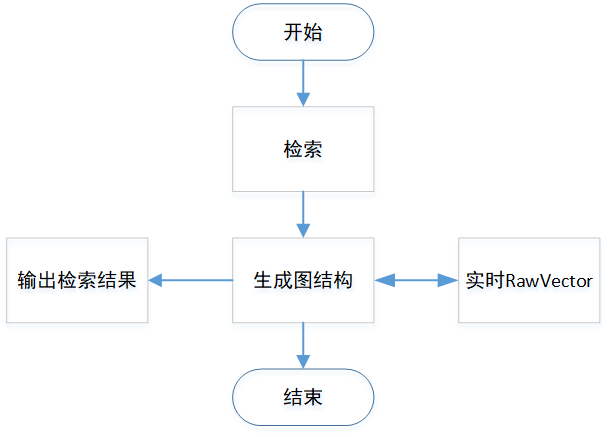
Hnsw实时索引详细设计
HNSW——Hierarchical NSW (分层的NSW算法),由Malkov 等人于2016发表的论文Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs,是关于近似k近邻搜索的一种新的图算法,是对NSW (Navigable-Small-World-Graph)方法的改进,它由多层的邻近图组成,因此称为分层的NSW方法。具有查询精度高以及查询速度快等特点,对于高维数据也有很好的效果。但是无论是原作者开源的HNSW算法hnswlib https://github.com/nmslib/hnswlib 、还是经典的相似搜索库faiss中的hnsw https://github.com/facebookresearch/faiss 等算法,均未实现实时的HNSW算法,在构建索引的时候并不能进行查询,这样查询的时候就会受限制,因此实现实时的HNSW算法是很有必要的。下面介绍vearch https://github.com/vearch/vearch 中实现的实时HNSW算法,让插入和搜索能够同时进行,这样在构建索引的时候也可以进行查询。
NSW 通过设计出一个具有导航性的图来解决近邻图发散搜索的问题,但其搜索复杂度仍然过高,达到多重对数的级别,并且整体性能极易被图的大小所影响。HNSW在此基础上结合skip-list的思想,提出分层的结构。HNSW的结构如下图所示:
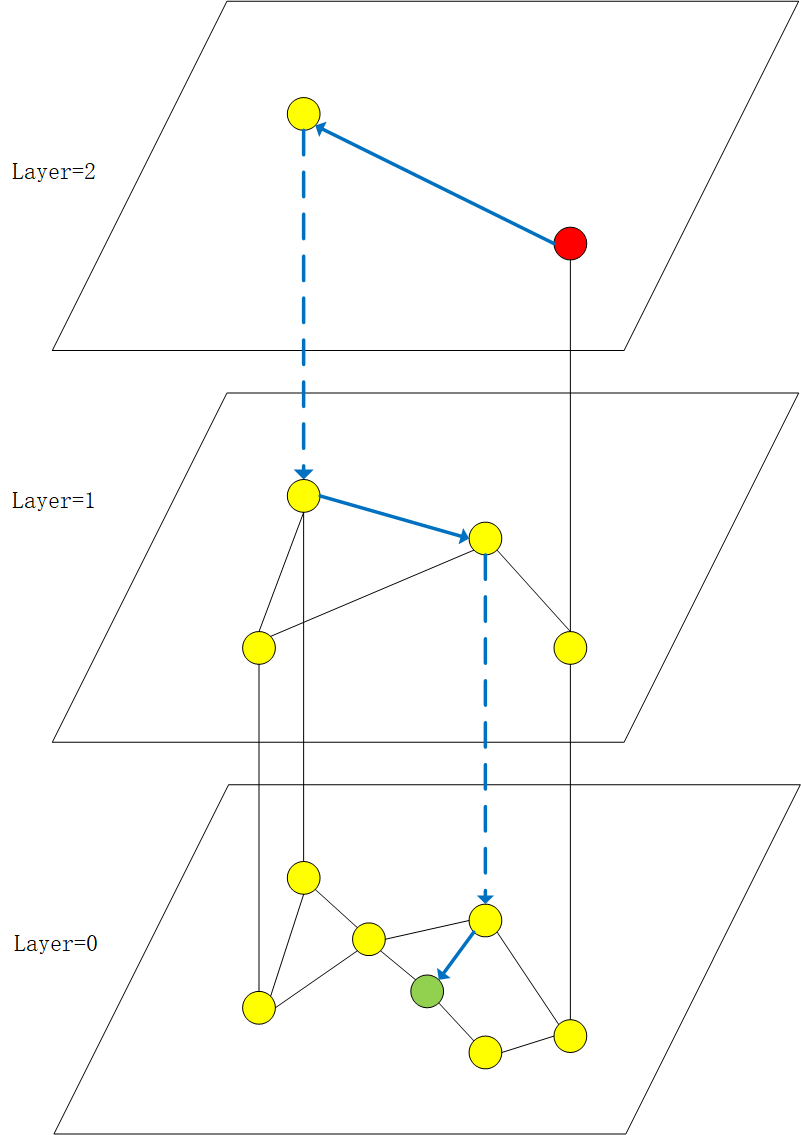
在构建图的过程中,每个节点会预先计算它的度,也就是它会在图中出现的最高层,如某个节点度为1,那么它会出现在0、1两层,也就是说第0层会拥有所有的数据,并且数据的分布是层数越高数据越少,节点之间的距离越大,同时高层拥有的节点是非常少的,这样搜索进入会非常快,能够减少搜索时需要遍历的节点数。
搜索的时候,会从最高层的进入点进入,然后利用贪婪算法在层间找到局部最近邻之后跳到下一层,重复这个过程到达第0层,在第0层开始真正的搜索。搜索时维护一个堆来存储最近的节点,在第0层的进入点开始搜索它的所有邻接点并判断是否要插入到堆中,记录所有邻接点中到查询点最近的节点作为下一个起点,重复上面的过程,直到查询的结果满足条件时结束查询。如上图中的红点和蓝色的线条所示,红点表示图的进入点,搜索从红点开始,蓝色实线表示在层间寻找局部最近邻,蓝色虚线表示经过层间跳跃进入下一层,重复这个过程,在第0层找到绿色的点即表示完成了一次搜索。
对于数据的插入过程,在构建某个节点的邻接关系的时候,同样是逐层进行的。如某个节点的度是1,这样该节点只会在第0、1层出现,只需要在这两层构建该点的邻接关系即可。插入的时候首先会从最高层的进入点进入索引图,如图从最高层的红点出发,通过贪婪算法找到它的局部最近点之后,由此点进入第一层,在第一层构建好邻接关系之后,同样经过贪婪算法找到局部最近邻之后进入第0层开始构建邻接关系。
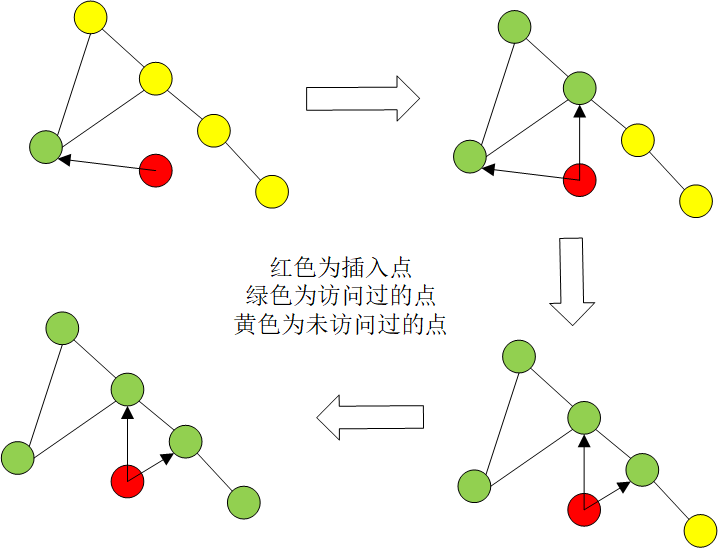
在某一层构建邻接关系的时候,会维护一个候选点列表和一个结果列表、以及一个访问节点列表来标记访问过的点来减少重复搜索。候选点列表记录所有可能的候选点,结果列表保存插入点的所有邻接点。候选点列表记录访问过的点,从进入点开始搜索它的所有邻接点,看是否已经访问过这些节点,没有访问过并且这些节点距离更近则将这些点插入到候选点列表中,同时将这些距离更近的点插入到结果列表,然后从候选点列表中找到最近的节点重新出发遍历所有的邻接点,不断重复上述过程,直到候选点列表为空时结束遍历,过程中满足条件的节点存储到结果列表并筛选最近的M个节点作为该插入点的邻接点。过程如下图所示。
实时HNSW算法
可以看到,实时插入和搜索会出现一种情况,那就是插入的时候HNSW图会插入新节点来扩展,存储图的结构会出现扩容的情况,如faiss中利用std::vector来存储节点的邻接点,一旦出现扩容的情况,之前的vector内部的存储结构就会发生变化,这个时候如果有搜索的话那么会因为搜索访问到扩容之前的失效的结构而出现程序崩溃的问题,因此会在插入和搜索的时候加上锁来保护同时进行插入和搜索的情况。
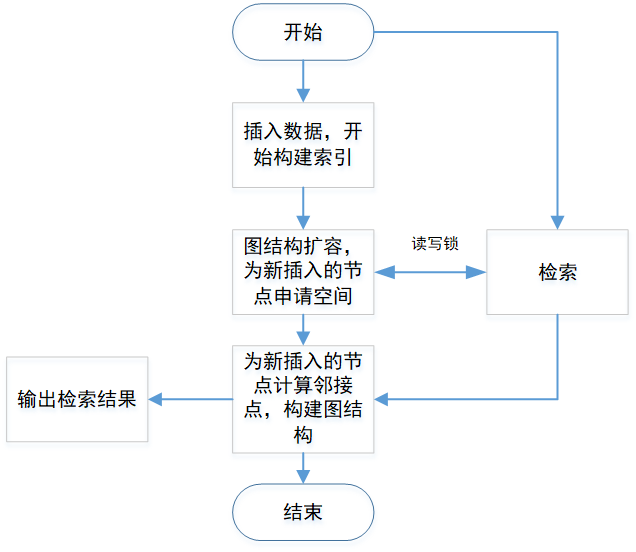
可以看到同时插入和搜索的过程中,读写锁只锁住了图结构扩容的部分,而这部分的耗时对于构建索引来说是很小的,构建索引更多的耗时是在为新插入的节点计算邻接点的部分,因此整个读写锁的粒度很小,不会明显影响搜索的性能。
另外查询的时候会需要一个结构能够读取到所有节点的特征信息来计算距离,如faiss中定义一个DistanceComputer来访问所有节点的特征信息,利用VisitedTable来标记所有访问过的点,但是实时搜索的时候,查询有可能会遇到新的插入点,然后通过DistanceComputer去查找对应的特征,但是DistanceComputer却不是能够动态扩展的,无法获取新的插入点的信息,因此会出现越界的情况。而在vearch中的HNSW算法通过RawVector来获取所有的特征向量信息,raw_vector能够实时插入,这样就避免了越界的情况。另外RawVector部分的设计可以参考RawVector部分的文档说明。结构如下图所示。