{kind=link}
This package implements Low-Rank Adaptation (LoRA), a popular method for fine-tuning large language models. LoRA introduces a more efficient method for adaptation by freezing the original model weights and injecting trainable rank decomposition matrices. This results in a dramatic reduction in the number of parameters needing updates and cuts down on the GPU memory needed, making it a much more affordable and practical solution for users who don’t have access to high-end GPU hardware.
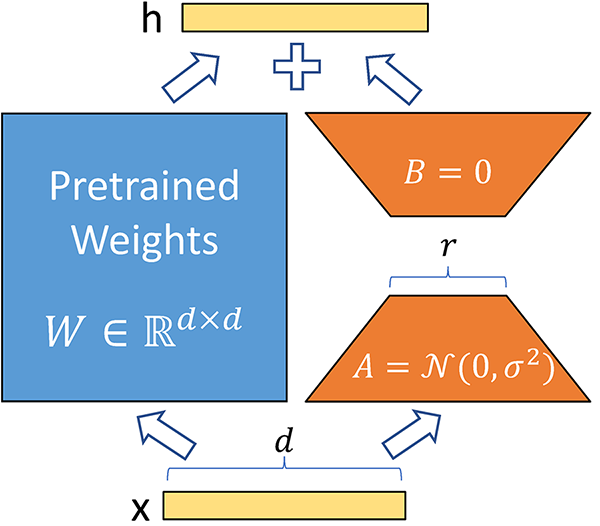
- Efficiency: LoRA decreases the number of trainable parameters by up to 10,000 times and reduces GPU memory usage by 3 times compared to traditional fine-tuning methods.
- Performance: Despite the reduction in trainable parameters, LoRA exhibits comparable or even superior performance to full fine-tuning on various models (RoBERTa, DeBERTa, GPT-2, GPT-3) across different benchmarks.
- Storage Space: LoRA parameters are impressively compact, taking up only a few megabytes.
View the notebooks directory to see an example of how to fine-tune, and perform text generation using LoRA adapters.
In general,
- Import your model
- Freeze your model
- Inject trainable LoRA parameters
{:ok, model} = Bumblebee.load_model({:hf, "gpt2"})
lora_model =
model
|> Axon.freeze()
|> Lorax.inject(%Lorax.Config{
r: 2,
alpha: 4,
dropout: 0.05,
target_query: true,
target_key: true,
target_value: true
})
# train model
The default configs target only the query and value matrices. r is set to 1, alpha to 2.
The original LoRA paper found that configuring query and value matrices was effective enough for fine-tuning. Furthermore, even an r value of 1 is enough to fine-tune a model. Though in practice I found that it's necessary to use r values of 2, 4, or 8.
These settings are for an A10 small w/ 24gb vRAM
Lora Config
- r value of at least 2
- alpha value is r*2
- batch size = 4
- sequence_length = 512
Training
- learning_rate of 3.0e-4
Text Generation
- multinomial sampling
- p = 0.06 or 0.08 for more variety (or if you experience repetitive results)
The authors behind the LoRA paper also noted that targeting nodes outside of QKV like the self attention output can be beneficial to approach the results of full-finetuning.
Here's how you could target only the output node.
lora_model =
model
|> Axon.freeze()
|> Lorax.inject(%Lorax.Config{
r: 2,
alpha: 4,
dropout: 0.1,
target_node_fn: fn %Axon.Node{name: name_fn} ->
# names are generated lazily, and look like "decoder.blocks.11.self_attention.value"
# have to invoke the function to see what layer the node represents
# https://github.com/elixir-nx/axon/blob/v0.6.0/lib/axon.ex#L3923
name = name_fn.(nil, nil)
shortname = String.split(name, ".") |> List.last()
if shortname == "output" do
true
else
false
end
end
})
While the LoRA algorithm significantly reduces the GPU requirements for fine-tuning a model, using LoRA on LLMs that are bigger than GPT2 still requires a GPU with high vRAM. Most of the examples here were fine-tuned on an A10G on Huggingface Spaces. Attempting to fine-tune Mistral 7B on Huggingface's A10x4 (the largest available w/ 96 vRAM) will cause cuda OOM errors. To fine-tune on consumer GPUs, quantization work needs to be done to implement the QLoRA algorithm.
If available in Hex, the package can be installed
by adding lorax to your list of dependencies in mix.exs:
def deps do
[
{:lorax, "~> 0.1.0"}
# or
{:lorax, git: "https://github.com/spawnfest/lorax.git"},
]
endDocumentation can be generated with ExDoc and published on HexDocs. Once published, the docs can be found at https://hexdocs.pm/lorax.