Please feel free to add me here on LinkedIn if you are interested in data science and like to connect.
Interactive Machine Learning (with IPython Widgets)




{kind=link}
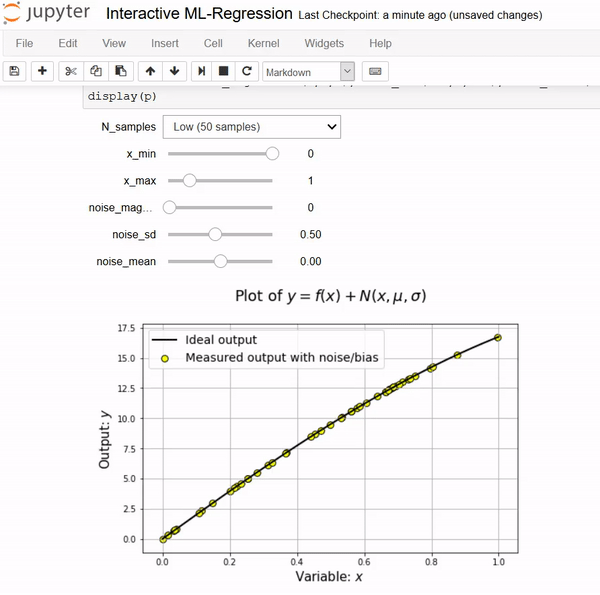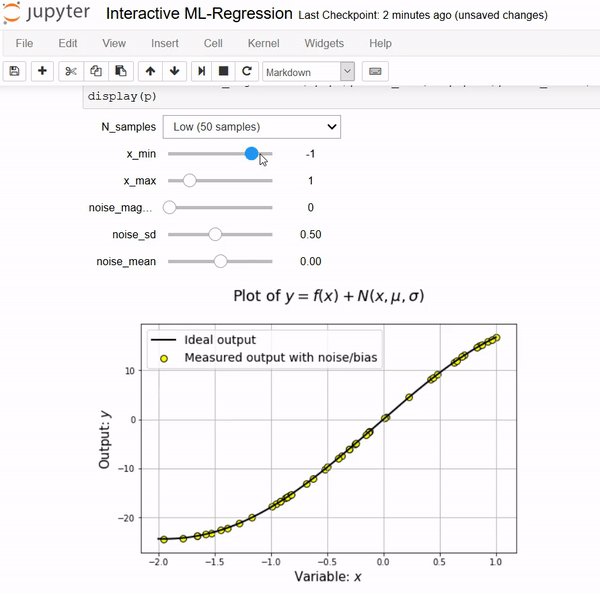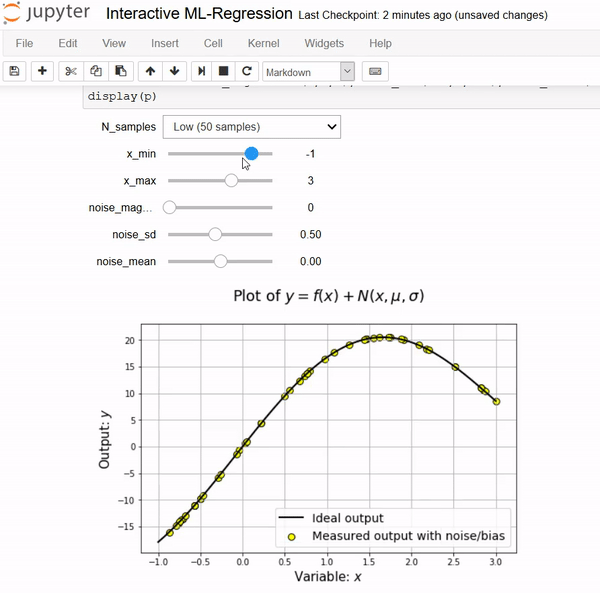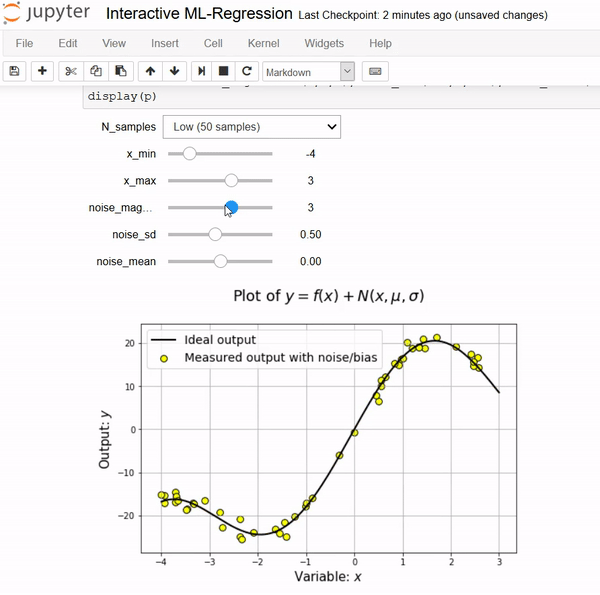
Notebooks come alive when interactive widgets are used. Users can visualize and control changes in the data and the model. Learning becomes an immersive, plus fun, experience.
Project Jupyter was born out of the IPython Project in 2014 and evolved rapidly to support interactive data science and scientific computing across all major programming languages. There is no doubt that it has left one of the biggest degrees of impact on how a data scientist can quickly test and prototype his/her idea and showcase the work to peers and open-source community.
However, learning and experimenting with data become truly immersive when user can interactively control the parameters of the model and see the effect (almost) real-time. Most of the common rendering in Jupyter are static. However, there is a big effort to introduce elements called ipywidgets, which renders fun and interactive controls on the Jupyter notebook.
Widgets are eventful python objects that have a representation in the browser, often as a control like a slider, textbox, etc., through a front-end (HTML/Javascript) rendering channel.
We demonstrate simple linear regression of single variable using interactive control elements. Note, the idea can be extended for complex multi-variate, nonlinear, kernel based regression easily. However, just for simplicity of visualization, we stick to single variable case in this demo.
First, we show the data generation process as a function of input variables and statistical properties of the associated noise.
Next, We introduce interactive control for the following hyperparameters.
- Model complexity (degree of polynomial)
- Regularization type — LASSO or Ridge
- Size of the test set (fraction of total sample data used in test)
User can interact with the linear regression model using these controls. Note, how the test and training scores are also updated dynamically to show a trend of over-fitting or under-fitting as the model complexity changes. One can go back to the data generation control and increase of decrease the noise magnitude to see its impact on the fitting quality and bias/variance trade-off.
Check this article I wrote on Medium about this project.