This code has been implemented in google Colab using the google GPU unit google Colab
Convolutional Neural Networks or Convnets for short are a from a Artificial Neural networks, their behaviour that differentiates them from regular Dense Neural network are
1. They can identify and recognize local patterns to build high level features
2. They can identify patterns invariantly in space.
1. What are Convnets?
2. How are they different from Deep Neural Networks (DNN) and how CNN compliment them?
3. How does a CNN do image processing?
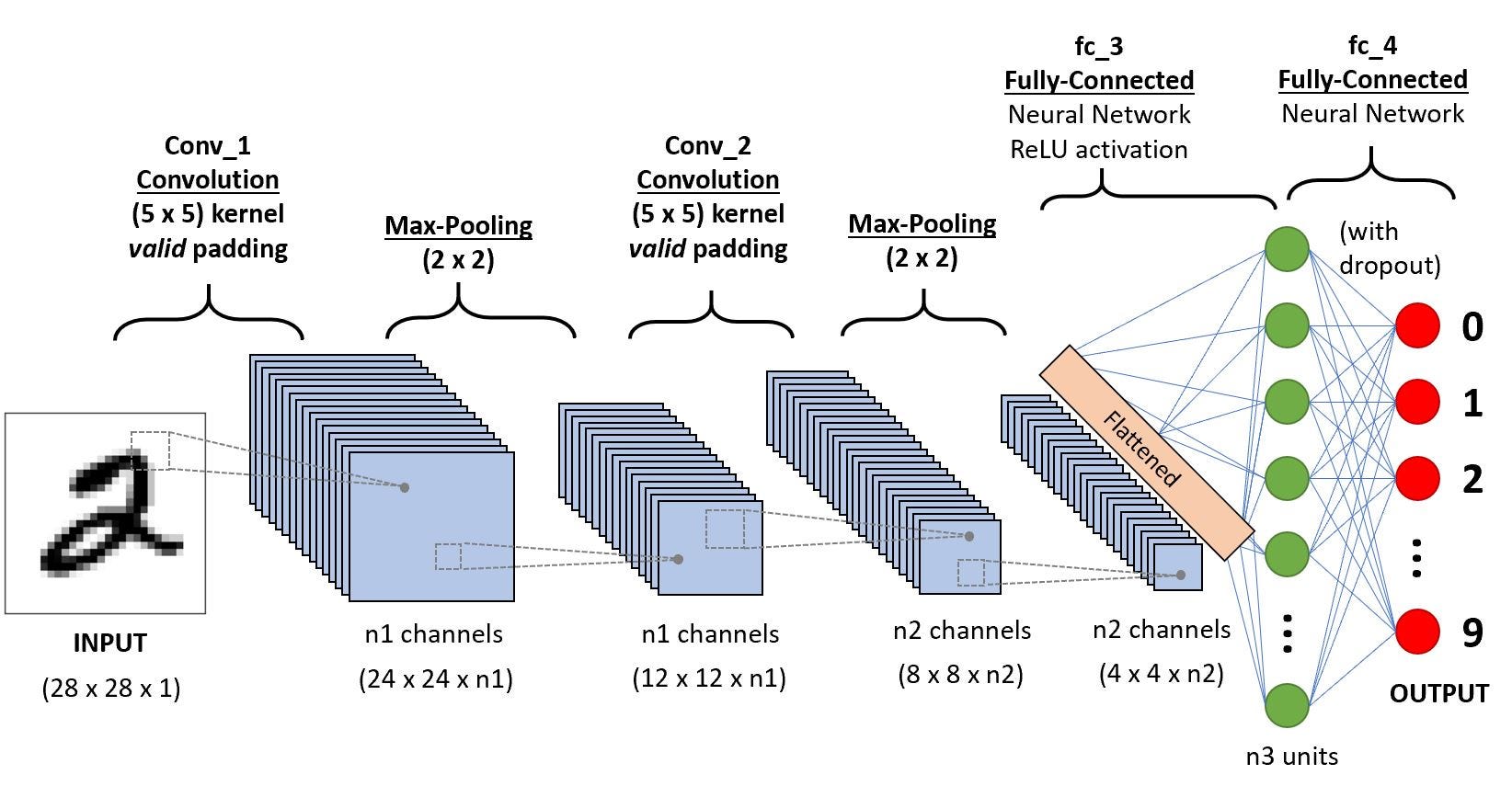
Convnets are a class of Deep neural networks which find their successful use in image/pattern recognition. As you can infer from the image above that CNN is technically a preprocessing step before the processed image is fed to the DNNs. CNN layers consist of input layer , output layer and multiple hidden layers which typically consist of activation function, pooling layers and fully connected layers. The major differences between a DNN algorithm and a CNN is
1. DNN learn from global patterns in their input feature space while CNN’s learn local
patterns.
2. The patterns that CNNs learn are translation invariant unlike DNN
3. CNN can learn Spatial hierarchies unlike DNNs.
Here you can see that the dataset has less data to train the model
total training cat images: 3001
total training dog images: 3006
total test cat images: 1012
total test dog images: 1013
total validation cat images: 1000
total validation dog images: 1000
Optimization - it is the process of adjusting the hyperparameters (# of epochs, # of layers, activation functions etc. ) to get the best performance on the training data Generalization- how well the well optimized/trained model performs on the unseen/new/test data. So, Overfitting is basically when the model starts to learn new parameters on the training data but are mis-leading or irrelevant when it comes to new data
Regularization- so,to avoid overfitting of the data we use regularization which means we modulate the quantity of information that our mode is allowed to store or adding constraints on what informtion is allowed to be stored. That means if the network is allowed to only store a small number of patterns , the optimization process will force it focus only on those patterns which have a better chance of generalizing well. Reducing the size of the network the simplest way to avoid overfitting is to reduce the siz of the model. Size of the model means the number of learnable parameters in the model ( # of layers and # of units in the layer), which refers to the models capacity. So, a model with more learnable parameters has more memorization capacity.
By reducing the number of learnable parameters, the model won't be able to learn things easily so, it would resort to learnig compressed representations that have predictive power regarding the targets. But at the same time we have to keep in mind that not having enough learnable parameters might result in underfitting So, a good idea would be understand too much capacity and not enough capacity.
So, the strategy would be to try an array of network architectures on your validation data in order to find the correct size for your model. And the general workflow would be start with a relatively few layers and parameters and increase the size of layers or add new layers untill you see signs of diminishing returns wrt validation loss.
As we know that data should be transformed into an appropriately preprocessed floating point tensors before being fed to the network. Our data currently is in the form of jpg images so we need to transform it to the desired input form.
1. Read the picture files
2. Decode the picture content to RGB grid of pixels
3. convert these to folating point tensors.
4 Rescale values between [0,1] as the neural nets find it easier to deal with small numbers.
So, Since Keras is a great library it does provide us with image pre-processing helper tools located at keras.preprocessing.image named a class called "ImageDataGenerator".
It can automatically convert the images on disk into batches of preprocessed tensors.
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255) #rescale all images [0,1]
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
"/content/cats_vs_dogs_data/training_set",
target_size=(150,150),
batch_size=20,
class_mode="binary")
validation_generator = validation_datagen.flow_from_directory(
"/content/cats_vs_dogs_data/validation_set",
target_size=(150,150),
batch_size=20,
class_mode="binary")
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Conv2D(32, (3,3), activation="relu",
input_shape=(150,150,3))) # you'll see later that we will resize all image to 150x150
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512,activation="relu"))
model.add(layers.Dense(1,activation="sigmoid"))model.summary() # to get the summary of the modelusing "RMSprop" as the optimizer/minimizer of the error function. Since you are using sigmoid as the activation in the final layer we'll use binary crossentropy as the loss metric
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=1e-4),
loss='binary_crossentropy',
metrics=['acc'])history = model.fit_generator(
train_generator,
steps_per_epoch=250,
epochs=30,
validation_data=validation_generator,
validation_steps=100)
model.save('cats_dogs_1.h5')import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history["val_acc"]
loss = history.history['loss']
val_loss = history.history["val_loss"]
epochs = range(1,len(acc)+1)
plt.plot(epochs, acc,"bo",label="Training acc")
plt.plot(epochs, val_acc,"b",label="Validation acc")
plt.title("Training and Validation accuracy")
plt.legend()
plt.figure()
plt.plot(epochs, loss,"bo",label="Training loss")
plt.plot(epochs, val_loss,"b",label="Validation loss")
plt.title("Training and Validation loss")
plt.legend()
plt.show()
##Overfitting:
As you can see that the training accuracy goes on increasing while the validation accuracy stalls aroud 75%, which is just ok. but if you look at the loss plot, you see that the training loss goes on decreasing but the validation loss hits its minimum aat around 14 epochs but after that loss goes on increasing which indicates overfitting of the model
in order to avoid this we will use Data Augmentation. We can also use dropout and L2 regularization but for now we'll focus on data augmentation to tackle over fitting, which is more suitable for overfitting related to visual recognition
It is the process of generating more training data from existing training samples. this process uses a number of transformations on the existing images to yield new samples for training. The goal of augmentation is first increase the number of samples scuh that the model doesn't see the image twice while training. In Keras augmentation is done by using a combination of transforamtion( to be applied on the images) via the ImageDataGenerator instance.
avoiding overfiitting but really?
So, eventhough your model would never see the same mage twie but your augmented images are just slight transmations from the real image so, they still have high corellation which might be a factor for overfitting , that;s one of the reason we use Dropout to avoid this.
datagen = ImageDataGenerator(
rotation_range =40,# is a value in degree between[0-180] to randomly rotate pictures
width_shift_range = 0.2, #horizontally translate picture in space
height_shift_range = 0.2, #vertically translate picture in space
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode="nearest"
)



from keras.preprocessing import image
fnames = [os.path.join(training_cats_dir, fname) for
fname in os.listdir(training_cats_dir)]
img_path = fnames[9]
img = image.load_img(img_path, target_size=(150,150))
x= image.img_to_array(img)
x = x.reshape((1,) +x.shape)
i=0
for batch in datagen.flow(x,batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i%4 ==0:
break
plt.show()Augmentation is not going to entirely solve the overfitting problem so, we have to use dropout in the new model.
so, let's make a new model adding dropout as well.
model1 = models.Sequential()
model1.add(layers.Conv2D(32, (3,3), activation="relu",
input_shape=(150,150,3))) # you'll see later that we will resize all image to 150x150
model1.add(layers.MaxPooling2D((2,2)))
model1.add(layers.Conv2D(64,(3,3),activation='relu'))
model1.add(layers.MaxPooling2D((2,2)))
model1.add(layers.Conv2D(128,(3,3),activation='relu'))
model1.add(layers.MaxPooling2D((2,2)))
model1.add(layers.Conv2D(128, (3,3), activation='relu'))
model1.add(layers.MaxPooling2D((2,2)))
model1.add(layers.Flatten())
model1.add(layers.Dropout(0.5))
model1.add(layers.Dense(512,activation="relu"))
model1.add(layers.Dense(1,activation="sigmoid"))model1.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=["acc"])train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
validation_datagen = ImageDataGenerator(rescale=1./255) # we shouldn't augment the validation data
train_generator = train_datagen.flow_from_directory(
"/content/cats_vs_dogs_data/training_set",
target_size=(150,150),
batch_size=20,
class_mode="binary")
validation_generator = validation_datagen.flow_from_directory(
"/content/cats_vs_dogs_data/validation_set",
target_size=(150,150),
batch_size=20,
class_mode="binary")
history = model1.fit_generator(
train_generator,
steps_per_epoch=250,
epochs=30,
validation_data=validation_generator,
validation_steps=100)model1.save('cats_dogs_2.h5')import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history["val_acc"]
loss = history.history['loss']
val_loss = history.history["val_loss"]
epochs = range(1,len(acc)+1)
plt.plot(epochs, acc,"bo",label="Training acc")
plt.plot(epochs, val_acc,"r",label="Validation acc")
plt.title("Training and Validation accuracy after regularization")
plt.legend()
plt.figure()
plt.plot(epochs, loss,"bo",label="Training loss")
plt.plot(epochs, val_loss,"r",label="Validation loss")
plt.title("Training and Validation loss after regularization")
plt.legend()
plt.show()

So, As you can see from above that we have sigificationlt reduced overfitting
1. for understanding how different convnet layers transform their input
2. meaning of individual convnet filters
So, what we are trying to do here is that we want to see how the input is decomposed into different filters learned by the network.
from keras.models import load_model
model2 = load_model('cats_dogs_2.h5')
model2.summary()let's see how the follwing image behaves in layer of the CNN
[test.png]
from keras import models
layer_outputs = [layer.output for layer in model.layers[:8]]
activation_model = models.Model(inputs=model.input, outputs=layer_outputs)
activations = activation_model.predict(img_tensor)
first_layer_activation = activations[0]import keras
# These are the names of the layers, so can have them as part of our plot
layer_names = []
for layer in model.layers[:8]:
layer_names.append(layer.name)
images_per_row = 16
# Now let's display our feature maps
for layer_name, layer_activation in zip(layer_names, activations):
# This is the number of features in the feature map
n_features = layer_activation.shape[-1]
# The feature map has shape (1, size, size, n_features)
size = layer_activation.shape[1]
# We will tile the activation channels in this matrix
n_cols = n_features // images_per_row
display_grid = np.zeros((size * n_cols, images_per_row * size))
# We'll tile each filter into this big horizontal grid
for col in range(n_cols):
for row in range(images_per_row):
channel_image = layer_activation[0,
:, :,
col * images_per_row + row]
# Post-process the feature to make it visually palatable
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image, 0, 255).astype('uint8')
display_grid[col * size : (col + 1) * size,
row * size : (row + 1) * size] = channel_image
# Display the grid
scale = 1. / size
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid, aspect='auto', cmap='viridis')
plt.show()


