linux_038
[ToC]
(持续更新和修正)

struct page 是内核管理最基本的单位。内核的各种内存分配api最底层都是基于它的。
与page有关的函数[7]:
virt_to_page()returns the page associated with a virtual addresspfn_to_page()returns the page associated with a page frame numberpage_to_pfn()return the page frame number associated with astruct pagepage_address()returns the virtual address of astruc page; this functions can be called only for pages from lowmemkmap()creates a mapping in kernel for an arbitrary physical page (can be from highmem) and returns a virtual address that can be used to directly reference the page
每个进程对应一个struct task_struct,而每个task_struct都指向一个struct mm_struct,如下图[3],mm_struct 对象管理着一个进程的内存布局。
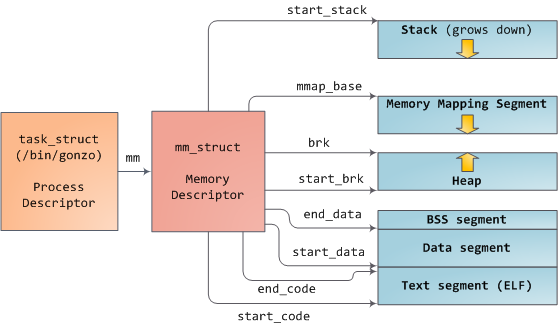
它通过一个struct vm_area_struct *(vma)指针,指向一个vm_area_struct链表(mmap),也通过一个红黑树(mm_rb)来加速这些vma的查找,如下图[4]。

vma(struct vm_area_struct)同样有指向struct mm_struct的指针(vm_mm),同时也被组织到address_space结构中。
关于vma 和逆向映射见[4 ch4.4.2 ch4.8.1] 和 [9] (https://www.cnblogs.com/alantu2018/p/8447622.html)
struct address_space可以看作是将vma和inode联系在一起。如下图[4],它除了用红黑树(i_mmap),还用链表组织着vma。而且,它还有一个称谓host的struct inode *指针,与后端文件/设备关联起来。
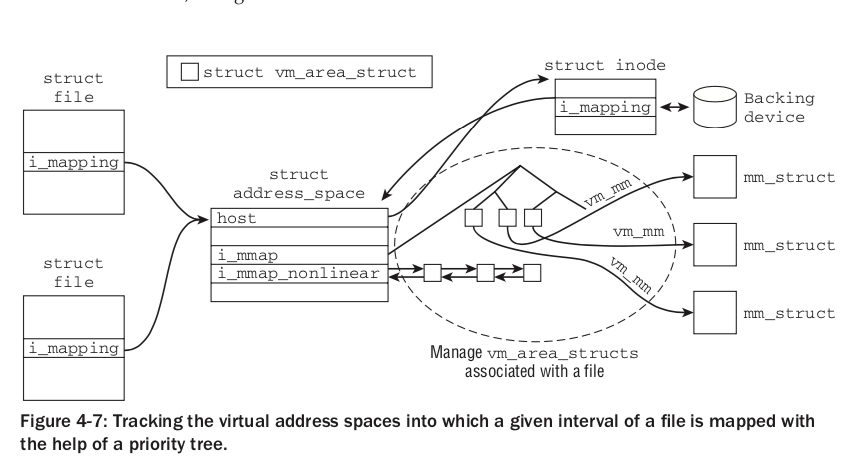
除了vma对象,address_space同样管理着对应inode的page cache,它被红黑树管理,称为 page_tree,最近被改为xarray实现的i_pages[5-6]。如下图[4]。

每个内存numa node被分成多个zone,struct zone被定义在include/linux/mmzone.h文件。32位系统多为DMA、normal和highmem三种,64位一般只有DMA和normal两种。zone中除了管理空闲页和内存分配per-cpu缓存,还管理着active_list和inactive_list。
32位系统
物理内存被分成多个zone,zone_highmem, zone_normal和zone_dma,其中zone_normal为896MB,对应内核的直接映射区逻辑地址(线性映射的内核虚拟地址)。
32位系统的地址空间是4GB,在一般情况下,03GB分给用户态,34GB分给内核态,内核又把它的1GB地址空间分成直接映射区、vmalloc区、持久映射区、临时映射区等部分。
内核地址空间的直接映射区的内核虚拟地址也被称为逻辑地址或线性地址,与内存zone_normal区的物理地址直接线性映射,只差了一个固定的偏移(PAGE_OFFSET),这个偏移一般为3GB。

64位系统
对于64位系统的内存没有zone_highmem的概念,因为内核地址空间够大了,物理内存足够直接映射到内核地址空间。
一些类型:
// include/linux/types.h
....
/*
* The type of an index into the pagecache.
*/
#define pgoff_t unsigned long
#ifdef CONFIG_ARCH_DMA_ADDR_T_64BIT
typedef u64 dma_addr_t;
#else
typedef u32 dma_addr_t;
#endif
typedef unsigned int __bitwise gfp_t;
typedef unsigned int __bitwise slab_flags_t;
typedef unsigned int __bitwise fmode_t;
#ifdef CONFIG_PHYS_ADDR_T_64BIT
typedef u64 phys_addr_t;
#else
typedef u32 phys_addr_t;
#endif
typedef phys_addr_t resource_size_t;
....模拟PMEM:
sudo cat /proc/iomem 可以看到一些内存地址的分布。例如一个128G的内存,并修改grub在内核参数中加入了GRUB_CMDLINE_LINUX="memmap=48G!80G",它的内存分布如下:
# sudo cat /proc/iomem
...
100000000-13ffffffff : System RAM #16G
1400000000-1fffffffff : Persistent Memory (legacy) #47G
1400000000-1fffffffff : namespace0.0
2000000000-207fffffff : System RAM #1G
...dax pmem驱动:
通过 memory hotplug 的add_memory API 将一个dax device的内存加入到一个numa 内存node中。这个函数原型如下:
int add_memory(int nid, u64 start, u64 size);在kmem驱动中, start为resource_size_t类型,与一个物理内存地址的类型相同,nid为numa node 的id。
mmap 系统调用返回一个unsigned long类型地址,调用栈:
ksys_mmap_pgoff
--> vm_mmap_pgoff
--> do_mmap_pgoff
--> do_mmap
--> mmap_region
--> call_mmap
--> file->f_op->mmap
对vma的操作是从mmap_region这个函数开始。对于匿名映射,在mmap_region会将后端用shmem_zero_setup设为/dev/zero或者用vma_set_anonymous设为NULL。对于非匿名映射,最终调用文件系统的相应mmap方法,以ext2为例,若不是dax会调用generic_file_mmap函数,主要作用是为目标vma指定vma操作方法(vma->vm_ops = &generic_file_vm_ops;);若是ext2打开了dax支持,则直接指定dax vma方法:vma->vm_ops = &ext2_dax_vm_ops;。
主要的内存分配/实际映射步骤都在首次访问导致的 page fault阶段 执行:
(mm/memory.c) (mm/hugetlb.c) (fs/userfaultfd.c)
handle_mm_fault -+-> hugetlb_fault --> hugetlb_no_page -----> handle_userfault <---------+
| (mm/memory.c) (mm/huge_memory.c) |
+-> create_huge_pmd --> do_huge_pmd_anonymous_page----------------------+
| (mm/memory.c) |
+-> __handle_mm_fault --> handle_pte_fault -+-> do_anonymous_page ------+
| +--> do_wp_page |
+--------------- do_fault <------------------+--+--> do_swap_page (MAJOR)|
| (mm/shmem.c) +--> do_numa_page |
+---> do_read_fault +--> shmem_fault --> shmem_getpage_gfp -----+
| |
+---> do_cow_fault +-----+--> ext4_dax_fault (fs/ext4/file.c)
| | +--> ... (FS&driver page faulthandlers)
+---> do_shared_fault -+--> __do_fault(--> vma->vm_ops->fault)
| +--> do_page_mkwrite(--> vma->vm_ops->page_mkwrite)
+---> VM_FAULT_SIGBUS |
+--> ext4_dax_pfn_mkwrite (fs/ext4/file.c)
+--> ... (FS&driver handlers)
- 没有PTE页表项的两种情况:
-
文件系统作后端的页会调用相应文件系统的fault方法。比如,一般的filemap_fault,它会调用
page_cache_alloc分配页进行文件预读,最终的页分配还是会调到alloc_page族函数__alloc_pages_node。再比如,在dax对应的fault方法ext2_dax_fault中,主要的dax_iomap_fault函数会被传入ext2_iomap_ops,ext2_iomap_ops中包括.iomap_begin和.iomap_end等方法。在dax_iomap_fault调用的ext2_iomap_begin中,会先用ext2_get_blocks查找块,然后赋值iomap对象的各种信息:
struct iomap {
u64 addr; /* disk offset of mapping, bytes */
loff_t offset; /* file offset of mapping, bytes */
u64 length; /* length of mapping, bytes */
u16 type; /* type of mapping */
u16 flags; /* flags for mapping */
struct block_device *bdev; /* block device for I/O */
struct dax_device *dax_dev; /* dax_dev for dax operations */
void *inline_data;
void *private; /* filesystem private */
const struct iomap_page_ops *page_ops;
};iomap填完之后,最终会调用__vm_insert_mixed,用pfn作为页的物理后端:
static vm_fault_t __vm_insert_mixed(struct vm_area_struct *vma,
unsigned long addr, pfn_t pfn, bool mkwrite)
{
...
page = pfn_to_page(pfn_t_to_pfn(pfn));
err = insert_page(vma, addr, page, pgprot);
...
}- 而匿名映射会最终调用
do_anonymous_page,然后调用alloc_zeroed_user_highpage_movable,最终调用alloc_page_vma。
- 对于有PTE页表项还发生缺页的情况:
可能导致 do_wp_page/do_swap_page/do_numa_page,分别对应写保护的cow、swap页调入和numa页平衡。
- 一些总结
还有两种 copy-on-write 的情况,一种是已有页表项情况下的do_wp_page,还有一种是有页表项情况下do_fault的do_cow_fault分支。
| PTE页表项 | 映射类型 | 函数 |
|---|---|---|
| 无 | 匿名映射 | do_anonymous_page |
| 无 | 文件映射 | do_fault --> (do_read_fault/do_cow_fault/do_shared_fault) |
| 有 | swap/numa/cow | do_wp_page/do_swap_page/do_numa_page |
如下图[4],所有的分配器都会最终由 alloc_pages_node分配内存页。

那么究竟啥时候用啥分配API呢[4] [8]:
- kmalloc / kzalloc / kfree 对应slab分配器,一般用于分配小于一页的内存。
- vmalloc / vzalloc / vfree 用于分配最小页粒度的大范围内存,它可以分配逻辑连续但是物理不连续的虚拟内存。
- alloc_pages 也可以在直接分配较多内存使用,它直接申请page。
- kvmalloc 则会先尝试用 kmalloc ,如果分配失败改用vmalloc;kvfree 可以free kmalloc / vmalloc / kvmalloc 分配的内存。
- kmem_cache_create / kmem_cache_free 可以创建slab缓存。
以上kmalloc / vmalloc两种内核分配器API底层都是基于伙伴系统,也最终会调用alloc_pages_node。伙伴系统中,对于一页(order为0)的分配,per-CPU内存页分配缓存可能被采用[4]:
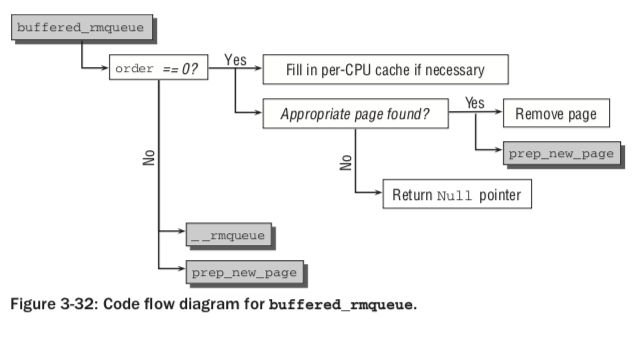
分配参数: GFP(get free pages)参数经常在分配内存时被指定,如GFP_KERNEL, GFP_NOWAIT, GFP_ATOMIC等。
注: GFP_COLD 已经被移除了[1] 。而hot-n-cold allocator的pcp也被合成了一个list[2]。
丢弃: 对于clean的页,可以直接丢弃。
非匿名页的 同步(synchornization): 一般指的是后端存储设备/文件(address_space/inode)与相应page cache内存的数据同步。内核使用一个或多个pdflush线程进行同步操作。同步相关的系统调用包括sync/fsync/fdatasync/msync。
交换页的 回写(write-back): 交换页一般是匿名页,匿名页会被添加到叫做swapper_space的address space中,它也被称为交换缓存(swap cache)。交换页的回写利用了swap cache这个address space的writepage方法(一般是swap_writepage函数)。现在的内核中,这个address space被定义在mm/state.c中被定义为叫做swapper_spaces的address space数组。内核提供一组函数向这个address space添加页或者查找页。[4-p844]
向page cache添加页需要调用mm/filemap.c文件中的add_to_page_cache / add_to_page_cache_lru函数;向 swap cache 添加页与向page cache添加是类似的。区别是,swap cache一般是直接添加已存在的匿名页而非有backend的页。
page cache的同步和swap cache的换出都是由address space对应的a_ops->writepage方法完成的。比如swap_cache 对应 mm/page_io.c 中的swap_writepage函数,page cache对应inode所属文件系统的writepage方法。swap cache换出比page cache同步多了一步更新页表的操作,来把已经换出的页从内存移出以腾出空间。
page cache的同步:1) 周期性同步 (pdflush内核线程); 2) 脏页比例过大 (pdflush内核线程); 3)内核或应用代码主动触发(如各种sync调用)。[4-p793]
swap cache的回写(换出):1) 内核中有kswapd这个内核后台线程,当内存到一定阈值会发起页面换出;或者2) 内核内存不足时调用 try_to_free_pages触发。[4-p846]
上述同步、换出和丢弃组成了页面回收的机制,选择很少使用的页则是页面回收的策略。
page 的上一级为zone,一个numa node的内存一般被分为多个zone。如32位系统多为DMA、normal和highmem三种,64位一般只有DMA和normal两种。
zone中除了管理空闲页和内存分配per-cpu缓存,还管理着active_list和inactive_list。zone中的所有page被放到两种list中管理,kswapd通过周期地检查access bit来让pages在两个list间移动(平衡)。随着时间推移,最不常用的页被期待出现在inactive list的末尾等待被换出。当一个page在inactive list时,如果它被访问(referenced),会产生一个soft page fault,将page挪到active list。
最终,shink_page_list负责换出、同步或者丢弃被选中的页。
这两部分LRU list 提供了一种类似二次机会的机制。
换出页的页表项不同于一般页,其存储有1个标志位(标识已经换出)、所在的交换区编号、对应槽位的偏移量(用于在交换区中查找槽位)[4]:
这种“换出页表项”是与体系结构无关的,所以需要通过pte_to_swp_entry处理,将与体系结构相关的pte转为swap entry。
(详见书[5]的第2.4.1节、第4.11.3节)
fork时,子进程复制父进程的页表,同时父子进程同时将页表标记为只读,在尝试写入时产生缺页异常触发缺页异常,进而do_wp_page被调用,进而cow_user_page函数负责实际的拷贝。
tmpfs 基于shmem机制,其中文件不存在持久化后端存储设备,依赖page cache。虽然其中文件的address space对象也有writepage方法(mm/shmem.c 文件中的 shmem_writepage函数),但是除非是分配内存时遇到压力了换到swap cache地址空间中,其他情况并不会起作用:
// mm/shmem.c
/*
* Move the page from the page cache to the swap cache.
* 这个函数负责将shmem的page cache页移到swap cache地址空间中
*/
static int shmem_writepage(struct page *page, struct writeback_control *wbc)
{
...
// 注意这里,for_reclaim 只在内存分配遇到空间不足引起
// 主动回收时才会继续swap,否则直接跳到redirty结束函数
if (!wbc->for_reclaim) {
WARN_ON_ONCE(1);
goto redirty;
}
...
// 若是主动回收,则先add_to_swap_cache将新生成的swap entry添加到swap cache,然后从page cache删除,然后将其刷到swap磁盘分区
if (add_to_swap_cache(page, swap, GFP_ATOMIC) == 0) {
spin_lock_irq(&info->lock);
shmem_recalc_inode(inode);
info->swapped++;
spin_unlock_irq(&info->lock);
swap_shmem_alloc(swap);
shmem_delete_from_page_cache(page, swp_to_radix_entry(swap));
mutex_unlock(&shmem_swaplist_mutex);
BUG_ON(page_mapped(page));
swap_writepage(page, wbc);
return 0;
}
...
}[1] https://lore.kernel.org/patchwork/patch/840262/
[2] https://lwn.net/Articles/14768/
[3] How The Kernel Manages Your Memory, https://manybutfinite.com/post/how-the-kernel-manages-your-memory/
[4] 深入理解Linux内核架构
[5] https://patchwork.kernel.org/patch/10279007/
[6] http://lca-kernel.ozlabs.org/2018-Wilcox-Replacing-the-Radix-Tree.pdf
[7] https://linux-kernel-labs.github.io/master/labs/memory_mapping.html
[8] https://www.kernel.org/doc/html/v5.0/core-api/memory-allocation.html

Wiki: wiki.jcix.top ~聚沙成塔~ Blog: blog.jcix.top