REST API 에 대해서 아는대로 설명해주세요.
REST API 란 자원, 행위, 표현 으로 이루어져 있습니다. HTTP URI를 통해 자원을 표시하고 HTTP Method를 통해 자원에 대한 처리를 표현합니다.
URI 는 정보의 자원을 표현해야 한다.자원에 대한 행위는 HTTP Method GET, POST, DELETE, PUT로 표현한다.- Reference : https://meetup.toast.com/posts/92
HTTP Status Code 아는 거에 대해서 설명해주세요.
- 200 OK : 요청 성공
- 201 Created: 요청이 성공적이었으며 그 결과로 새로운 리소스가 생성되었다.
- 204 No Content: 요청에 대해서 보내줄 수 있는 컨텐츠가 없다.
- 400 Bad_Request: 클라이언트의 잘못 요청으로 서버가 이해할 수 없음
- 401 UnAuthorized: 인증되지 않은 사용자를 의미
- 403 Forbidden: 인증은 되었지만 해당 자원에 대해서 권한이 없는 경우
- 404 Not Found: 서버는 요청받은 리소스를 찾을 수 없다.
- 405 Method Not Allowed: GET 메소드인데 다른 HTTP 메소드로 호출한 경우
- 500 Internal Server Error : 서버 내부 에러
OAuth 에 대해서 설명해주세요.
OAuth는 제 3자 인증방식 입니다. 기본적으로 사용자는 서버를 신뢰할 수 없습니다. 그렇기 때문에, 민감정보를 작성하는 것을 꺼립니다. 서버측에서도 마찬가지 입니다. 사용자의 민감정보를 관리하는 것은 리소스가 필요합니다.
그래서 OAuth를 사용해서 신뢰할 수 있는 서버에게 정보를 맡겨놓고 접근할 수 있는 권한을 주는 것이라고 이해하면 됩니다. 그러면 사용자 측에서는 민감정보를 굳이 입력하지 않고도 서비스를 사용할 수 있고, 서버측에서도 민감정보를 굳이 관리하지 않아도 되기 때문에 이점이라고 볼 수 있습니다.
즉, 인증을 자체 서비스에서 하지 않고 Third Party 를 통해서 진행하고 자체 서비스의 접근 권한을 주는 것입니다.
ex) Naver Login (Social Login)
JWT 가 무엇인지 설명해주세요.
JWT란 토큰 인증 방식에서 쓰이는 것이라고 볼 수 있습니다. 다른 사용으론 데이터를 공유하는데도 사용할 수 있지만 일반적으론 토큰 인증 방식에서 사용됩니다.
JWT는 헤더, 페이로드, 시그니쳐로 구분됩니다. 헤더는 토큰의 타입, 암호화 알고리즘을 담고 있고, 페이로드는 토큰의 정보를 담는 부분이며, 시그니처는 토큰의 정보가 신뢰할 수 있는것인지 판단할 수 있도록 합니다.
JWT는 세션 기반 인증과 주로 대비됩니다. 세션기반 인증은 서버에서 세션 정보를 관리해야하는 비용이 들게됩니다. 또한 분산환경에서도 관리하기 어렵습니다. 하지만 JWT는 그 자체로 정보를 가지고 있기 때문에 세션의 단점을 보완할 수 있습니다.
-
Payload 인코딩: 페이로드(Payload) 자체는 암호화 된 것이 아니라, BASE64로 인코딩 된 것입니다. 중간에 Payload를 탈취하여 디코딩하면 데이터를 볼 수 있으므로, JWE로 암호화하거나 Payload에 중요 데이터를 넣지 않아야 합니다.
-
JWT토큰 생성 알고리즘은 크게 대칭키/비대칭키 2가지로 구분할 수 있습니다.
- 대칭키 사용: HS256(HMAC + SHA256)
- 비대칭키 사용:RS256(RSA + SHA256) , ES256(ECDH + SHA256)
GET, PUT, POST, PATCH 사용법에 대해서 설명해주세요.
- PUT : 해당 리소스에 대해서 전체 수정이 필요하다면 PUT 을 사용
- POST: Request Body 가 필요하다 거나 서버의 자원 행위를 변경할 때 주로 사용
- PATCH: 해딩 리소스에 일부 수정이 필요할 때는 PUT -> PATCH 를 사용
- GET: 주로 읽어 오는 작업을 할 때 사용
GET vs POST 차이점에 대해서 설명해주세요.
-
- 요청은 서버에 존재하는 정보를 요청합니다.(조회 API 에 주로 사용)
- 일반적으로 Request Body는 입력하지 않는 것이 일반적
-
- POST 요청은 서버에 정보를 생성하는 것을 요청
- POST 요청은 서버의 상태를 변경시키기 때문에 멱등성이 유지되지 않습니다.
- 보통 Request Body에 요청하는 데이터를 담아 전송합니다.
PUT vs PATCH 차이점에 대해서 설명해주세요.
PUT : 리소스 전체를 변경할 때 사용PATCH : 리소스 일부를 변경할 때 사용
쿠키와 세션의 차이점이 무엇인가요?
HTTP는 비상태성(Stateless) 프로토콜로 상태 정보를 유지하지 않습니다. 연결을 유지하지 않기 때문에 리소스 낭비가 줄어드는 것은 큰 장점이지만 통신할 때마다 매번 연결 설정을 해야 하며, 이전 요청과 현재 요청이 같은 사용자의 요청인지 알 수 없다는 단점이 존재합니다.
쿠키와 세션을 통해서 HTTP의 Stateless한 문제점을 해결할 수 있다.
[저장 위치]
쿠키 : 클라인어트의 웹 브라우저가 지정하는 메모리 or 하드 디스크 세션 : 서버의 메모리
[리소스]
쿠키 : 클라이언트에 저장되고 클라이언트의 메모리를 사용하기 때문에 서버 자원을 사용하지 않는다. 세션 : 서버에 저장되고, 서버 메모리로 로딩되기 때문에 세션이 생길 때마다 리소스를 차지한다.
[보안]
쿠키 : 클라이언트에 저장하기 때문에 보안에 취약하다. 세션 : 서버에 저장하기 때문에 쿠키에 비해서는 보안에 우수하다.
CORS 에 대해서 설명해주세요.
-
URL을 보면 Protocol, Host, Port 번호를 모두 합친 것이 출처(Origin)입니다.두 개의 출처가 같다는 것은 Scheme, Host, Port 이 3가지가 동일하다는 뜻입니다. 프론트엔드와 백엔드의 출처가 다를 때, 다른 출처로 자원을 요청하면 SOP 에러가 납니다. 즉,CORS를 서버에서 허용해주어야 에러를 해결할 수 있습니다. -
서로 다른 도메인간에 자원을 공유하는 것을 뜻합니다. 대부분의 브라우저에서는 이를 기본적으로 차단하며, 서버측에서 헤더를 통해서 사용가능한 자원을 알려줍니다. preflight request는 실제 요청을 보내도 안전한지 판단하기 위해 사전에 보내는 요청입니다. OPTIONS 메서드로 요청하며 CORS를 허용하는지 확인합니다. CORS가 허용된 요청이라면 웹서버에서 사용 가능한 리소스를 헤더에 담아 응답합니다
CORS가 필요한 이유가 무엇이라고 생각하시나요?
만약 문제가 없는 올바른 A 라는 사이트를 이용하면서 로그인을 한 후에 자동 로그인을 이용하고 있다고 생각해보겠습니다. 자동 로그인을 유지하기 위해서는 쿠키, 세션 or JWT와 같은 정보들을 서버와의 인증을 위한 통신이 필요할 것입니다.(중요한 정보일텐데요.)
그런데 만약 어떤 문제가 있는 해킹하는 사람들이 똑같은 형태의 B 라는 사이트를 만들어 우리에게 접속하도록 보내서 우리가 접속했다고 가정하겠습니다. 그러면 A 사이트를 접속할 때처럼 B 사이트를 접속할 때는 중요한 인증 정보를 보내게 될 것인데요. 즉, 중요한 정보들이 탈취 당하게 되는 것입니다.
이렇게 탈취 당한 정보를 통해서 해커들이 실제 A 사이트에서 나쁜 일을 할 수 있게되는 것입니다.
인증 vs 인가 차이에 대해서 설명해주세요.
어떤 A라는 건물에 출입을 할 때, 출입증이 있다면 들어갈 수 있고 없다면 들어갈 수 없다. 이렇게 식별 가능한 정보로 서비스에 등록된 유저의 신원을 입증하는 과정을 인증이라 합니다.
하지만 출입증으로 회사의 모든 곳을 다 돌아다닐 수 있는 것은 아니다. 만약 A라는 10층짜리 건물에 내가 다니는 회사는 5층이라면 나머지 층에는 출입을 할 수 있다.
이러한 것을 인가라고 한다. 한마디로 권한에 대한 허가를 나타내고, 인증된 사용자에 대한 자원 접근 권한 확인이다.
또 다른 예로는 어떤 게시글을 내가 작성하였을 때, 다른 사람들은 이 글에 대해 수정, 삭제 권한이 없다.
이것이 인가가 적용이 된 예시이다.
따라서 반드시 인증이 인가보다 선행되어야 하는 개념이다- 인증 에러 401 Unauthorized, 인가 에러 403 Forbidden
TCP 와 UDP 차이점이 무엇인가요?
TCP 는 신뢰성/정확성을 우선으로 하는 연결형 통신 프로토콜 입니다. 연결형 통신은 꼼꼼하게 상대방을 확인하면서 데이터를 전송합니다. 데이터를 전송하려면 먼저 연결(connection)이라는 가상의 독점 통신로를 확보해야 합니다.
UDP는 전송 계층에서 효율적으로 통신할 수 있도록 돕는 프로토콜 입니다. UDP는 TCP 와는 다르게 비연결형 통신이기 때문에 데이터를 전송할 때 TCP 처럼 시간이 걸리는 확인 작업을 일일이 하지 않습니다. UDP는 TCP와 달리 효율성을 중요하게 여기는 프로토콜이라 TCP와 같은 신뢰성과 정확성을 요구하게 되면 효율이 떨어집니다. UDP의 장점은 데이터를 효율적으로 빠르게 보내는 것이라서 스트리밍 방식으로 전송하는 동영상 서비스와 같은 곳에 사용됩니다. 그래서 동영상 같은 것 대게 빠른 UDP를 사용합니다.
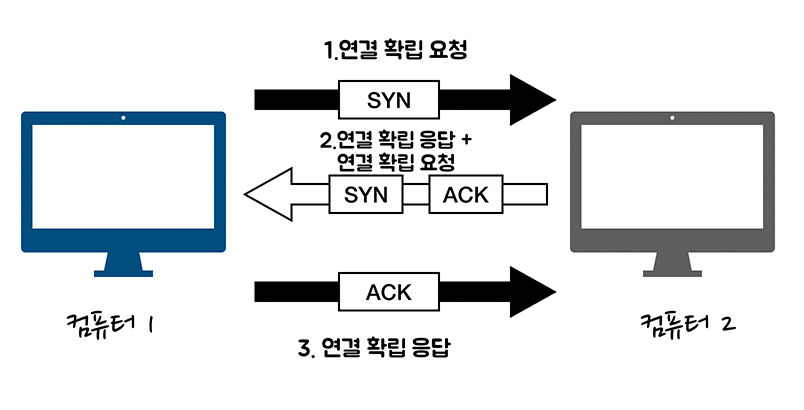
- 통신을 하려면 컴퓨터 2에게 허가륵 받아야 하므로, 컴퓨터 1에서 컴퓨터 2로 연결 확릴 허가를 받기 위한 요청
SYN을 보냅니다. - 컴퓨터 2는 컴퓨터 1이 보낸 요청을 받은 후에 허가한다는 응답을 회신하기 위해 연결 확립 응답
ACK을 보냅니다. 동시에 컴퓨터 2도 컴퓨터 1에게 더이터 전송 허가를 받기 위해 연결 확릴 요청SYN을 보냅니다. - 컴퓨터 2의 요청을 받은 컴퓨터 1은 컴퓨터 2를 허가한다는 응답으로 연결 확인 응답
ACK를 보냅니다.
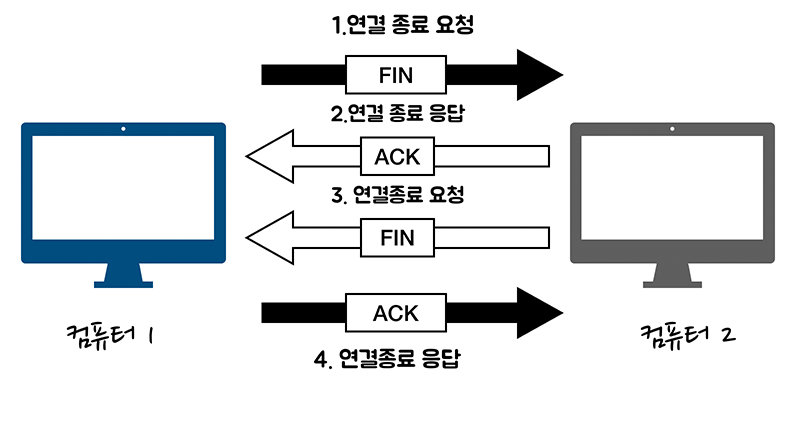
- 컴퓨터 1에서 컴퓨터 2로 연결 종료 요청
FIN을 보냅니다. - 컴퓨터 2에서 컴퓨터 1로 연결 종료 응답
ACK을 반환합니다. - 또한 컴퓨터 2에서도 컴퓨터 1로 연결 종료 요청
FIN을 보냅니다. - 컴퓨터 1에서 컴퓨터 2로 연결 종료 응답
ACK를 반환합니다.
캡슐화와 역캡슐화가 무엇인가요?

- 캡슐화 : 응용 계층부터 물리 계층까지 계층별로 데이터를 전당할 때 헤더를 붙이는 것입니다.
- 역캡슐화 : 물리 계층부터 응용 계층까지 계층별로 데이터를 전달할 때 헤더를 제거하는 것입니다.
STOMP 란 무엇인가요?
STOMP (Simple Text Oriented Messaging Protocol)은 메세징 전송을 효율적으로 하기 위해 탄생한 프로토콜이고, 기본적으로 pub / sub 구조로 되어있어 메세지를 전송하고 메세지를 받아 처리하는 부분이 확실히 정해져 있기 때문에 개발자 입장에서 명확하게 인지하고 개발할 수 있는 이점이 있다.
STOMP 프로토콜은 WebSocket 위에서 동작하는 프로토콜로써 클라이언트와 서버가 전송할 메세지의 유형, 형식, 내용들을 정의하는 매커니즘이다.
위에서 언급한 pub / sub란 메세지를 공급하는 주체와 소비하는 주체를 분리해 제공하는 메세징 방법이다. 기본적인 컨셉을 예로 들자면 우체통(Topic)이 있다면 집배원(Publisher)이 신문을 우체통에 배달하는 행위가 있고, 우체통에 신문이 배달되는 것을 기다렸다가 빼서 보는 구독자(Subscriber)의 행위가 있다. 이때 구독자는 다수가 될 수 있다. pub / sub 컨셉을 채팅방에 빗대면 다음과 같다.
-
채팅방 생성 : pub / sub 구현을 위한 Topic이 생성됨
-
채팅방 입장 : Topic 구독
-
채팅방에서 메세지를 송수신 : 해당 Topic 으로 메세지를 송신(pub), 메세지를 수신(sub)
www.google.com 을 쳤을 때 발생하는 일들에 대해서 설명해주세요.

- 브라우저에 입력한 주소를 운영체제에게 DNS로 요청을 보내서 IP를 알아내달라는 요청을 보낸다.
- 운영체제는 브라우저의 URL을 DNS 서버에게 질의한다. DNS 서버는 root 서버로부터 조회해서 해당 도메인의 IP가 무엇인지를 알아낸다.
- DNS로 부터 받은 IP 주소를 기반으로 IP 주소, Port, 요청 메세지를 기반으로 HTTP 메세지를 만든다.
- 애플리케이션 계층에서 만든 HTTP 메세지를 TCP 계층에서 통신하기 쉽도록 HTTP 메세지를 패킷으로 분해한다.(조각내서 일련번호를 부여한다.)
- 프로토콜이 HTTP가 아닌 HTTPS 라면 TLS, SSL Layer에서 SSL HandShake 과정도 진행된다.
- TCP 계층에서 3-way-Handshake 과정을 거치고 상대방 네트워크와 연결한다.
- 네트워크 계층에서는 상대가 어디에 있는지 찾아서 중계해가면서 패킷을 상대방에서 전송한다. 상대 IP 주소와 라우터 ARP를 사용하여 상대 MAC 주소를 확인한다.
- 받는 쪽 TCP 계층에서 전송오는 패킷을 수신하고 도착한 패킷을 일련번호를 보고 조립한다.
- 받는 쪽 애플리케이션 계층에서 HTTP 메세지를 보고 해당 리소스에 맞는 것을 사용자에게 보여준다.

AWS Route53의 예시
- 사용자가 웹 브라우저를 열어 주소 표시줄에 www.example.com을 입력하고 Enter 키를 누릅니다.
- www.example.com에 대한 요청은 일반적으로 케이블 인터넷 공급업체, DSL 광대역 공급업체 또는 기업 네트워크 같은 인터넷 서비스 제공업체(ISP)가 관리하는 DNS 해석기로 라우팅됩니다.
- ISP의 DNS 해석기는 www.example.com에 대한 요청을 DNS 루트 이름 서버에 전달합니다.
- ISP의 DNS 해석기는 www.example.com에 대한 요청을 이번에는 .com 도메인의 TLD 이름 서버 중 하나에 다시 전달합니다. .com 도메인의 이름 서버는 example.com 도메인과 연관된 4개의 Amazon Route 53 이름 서버의 이름을 사용하여 요청에 응답합니다.
- ISP의 DNS 해석기는 Amazon Route 53 이름 서버 하나를 선택해 www.example.com에 대한 요청을 해당 이름 서버에 전달합니다.
- Amazon Route 53 이름 서버는 example.com 호스팅 영역에서 www.example.com 레코드를 찾아 웹 서버의 IP 주소 192.0.2.44 등 연관된 값을 받고 이 IP 주소를 DNS 해석기로 반환합니다.
- ISP의 DNS 해석기가 마침내 사용자에게 필요한 IP 주소를 확보하게 됩니다. 해석기는 이 값을 웹 브라우저로 반환합니다. 또한, DNS 해석기는 다음에 누군가가 example.com을 탐색할 때 좀 더 빠르게 응답할 수 있도록 사용자가 지정하는 일정 기간 example.com의 IP 주소를 캐싱(저장)합니다. 자세한 내용은 Time to Live(TTL)를 참조하세요.
- 웹 브라우저는 DNS 해석기로부터 얻은 IP 주소로 www.example.com에 대한 요청을 전송합니다. 여기가 콘텐츠가 있는 곳으로, 예를 들어 웹 사이트 엔드포인트로 구성된 Amazon S3 버킷 또는 Amazon EC2 인스턴스에서 실행되는 웹 서버입니다.
- 192.0.2.44에 있는 웹 서버 또는 그 밖의 리소스는 www.example.com의 웹 페이지를 웹 브라우저로 반환하고, 웹 브라우저는 이 페이지를 표시합니다.

-
브라우저에서 Nesite.com을 검색하고, 사용하고 있는 통신사인 KT DNS 서버에게 도메인 주소에 해당하는 IP 주소를 요청함 (브라우저 기본 DNS 설정이 통신사 DNS 서버이기 때문)
-
ISP 서버에선 캐시 데이터가 없다는 걸 확인하고 루트 DNS 서버에게 어디로 가야 하는지 요청함(캐시가 있다면 8.로 건너 뜀.)
-
루트 서버는 TLD DNS 서버 주소만 관리하기 때문에, ***.com 도메인을 보고는 COM 최상위 도메인을 관리하는 TLD DNS 서버 주소를 안내함.
-
ISP 서버는 COM 서버에게 어디로 가야 하는지 다시 요청함.
-
COM 서버는 가비아 DNS 서버에서 해당 도메인이 관리되고 있는 걸 확인하고 안내함.
-
ISP 서버는 가비아 서버에게 또 다시 요청함.
-
가비아 서버는 “Nesite.com = 12.123.123.123”이라는 정보를 확인하고 이 IP를 알려줌. 동시에 ISP 서버는 해당 정보를 캐시로 기록해 둠.
-
ISP 서버는 브라우저에게 힘들게 알아 낸 12.123.123.123 주소를 안내함.
-
브라우저는 12.123.123.123 IP 주소를 갖고 있는 호스팅 서버에게 웹사이트를 출력하라고 요청함.
-
드디어 보임.
OSI 7 Layer 에 대해서 설명해주세요.
표준 규격을 정하는 단체인 ISO라는 국제표준화기구가 있는데, 이 단체에서 OSI 모델이라는 표준 규격을 제정했습니다.
위의 그림처럼 총 7개의 Layer로 구성된 모델입니다. 각 Layer의 특징을 간단하게 정리하면 아래와 같습니다.
| 계층 | 이름 | 설명 |
|---|---|---|
| 7계층 | 응용 계층(Application Layer) | 이메일 & 파일 전송, 웹 사이트 조회 등 애플리케이션에 대한 서비스를 제공 |
| 6계층 | 표현 계층(Presentation Layer) | 문자 코드, 압축, 암호화 등의 데이터를 반환 |
| 5계층 | 세션 계층(Session Layer) | 세션 체결, 통신 방식을 결정 |
| 4계층 | 전송 계층(Transport Layer) | 신뢰할 수 있는 통신을 구현 |
| 3계층 | 네트워크 계층(Network Layer) | 다른 네트워크와 통신하기 위한 경로 설정 및 논리 주소를 결정 |
| 2계층 | 데이터 링크 계층(Data Link Layer) | 네트워크 기기 간의 데이터 전송 및 물리적인 주소를 결정 |
| 1계층 | 물리 계층(Physical Layer) | 시스템 간의 물리적인 연결과 전기 신호를 변환 및 제어 |
TCP/IP는 위의 그림에서 볼 수 있듯이 4개의 계층만 존재하는 모델입니다.

위의 그림에서 볼 수 있듯이 TCP/IP 모델은 4 Layer 인 것을 볼 수 있는데요.
| OSI 7 계층 | TCI/IP 계층 |
|---|---|
| 세션 + 표현 + 응용 | 응용 계층(Application Layer) |
| 전송 계층 | 전송 계층(Transport Layer) |
| 네트워크 계층 | 인터넷 계층(Internet Layer) |
| 물리 + 데이터 계층 | 네트워크 계층(Network Layer) |
L4 로드 밸런싱과 L7 로드 밸런싱에 대해 설명하고, 차이를 말해보세요
L4는 4계층인 TCP UDP에서 IP와 Port를 활용하여 서버 부하 분산을 하는 것을 의미합니다.L7 보다는 비용이 싸다는 특징이 있습니다.(NLB(Network Load Balancer) = L4)L7는 7계층인 애플리케이션 계층에서 사용됩니다. HTTP Header, Cookie 등과 같이 사용자가 요청한 정보들을 바탕으로 트래픽을 분산하기 때문에 섬세한 라우팅이 가능하고 비정상적인 트래픽을 판별할 수 있습니다. L4 로드 밸런싱보다 가격이 비쌉니다.(ALB(Application Load Balancer) = L7)
HTTP 1.1 vs HTTP 2.0 차이점
HTTP/1.1와 일부 HTTP/1.0에서는 TCP 연결 문제를 해결하기 위해서 지속 연결이라는 방법을 고안하였다. 지속 연결의 특징은 어느 한 쪽이 명시적으로 연결을 종료하지 않는 이상 TCP 연결을 계속 유지한다.
지속 연결을 하는 이점은 TCP 커넥션의 연결과 종료를 반복하는 오버헤드를 줄여주기 때문에 서버에 대한 부하가 줄어든다. 또한 오버헤드를 줄인 만큼 HTTP 요청과 응답이 빠르게 완료되기 때문에 웹 페이지를 빨리 표시할 수 있다. (이러한 지속 연결은 HTTP/1.1 에서는 표준 동작이지만 HTTP/1.0에서는 정식 사양은 아니었다.)
지속 연결은 여러 요청을 보낼 수 있도록 파이프라인화를 가능하게 한다. 파이프라인화에 의해서, 이전에는 요청을 받은 후에 응답을 줄 때까지 기다린 뒤에 요청을 보냈다면, 이제는 응답을 기다리지 않고 다음 요청을 보낼 수 있다.
이는 TCP 안에 두 개 이상의 HTTP 요청을 담아 Network Latency을 줄이는 방식이다.
하지만 이는 정확히 구현하기 힘들 뿐 아니라 HOL Blocking이 발생합니다.
HOL은 Head of Line의 줄임말로서 앞선 요청에 의해 뒤에 요청이 지연되는 것을 의미한다.
HTTP Pipelining 을 통해 한 번에 여러 개의 이미지를 요청하는 경우를 생각해보자.
가장 앞에 요청한 이미지가 응답이 지연되면 두, 세번째 이미지도 지연이 발생한다.
TCP 안에 여러 개의 HTTP 요청이 왔으므로 완료된 응답부터 보내면 되지 않을까라고 생각할 수 있지만 서버는 TCP에서 요청을 받은 순서대로 응답을 해야한다.
클라이언트와 서버 간에 수 많은 http 요청이 발생할 것이고 header의 정보는 대부분 동일하다.
하지만 HTTP 1.1에서는 이러한 헤더를 중복해서 계속 보낼 뿐 아니라 cookie 정보 역시 매 요청마다 헤더에 포함되어 전송된다.
즉 불필요한 데이터를 주고 받는데 네트워크 자원이 소비되는 문제가 발생한다.
HTTP 2.0은 HTTP를 아예 새롭게 개선하기 보다는 기존 HTTP 1.1을 개선하는 방향에서, 성능 쪽에 초점을 맞춘 프로토콜로서 2015년 2월 표준으로 승인되었다.
HTTP 1.1의 여러 문제점으로 구글이 개발한 비표준 개방형 프로토콜 SPDY를 기반하였다.
HTTP 1.1의 HTTP Pipelining 의 개선안으로 하나의 Connection으로 동시에 여러 개의 메세지를 주고 받을 수 있습니다. 또한 응답은 요청 순서에 상관없이 Stream으로 받기 때문에 HOL Blocking 도 발생하지 않습니다.
HTTP 1.1의 경우 이전 요청과 중복되는 Header도 똑같이 전송하느라 네트워크 자원을 불필요하게 낭비하였다.
HTTP 2.0의 경우, Header Table과 Huffman Encoding을 사용하는 HPACK 압축방식으로 이를 개선하였다.
클라이언트와 서버는 각각 Header Table을 관리하고 이전 요청과 동일한 필드는 table의 index만 보내고, 변경되는 값은 Huffman Encoding 후 보냄으로서 Header의 크기를 경령화 하였다.
HTTP 1.1과 HTTP 2.0 가 리소스(이미지 등)를 가져올 때의 차이점
HTTP 1.1에서는 파이프라인 방식을 사용했다면 HTTP 2.0에서는 Multiplexed Streams 방식을 사용해서 효율적으로 이미지를 가져올 수 있다.
로드밸런싱 알고리즘 대표적인 것 하나만 특징과 함께 말해주세요.
라운드 로빈 스케줄링(Round Robin Scheduling, RR)은 시분할 시스템을 위해 설계된 선점형 스케줄링의 하나로서, 프로세스들 사이에 우선순위를 두지 않고, 순서대로 시간단위(Time Quantum)로 CPU를 할당하는 방식의 CPU 스케줄링 알고리즘이다.
보통 시간 단위는 10 ms ~ 100 ms 정도이다. 시간 단위동안 수행한 프로세스는 준비 큐의 끝으로 밀려나게 된다. Context Switching의 오버헤드가 큰 반면, 응답시간이 짧아지는 장점이 있어 실시간 시스템에 유리하다.