-
Notifications
You must be signed in to change notification settings - Fork 32
/
5、Linux 完整文件系统实现.md
166 lines (121 loc) · 11.3 KB
/
5、Linux 完整文件系统实现.md
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
## L5:文件系统
如何组织多个文件----文件目录树
* 从多个文件的使用角度出发来思考这个组织方式。面对多个文件,对用户来说,最重要的操作是从中找到某个文件,即文件检索操作。
* 在用户眼里,操作系统磁盘就是操作一个目录树。用户可以访问这棵目录树,也可以修改这棵目录树,可以在目录树上添加新的目录和文件,也可以删除已有的目录和文件等。
实现磁盘的抽象就是实现目录树
* 目录树由**文件**和**目录**(目录实际上也是目录文件,也有自己的 FCB)两部分组成。
* 文件的实现已经在 L4 中给出了详细论述,所以实现目录树的关键就是实现目录。
* 由于文件的基本信息都存放在数据结构 FCB 中,所以最容易想到的目录文件中存放该级所有文件的 FCB,访问该目录(即该目录文件)时,会将其下所有文件的 FCB 数据结构读取出来。因为一旦有了 FCB,我们就可以操作该文件对应的字符流了。
* 以解析/my/data/test 为例,首先要读出根目录的内容,根据前面给出的目录实现方案:目录文件中存放该级文件 FCB。
* 根目录文件中存放的是 var 和 my 两个文件的FCB,读入根目录内容就读入了 var 的 FCB 和 my 的 FCB。
* 接下来要干什么?要找到 my 的 FCB,这样才能读入 my 目录的内容,继续向下找到 data 的 FCB。
* 读入了 var 的 FCB 和 my 的 FCB 以后,用“my”字符串和两个 FCB 中的文件名比对,就能找到 my 的 FCB 了。
* 从这个目录解析过程不难看出,文件 var 的 FCB 中存放的大量信息对于/my/data/test 的目录解析没有任何作用,此次目录解析只需要“var”这个名字就可以。
* 因此在目录项内容中(即目录文件中)只要存放该级所包含文件名字即可,不用存放所包含文件的 FCB
* 相比文件 FCB 数据结构而言,文件名的长度要短很多。
* 目录内容变短后不仅会减少存储目录造成的磁盘空间代价,目录解析过程中从磁盘读入的内容也会小很多,目录解析的时间效率会大幅提升。
目录内容中只存放文件名字符串是不够的
* 因为在匹配到“my”以后,还需要读入“my”的 FCB ,获得 my 目录文件的物理盘块,然后才能继续向下解析 my 下所有的目录项。
* 即通过目录项在 FCB 数组找到对应的 FCB(innode),然后就能得到 innode -> zone[0] (即该目录项对应的目录文件的物理盘块号),然后 bread 该物理盘块,得到了 bh,bh -> b_data 就是该目录项对应的物理盘块内容(里面还是目录项数组,直到找到目标文件,然后把该 innode 赋给 file,再给上层返回该 file 的句柄 fd)
* 目录项内容里不存放文件的 FCB(即目录项不存放接着要读的盘块信息),但可以存放一个“FCB 地址”,需要的时候通过这个地址到磁盘上读入文件的 FCB 数据结构。
* 一种常见的处理方法是将磁盘上**所有文件的 FCB(即 innode,一个 FCB 通常几十字节,里面没有数据,但是包含其索引的盘块号) 数据结构组织成一个数组连续地存放在一个磁盘块**序列上,此时一个文件的“FCB 地址”就是这个文件的 FCB 数据结构在这个 FCB 数组里的索引。
* 这样设计以后,根目录的内容是 [“var”, 13] [“my”, 82],其中“var”是文件名字符串,13 是 var 的 FCB 在 FCB 数组中的索引,这两个信息形成的结构体常被称做为一个**目录项**。因此可以得出这样的结论:“目录的内容就是一个目录项数组”。
* 现在再看一下/my/data/test 的目录解析
* 首先读入“/”的内容,其中存放的信息是 [“var”, 13] [“my”, 82]。根据路径名现在要匹配字符串“my”,字符串匹配以后发现 my 目录文件的 FCB 编号为 82。
* 启动磁盘读在 FCB 数组中读出my 的 FCB,再根据 my 的 FCB 中存放的逻辑盘块和物理盘块的映射关系找到存放 my 目录内容的磁盘块,启动磁盘读将 my 目录的内容读出来,是 [“data”, 103] [“cont”, 225] [“mail”, 77]。
* 接下来的目录解析该匹配路径中的哪个名字了?data,匹配以后会得到 103,用 103 可以读出 data 的 FCB 了,等等,这样一直工作,最终一定能读入文件 test 的FCB。
* “/”的内容是怎么来的?根目录的也是一个目录文件,其内容可以根据“/”的 FCB 中存放的物理盘块号信息从磁盘上读入。
* 规定“/”的 FCB 一定要放在 FCB 数组中的第一项,这样“/”的 FCB 就能找到了。

由于需要对目录树进行动态修改,所以必然要涉及到磁盘空闲数据块以及磁盘空闲 FCB 的管理
* 通常使用位图来描述磁盘上的物理盘块和 FCB 数组使用情况,其中 1 表示被占用,0 表示空闲。
* 举例来说,如果要新建一个文件,首先要用 FCB 位图找到一个空闲的 FCB,将这个 FCB 分配给新建文件,当然FCB 位图要做相应的修改。
* 有了 FCB 以后,需要修改该文件的所在的目录,要在目录文件内容中增加目录项。新建文件需要存放内容时,需要用空闲数据磁盘块位图找到空闲物理盘块分配给新建文件,当然需要修改相应的物理盘块位图和文件 FCB。
* 之所以用位图来描述这物理盘块和 FCB 数组这两个数据结构,是因为存储FCB 是一个数组,物理磁盘块也形成一个数组
* 用位图来表达数据项的空闲情况是很自然也很高效的一种手段,这和内存页位图是一样的。

* 这个数据结构再配合**目录解析代码、文件读写代码、数据块分配和释放代码、FCB(innode)的分配和回收代码**等,操作系统给上层用户展现出一棵目录树
## 目录解析实现
sys_open
* open 会触发目录解析。所以应该从 sys_open 开始
```c
int sys_open(const char* filename, int flag)
{
// 如果路径名从/开始,就从根目录的 inode 开始,否则要从当前目录的 inode 开始
if((c=get_fs_byte(filename))==‘/’)
{
// current 是当前进程的 PCB 指针,current->root 中的 root 是根目录的 inode
inode = current->root;
filename++;
}
else if(c)
inode=current->pwd;
while(1)
{
if(!c)
return inode;
// 读出目录文件内容,然后用文件路径上的下一段文件名和和目录中的目录项逐个比对
// 若匹配的目录项存下一层还不是最终的文件,那么返回 inode 编号,不断地递归向下继续目录解析,直到路径名被全部处理完成
find_entry(&inode,filename,namelen,&de);
// de 现在是匹配的目录项中存放的 innode 索引
int inr = de->inode;
// 根据 inode 编号和 inode 数组的初始位置,拿到下一层的 innode 接着解析
inode = iget(inr);
}
}
void find_entry(struct m_inode **dir, char *name, struct dir_entry ** res_dir)
{
// 该目录文件有多少目录项
int entries = (*dir)->i_size/(sizeof(struct dir_entry));
// 得到该目录文件的物理盘块号
int block=(*dir)->i_zone[0];
// 读入目录文件
*bh=bread((*dir)->i_dev, block);
// 拿到目录文件物理盘块的内容
struct dir_entry *de = bh->b_data;
// 挨个文件名和目录项比对
while(i<entries)
{
if(match(namelen,name,de))
*res_dir=de;
de++;
i++;
}
}
```
* current->root 是从 1 号进程那里继承来的
```c
void init(void){ mount_root(); ··· }
void mount_root(void)
{
// 将根目录的 inode读入到内存中,并且关联到 1 号进程的 PCB 中。
mi=iget(ROOT_INO)); //ROOT_INO 应该是多少呢?1
current->root = mi;
}
struct m_inode * iget(int nr)
{
// 读入超级快,超级块里包含了 FCB 位图、和数据块位图所占的块数
// 由于不同的硬盘大小、不同的操作系统,这两个参数肯定会发生不同,
// 所以在磁盘格式化时需要将这两个重要的参数写到磁盘超级块 sb 中
struct super_block *sb = get_super();
// 找到 inode 数组在磁盘上的起始块位置
// inode 数组的起始位置在引导块、超级块以及两个位图数组之后
block = 2 + sb->s_imap_blocks + sb->s_zmap_blocks + (nr-1)/INODES_PER_BLOCK;
// 读入 innode 数组
bh = bread(dev,block);
// 将指定的 innode 从 innode 数组取出
inode = bh->data[(nr-1)%INODES_PER_BLOCK];
return &inode;
}
```
到此我们完成了对磁盘使用的全部五层抽象,将这五层抽象倒过来就是从用户出发的、操作系统封装起来的磁盘使用全过程:
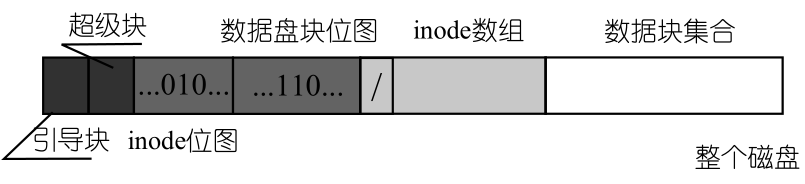
* (1)安装操作系统的时候,会将整个磁盘格式化成为上图的样子。
* (2)系统启动的时候,会将磁盘的根目录文件找到,将根目录的文件的 inode 读入到内存中,作为 1 号进程的一个资源。
* (3)用户创建的任何一个进程都会继承这个根目录的 FCB。
* (4)用户在程序(一旦执行就变成为进程了)中 open 一个文件时,如 open(/my/data/test) 时,会启动目录解析,最终得到目标文件(即 test)的 inode 并将其读入到内存中,返回一个文件句柄 fd。
* (5)用户通过这个文件句柄 fd 操作文件时,如 read(fd,buf,count) 时,操作系统会根据 fd 找到当前的文件字符流位置 pos,根据 pos 和文件 inode 中存储的索引信息找到 pos 对应的物理盘块的盘块号 block。
* (6)调用 bread(block) 在磁盘高速缓存中去读,如果已经在缓存中,直接将内容拷贝返回到用户态缓存 buf 中;如果没在高速缓存中,获得一个空闲的高速缓存 bh,并将 block 等信息填写到 bh 中。
* (7)将高速缓存 bh 做成磁盘读写请求 req,根据磁盘块和扇区之间的关系算出 block 对应的扇区号 sector,利用 sector 信息将 req 加入的电梯队列中,发起读的进程进行睡眠等待。
* (8)当磁盘控制器处理完上一个磁盘读写请求以后产生磁盘中断,在磁盘中断处理函数中,操作系统会从电梯队列中取出这个请求 req,根据其中的读写扇区号 sector 换算出要读的柱面号 C、磁头号 H 和扇区号 S,利用 out 指令将C、H、S 发出到磁盘控制器上,现在磁盘控制器开始真正读磁盘了。
* (9)磁盘控制器完成该磁盘请求后会再次产生磁盘中断,中断处理程序会唤醒那个睡眠的进程,当被唤醒的进程再次执行时,磁盘高速缓存 bh 已经存放有/my/data/test 的那个字符流位置处的内容了,将这个内容拷贝到用户缓存 buf中,整个磁盘使用的工作到此全部完成。