Goal Direction
Euclidean distance is not a very effective heuristic for guiding a transit search toward its goal. With a table of lower bounds on path weight between all pairs of transit stops in a graph, as well as a list of all stops within walking distance of the destination, one can much more accurately estimate remaining weights.
This comes at heavy space cost but can speed up searches in large metropolitan areas. Precomputation times are roughly 15 minutes for Portland, 6 hours for New York. Space requirements are in the gigabytes, but could be eventually cut down by using smaller data types.
Initial checkin in r1330 & r1331
New classes put to use in r1342. Still needs some tuning.
See comments in #362 for a potential issue here.
This is basically working and has been shown to improve search times in large urban areas, so I am marking it closed. Due to the prohibitively large size of the tables (especially if we want to start doing regional or national-scale routing) it would be interesting to see how well ALT works in time-dependent networks. Opening another ticket for that.
The table-based heuristic (#405) does seem to give searches a strong sense of goal-direction even in large cities. However, the tables have N-sqaured entries, and are going to become rapidly cumbersome in anything much bigger than a single major city (region, country, continent).
There is the possibility of using the ALT method (A-Star, Landmarks and the Triangle inequality) to make the number of table entries linear instead of quadratic in N.
Delling and Wagner report that this is a good option for speeding up searches in timetable networks:
- Combining Hierarchical and Goal-Directed Speed-Up Techniques for Dijkstra’s Algorithm. Bauer, Delling, Sanders, Schieferdecker, Schultes, and Wagner (2008)
- Landmark-Based Routing in Dynamic Graphs. Daniel Delling and Dorothea Wagner (2007) Change History
I have been evaluating best-case speedup from goal direction, in order to better judge whether it's a good idea to invest more time this stuff. A few observations:
It takes about 4 seconds to optimisticTraverse every edge in the Portland graph (non-time-dependently i.e. skipping patternboards) and save the cost of every traversal into an edgelist representation of the graph in arrays. The resulting structure is pretty compact.
Once you have the edgelist, you can find optimistic shortest path weights from a single source to the rest of the graph in about 200ms (exploring the entire graph). In New York this takes more like 800ms. In a city the size of Portland or smaller, this presents the interesting option of just doing a non-time dependent search outward from the destination, which provides a tight lower bound for the forward search from the origin. After ~200ms invested in making that heuristic table, any number searches for multiple itineraries to the same destination are performed quickly: many itineraries take about 20 msec in Portland, 20-50 msec in New York. I am seeing treacherously slow outliers when no good path is found (when all good paths use routes that are already banned), but a bit of pruning could probably eliminate those. In any case, the search space sizes achieved with this method are probably about as good as we can get with A*, since this table provides a pretty tight lower bound for every single vertex; any other method (ALT etc) is just trying to reproduce this heuristic as accurately as possible.
comment: by novalis
I haven't really looked at timings on anything lately. Can you give a rundown on the average timings of various methods? Also, what method are you using to compute timings? Is it something I can run and play with?
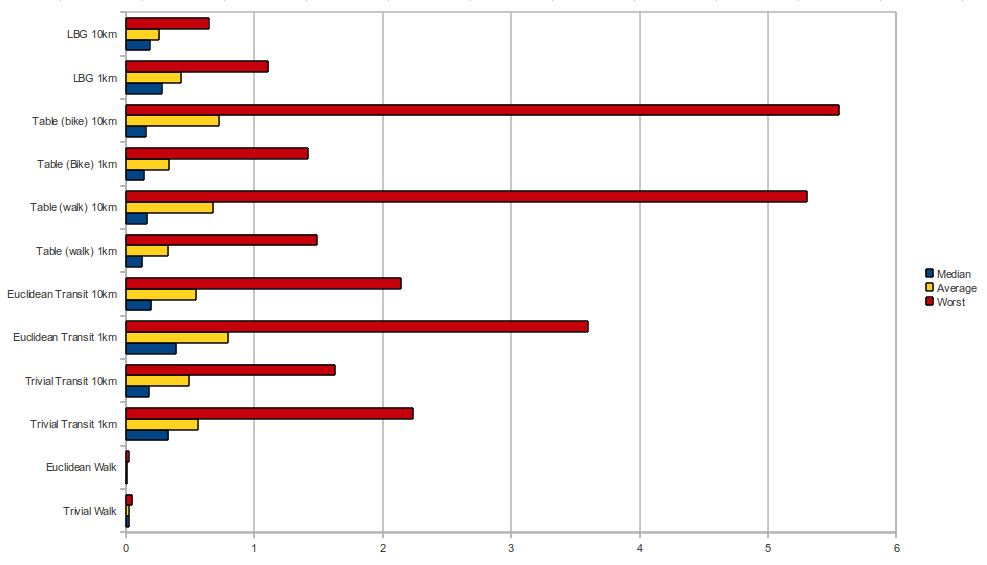
Results of rerunning David Turner's benchmark script on a more recent revision of OTP that uses trip banning instead of route banning. I have modified the benchmark to output mean, median, and worst response times for batches of 3-trip multi-itinerary searches.
Benchmarks using the Tri-met interns' sample trips, varying the remaining weight heuristic and the max walk parameter. Results:
My next batch of benchmarks will be on New York, since these speedup methods should have very different effects as the size of the graph increases. Notably, the up-front time investment per search for the LBG heuristic would be much higher (making it less competitive) and the transit-specific weight table is expected to behave differently.
I am also going to splice back in the original CH class with an absolute minimum of modifications in hopes of removing any inefficiencies I may have introduced, and evaluating whether CH is still advantageous for transit trips.
The LBG heuristic stands out, especially in terms of worst response time, which can be kept well under one second (for three itineraries) as long as the max walk parameter is not set too low. The max walk parameter does not directly affect the heuristic itself, which calculates a single-source shortest path tree backward from the target in a separate, compacted graph whose shortest path metric provides a lower bound on path weights in the time-dependent graph. Decreasing the max walk parameter simply forces some searches to automatically restart with a higher max walk parameter (when no path is found) which increases some response times and pulls up the average.
Almost the entirety of the median response time for LBG-assisted searches is devoted to the fixed cost of performing a SSSP search backward from the target; all three forward searches are often almost instantaneous due to the high quality of the heuristic value, and the fact that it is predefined at every vertex. For a city the size of Portland or smaller, it is feasible to just do a SSSP at the destination for every request. On the negative side, the time invested in this preliminary lower-bound search will increase as the graph size increases. On the positive side, if this heuristic can be approximated with a method which does not involve traversing the entire graph, most searches would become extremely fast, possibly independent of the size of the graph (this is the intent behind what I've been calling the "embedding approach").
It is notable that bulding the weight table for faster biking speeds does not affect performance much, while making it more generally admissible.
The weight table heuristic with a 10km max walk is seen to perform very badly for certain cases, which pulls its average response time up. There are several factors at work here, one of which is the enormous number of stops that are considered "near the target" when "near" means a 10km radius around the center city. The heuristic is simply not efficient in these cases, and was originally designed for a constrained walk distance. Constraining walk distances also allows faster table construction (which is already done in practice).
The WeightTable fares better with a 1km max walk distance, but in our Portland test cases is barely better than the trivial heuristic (h=0 everywhere). It is expected to perform much better on long-distance searches a large city, and if it does not something must be broken.
The WeightTable currently falls back on the Euclidean heuristic for non-transit vertices, but it was originally intended to provide a heuristic value for every vertex (including on-street vertices) by storing a list of nearby stops less than some distance D from each vertex, and their distances from that vertex. This allows perfectly reconstructing the LowerBoundGraph heuristic, without the fixed cost of performing the SSSP, for the subset of trips with walking distance less than than D. This was not pursued because it compromises generality (and increases memory requirements quite a bit, though roughly linearly in |V|).
Constrained-walk WeightTables should perhaps be reconsidered as a way to handle the majority of searches (e.g. maxWalk < 2km), using the plain LBG approach for passengers who accept higher walking distances.
If stops across the street from one another, or at the same street corner were grouped together as single table entries, the size of the WeightTable could be reduced by up to a factor of 4.
Walk-only and bike-only trip planning is seen to be so much faster than multimodal planning that we may just want to stick with a (possibly bidirectional) A* search with the euclidean heuristic for simplicity.
In any case, the choice of heuristic (and even algorithm) will have to be made dynamically depending on max walk distance, modes, and overall distance from origin to destination.
--Andrew Byrd