Serlo Infrastructure for Non programmers
This article is intended for everyone that does not have a background in programming. If you are a programmer and want a more detailed and technical description of the Serlo Infrastructure, see this article.
Simplified, the Serlo Infrastructure looks like this:
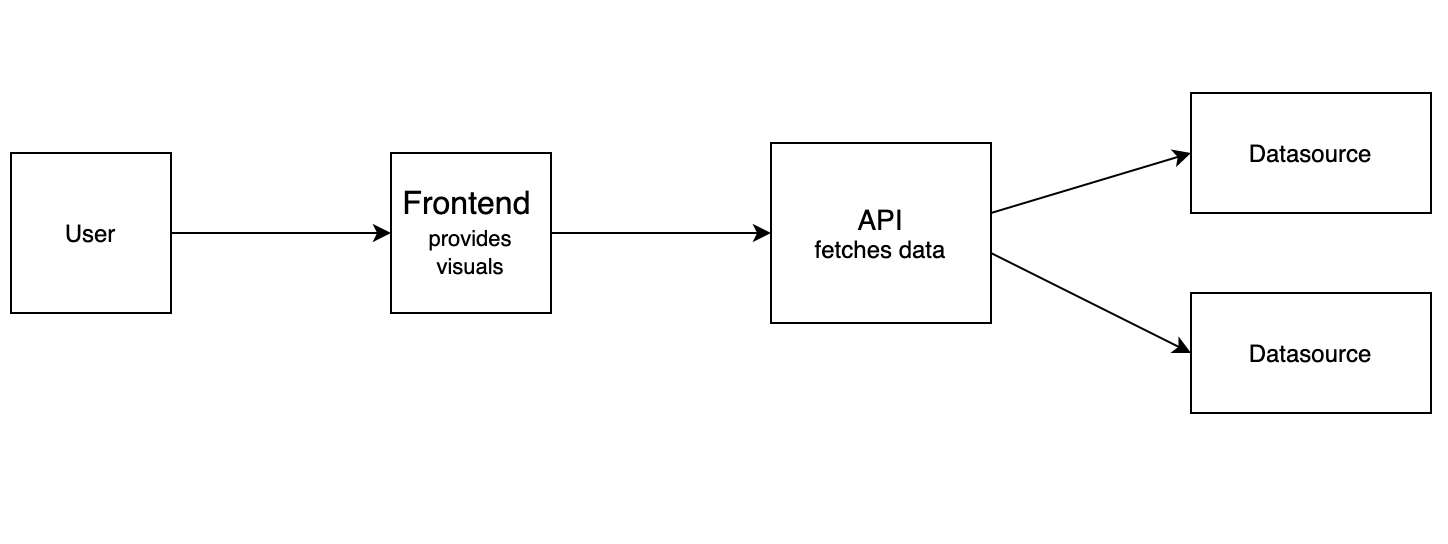
Please note that some components of the infrastructure are left out for simplification. The goal is to give a broad overview about how the system works, not to accurately explain every building block.
To illustrate how this process works, let's look at an example. Let's say you found an article on serlo.org that you really like and you would like to leave some kudos for the author in the comments.

The visuals that you can see on the page right now, like the colors, the functionality and arrangement of the buttons, the line where you can enter text and so on... are created by the frontend. If you now decide to leave this comment saying "Good job!" and you click the button saying "Abschicken", the frontend will send only the text you entered and your user number (as well as some other not so exciting data) to the API. The API is a kind of middle man that knows how to handle requests for data that are either incoming or outgoing. It can talk to the frontend and now knows that there is a comment incoming. Since we programmed it with instructions on how to deal with this scenario, the API knows exactly what to do. It sends the text "Good job!", the user number and the other attached information to our database, where it is filed in a table that stores data about comments. This data is now ready to be viewed by every new user that looks at this page. Now we know how new data is stored. But what about retrieving existing information? Every time an article (or any page on serlo.org) is called upon, it sends a lot of requests to the API for retrieval of data. In our case, the request for the comment you just left is among them. The API handles the request and fetches the comment from the comment table in our database. Then, it sends it back to the frontend, where the data is rendered and displayed. The process for showing the content of the articles, notifications or other types of content on serlo.org works the same way.
The way our infrastructure is built is called microservice architecture, meaning that we use small building blocks to implement the Serlo Platform. But this was not always the case. Previously, we used only one large service written in a programming language called PHP (a monolith). However, over time this grew too big, too slow and it was very hard to develop new features and find bugs. So we switched to a microservice architecture to be more flexible, faster and find mistakes quicker. And these are not even the only advantages. Different parts of the structure can be written in the programming language which is best suited for the specific task. For example the frontend is written in JavaScript, while the API is written in TypeScript. Independent teams can then work on these parts without having to know everything about the other building blocks. This way everyone can contribute with what they know best. Additionally, this makes it easy to switch out a module that is not working properly without disturbing the rest of the infrastructure. Smaller chunks of code make spotting mistakes easier and the modules become better to handle in general. Ultimately, we also have tests implemented that alert us in case we broke anything when changing code for developing new features. Testing code is very useful in general, since it prevents faulty software from going live. And it is much easier to test small chunks of code individually as opposed to testing a large monolith. If you want to see how our software architecture grew and changed over time from one monolith to a microservice architecture you can see it visualized in this video.
The frontend renders data that it was provided with by the API to a web page. It is built with next.js. This is a framework in the programming language JavaScript that allows for an easy and fast user experience as well as for quickly developing new features.
Our middle man, the API is very flexible and can be given instructions to look for or store data in different kinds of data storage. Right now, we are using an SQL database, but if for some reason we need to switch to a different service, we could easily do this without changing anything in the frontend. We just need to give the API different instructions, where to look for the information. The website would look just the same, even though in the background the infrastructure will have changed quite substantially. It can also deal with more than one datasource. For example we also use it to interact with Google Spreadsheets. If we need to add more, we can easily do this in the future. This type of infrastructure is called microservice architecture, since many small parts are responsible for specific tasks instead of one large structure that handles everything. The API is implemented in the programming language TypeScript (a programming language that is based on JavaScript).
We store our data in an SQL server that basically saves the data in big tables that look like this:

Entries are organised by ids, which are unique numbers generated by us. For example when a user first registers and creates a profile, we generate a unique user number. All the data that accompanies this user (e. g. user name, e-mail) will be filed in the user table under the unique user number. These numbers can also be used in other tables with different data in them (e.g. information about comments). This way, the data can be organised in smaller, more efficient tables and the user number is used to link all the information together.