Fix automerge #3900 and correct package versions in meta packages [skip-ci] #3918
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Updates conda dependencies from `0.20` to `21.06`. Authors: - Victor Lafargue (https://github.com/viclafargue) Approvers: - AJ Schmidt (https://github.com/ajschmidt8) - Dante Gama Dessavre (https://github.com/dantegd) URL: rapidsai#3898
…rapidsai#3818) The compute split kernels for classification and regression end up doing lot of work that is not required. This PR removes lot of these empty work cycles by doing following changes: 1. For computing split for a node, launch number of thread blocks proportional to number of samples in that node. Before this PR the number of thread blocks was fixed for all the nodes 2. Check if a node is leaf before launching the kernel and if it is leaf, do not launch any thread blocks for it 3. Don't call update on split, if not valid split is found for a feature 4. Skip round trip to global memory before evaluating best split, if only one thread block is operating on a node **Performance improvement observed** Classification problem on a synthetic dataset `computeSplitClassificationKernel` timings ``` branch-0.20: 22.91 seconds This branch: 5.27 seconds Gain: 4.35x ``` Regression problem on synthetic dataset `computeSplitRegessionKernel` timings ``` branch-0.20: 36.46 seconds This branch: 34.03 seconds Gain: 1.07x ``` Empty cycles is not the major performance issue in regression code, therefore we do not see large improvement currently. Authors: - Vinay Deshpande (https://github.com/vinaydes) - Rory Mitchell (https://github.com/RAMitchell) Approvers: - Rory Mitchell (https://github.com/RAMitchell) - Thejaswi. N. S (https://github.com/teju85) - Philip Hyunsu Cho (https://github.com/hcho3) - Dante Gama Dessavre (https://github.com/dantegd) URL: rapidsai#3818
…dsai#3901) Small oversight with the CMake changes, there already is a `cuml` folder in our `cpp/include`, so we were double nesting it. After the fix we're back to the old (expected) behavior, and consistent with RMM and cuDF. cc @hcho3 @wphicks Authors: - Dante Gama Dessavre (https://github.com/dantegd) Approvers: - William Hicks (https://github.com/wphicks) - John Zedlewski (https://github.com/JohnZed) - Ray Douglass (https://github.com/raydouglass) URL: rapidsai#3901
Closes rapidsai#3786. Some redundant combinations are removed and I reduced the number of samples on some unit tests that are run very often. `test_umap.py::test_umap_fit_transform_trust` is the test that takes the most time in CI. Local speed-up: - `test_umap.py`: From `273s` to `79s` - `test_dbscan.py`: From `14s` to `2s` - `dask/test_nearest_neighbors.py::test_compare_skl`: From `113s` to `31s` In total, the expected saved time is `288s` (~5 min) on the pipeline locally. Authors: - Micka (https://github.com/lowener) Approvers: - John Zedlewski (https://github.com/JohnZed) - Dante Gama Dessavre (https://github.com/dantegd) URL: rapidsai#3851
…ementaton) (rapidsai#3869) Alternative implementation of rapidsai#3862 that does not depend on rapidsai#3854 Closes rapidsai#3764 Closes rapidsai#2518 Authors: - Philip Hyunsu Cho (https://github.com/hcho3) Approvers: - Dante Gama Dessavre (https://github.com/dantegd) - Vinay Deshpande (https://github.com/vinaydes) URL: rapidsai#3869
…dsai#3890) See rapidsai#3853 (comment) Authors: - Philip Hyunsu Cho (https://github.com/hcho3) Approvers: - Dante Gama Dessavre (https://github.com/dantegd) URL: rapidsai#3890
Answers rapidsai#3041 Authors: - Victor Lafargue (https://github.com/viclafargue) Approvers: - Dante Gama Dessavre (https://github.com/dantegd) URL: rapidsai#3745
cc @raydouglass @pentschev @quasiben Authors: - https://github.com/jakirkham Approvers: - Peter Andreas Entschev (https://github.com/pentschev) - Ray Douglass (https://github.com/raydouglass) - AJ Schmidt (https://github.com/ajschmidt8) - Dante Gama Dessavre (https://github.com/dantegd) URL: rapidsai#3911
This PR adds improvements for the trustworthiness score: 1. Replaces old allocation scheme with device buffers 2. Implements binary search to speedup the `compute_rank` kernel (see rapidsai#1698) Authors: - Victor Lafargue (https://github.com/viclafargue) Approvers: - Corey J. Nolet (https://github.com/cjnolet) - Dante Gama Dessavre (https://github.com/dantegd) URL: rapidsai#3826
|
Check out this pull request on See visual diffs & provide feedback on Jupyter Notebooks. Powered by ReviewNB |
trivialfis
reviewed
Jun 1, 2021
| @@ -12,9 +12,9 @@ dependencies: | |||
| - cudf=21.08.* | |||
| - rmm=21.08.* | |||
| - libcumlprims=21.08.* | |||
| - dask-cudf=21.081.08.* | |||
| - dask-cudf=21.08.08.* | |||
There was a problem hiding this comment.
Is it a real version? 21.08.08 vs 21.08.
There was a problem hiding this comment.
dang the bulk find and replace, didn't notice that happened, thanks for noticing!
| @@ -12,9 +12,9 @@ dependencies: | |||
| - cudf=21.08.* | |||
| - rmm=21.08.* | |||
| - libcumlprims=21.08.* | |||
| - dask-cudf=21.081.08.* | |||
| - dask-cudf=21.08.08.* | |||
…ai#3895) This PR can speed up the evaluation of the log-likelihood in ARIMA by 5x for non-seasonal datasets (the impact is smaller for seasonal datasets). It achieves this by pre-allocating all the temporary memory only once instead of every iteration and providing all the pointers with a very low overhead thanks to a dedicated structure. Additionally, I removed some unnecessary copies.  Regarding the unnecessary synchronizations, I'll fix that later in a separate PR. Note that non-seasonal ARIMA performance is now even more limited by the python-side solver bottleneck: 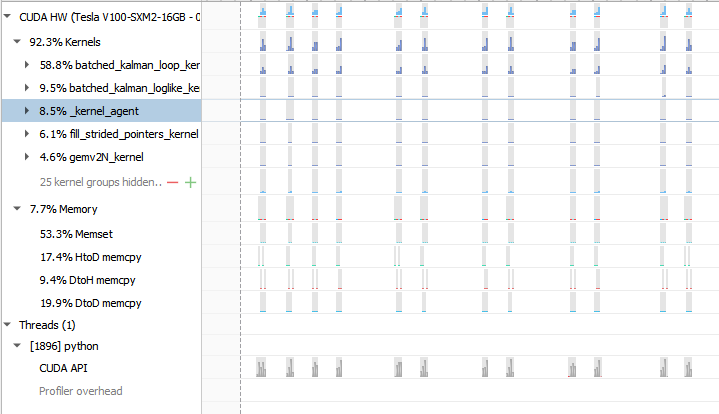 One problem is that batched matrix operations are quite memory-hungry so I've duplicated or refactored some bits to avoid allocating extra memory there, but that leads to some duplication that I'm not entirely happy with. Both the ARIMA code and batched matrix prims are due some refactoring. Authors: - Louis Sugy (https://github.com/Nyrio) Approvers: - Tamas Bela Feher (https://github.com/tfeher) - Dante Gama Dessavre (https://github.com/dantegd) URL: rapidsai#3895
{kind=link}
{kind=link}
ajschmidt8
approved these changes
Jun 1, 2021
vimarsh6739
pushed a commit
to vimarsh6739/cuml
that referenced
this pull request
Oct 9, 2023
Fix automerge rapidsai#3900 and correct package versions in meta packages [skip-ci]
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Fixing automerge conflicts of PR #3900, skipping CI until there are build meta packages