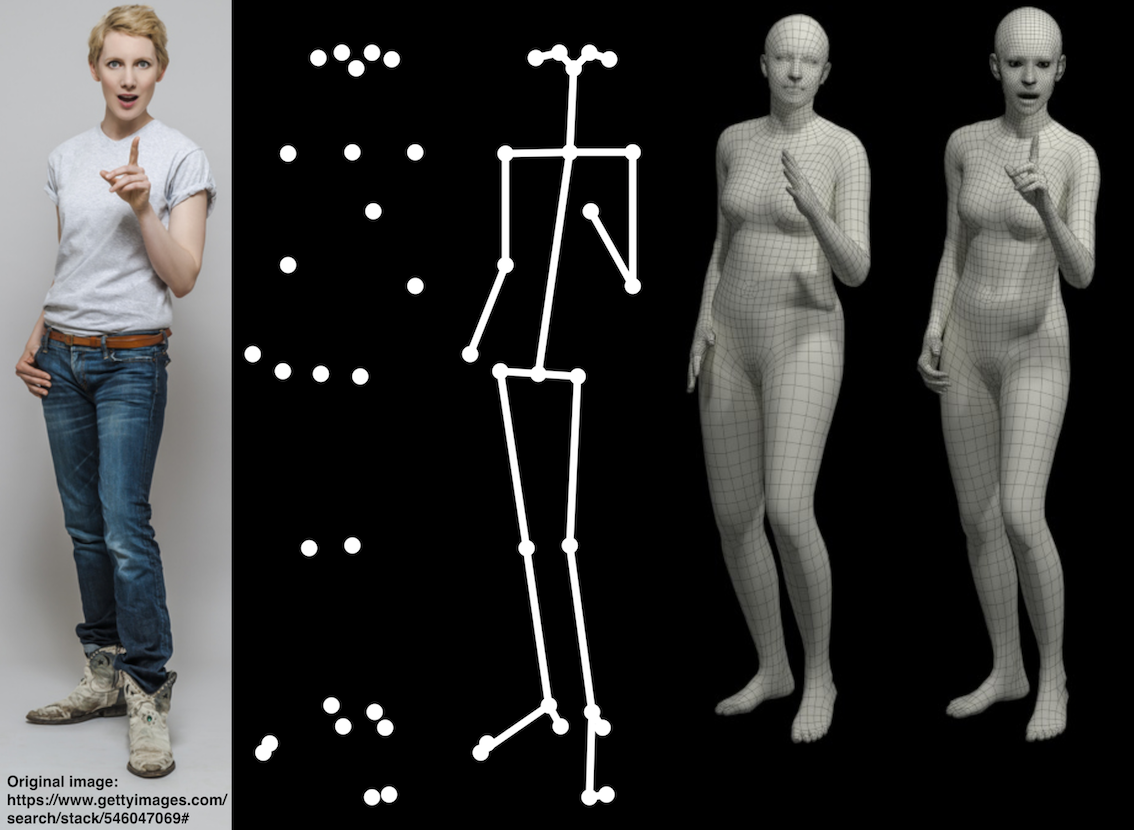
The given video input has taken by frames and the frames are given input to the pose detector of the media pipe and it will return the result that stores the landmarks of the pose from the pose tracker. The landmarks are defined by the Blaze pose which detects around 33 human key points from the body, we have another standard topology called COCO topology which consists of 17 landmarks across the torso, arms, legs, and face. However, the COCO key points only localize to the ankle and wrist points, lacking scale and orientation information for hands and feet, which is vital for practical applications like fitness and dance. The inclusion of more key points is crucial for the subsequent application of domain-specific pose estimation models, like those for hands, faces, or feet.
- Mini conda : https://docs.conda.io/en/latest/miniconda.html
- vs code (as IDE) : https://code.visualstudio.com/
- cuda tool kit : https://developer.nvidia.com/cuda-downloads
the diagram shows the project in a more detailed way:
There are two programs in the project
- the first part of the project is app, the file contains the code which display the output where the users can upload the video to transform the 3d video, the function get_in_3d() takes the video as input and takes the frames from the video and takes the landmarks from the video and gets the stream of landmarks and we convert these stream of landmarks points and connect together by connecting the points and convert into video.
steps to run
! git clone https://github.com/pkanchan15/3D_Human_Modeling_CCN/tree/main/app
! pip install -r requirements.txt
to run the program
! streamlit run app.py
2. There is a second part for the project, we would like to acknowledge the contribution the authors of the vibe (Video Inference for Human Body Pose and Shape Estimation)
Their contribution to the opensource community is used in our project where we are using their project to make 3d human body model.VIBE uses CNNs to extract image features. The output from the CNN is fed as input to the recurrent neural network, which processes the sequential nature of human motion. Then a temporal encoder and regressor are used to predict the body parameters for the whole input sequence. This whole part is referred to as the Generator(G) model. Now with the help of the AMASS dataset 3D, realistic human motion is achieved for adversarial training and build a motion discriminator(Dm). The motion discriminator takes in both predicted pose sequences along with pose sequences sampled from AMASS. The discriminator tries to differentiate between the fake and real motions by providing a real/fake probability for each input sequence which helps in producing realistic motion. The output of this method is a standard SMPL body model format consisting sequence of pose and shape parameters.
the demo_file gives the detailed instructions of how to install the nessecity libraries of the project --> 2nd part.
The file gives the access of google collab : https://colab.research.google.com/drive/1vvaSAfPpR49nqcpcIjr2vqpVc0z_Bs30#scrollTo=Rs6UTvVO6Fxf
the program requires GPU's so we used google collab for their state of art gpu's and cpu's.