@TOC
==此博客仅为笔记,及部分知识点的复习==
关于内存池:参考:上上篇博客-待写关于tcmalloc:参考上一篇博客-待写
项目目的:学习tcmalloc的框架(非细节),关于细节在上一篇博客项目说明:在很多地方进行了简化,如上面所说“非细节”,例如:
- 简化sizeclass的设计及映射
- ThreadCache线程本地存储仅用静态(tcmalloc中采用动态tls+静态tls+无tls实现线程本地存储)
- ThreadCache未使用链表链接
- ThreadCache从其他线程'偷'空间未实现
- CentralCache设计简化
- PageCache设计简化
- 回收内存简化
- etc...
Github地址:mini_hcmp (mini HighConcurrencyMemoryPool)
主体由五部分构成:
- ThreadCache
- CentralCache
- PageCache
- ObjectPool
- PageMap
逻辑分为:
- Allocate申请
- Deallocate释放

设定对齐数,ThreadCache和PageCache下标映射等规则
tcmalloc中采用的是:
- size<16,8字节对齐
- size在[16,128)之间,按16字节对齐
- size在[128,256*1024),按(2^(n+1)^-2^n^)/8对齐
这里对size的划分进行简化,划分为6个区间(管理映射规则(控制整体在10%左右的内碎片浪费))
- size在(0, 128], 按8字节对齐
- ...
- ...
- size在(64*1024,256*1024),按8*1024字节对齐
- 对于大于128page的size,按1<<PAGE_SHIFT对齐(一页)
对于RoundUP向上取整,借鉴tcmalloc采用位运算:size为传入的大小,alignSize为对齐数
- 对于区间个条件,传入对应的alignSize,
return ((size + alignSize - 1) & ~(alignSize - 1));- 以129byte为例:按照区间划分,size=129,alignSize为16
(129+16-1) & ~(16-1)1001000011110000&10010000144- 129byte的最小对齐数为144
对于GetIndex取得FreeList数组下标,仍然采用位运:size为传入的大小减上一个区间的最大值,alignSize = 2^alignShift^ (左移乘,右移除)
- 对于第一个区间,传入对应的alignShift,
return ((size + (1i64 << alignShift) - 1) >> alignShift) - 1;(注:64位下移位操作i64显式表示)- 以129byte为例:按照区间划分,size为129-128=1,alignShift为4
((1+(1<<4)-1)>>4) -1(注:这里减一是下标从0开始)((1+16-1)>>4)-11/16-10- 而经计算前128个字节已经占了FreeList数组的前16个位置,所以应定义一个 区间个数-1 大小的IndexOffset数组 例如:
size_t IndexOffset[5] = { 16, 56, 56,56 };GetIndex计算出下标加上IndexOffset[0]才能得出正确下标,以此类推- 所以129byte对应的正确FreeList数组下标为16
按照对其规则,FreeList数组一共有208个元素
- 如图所示:

链表节点该实现的:ThreadCache拥有一个此类型的数组(自由链表实现与定长内存池一样 桶同时参考开散列)
- 头插:取头上指针个大小进行操作(参考下面定长内存池说明)
- 头删
- 判空
- PushRange接口:ThreadCache从CentralCache获得的切分好的FreeList并拿走了需要的部分,将剩下的链入后面
- PopRange接口:ThreadCache的链表在满足一定的条件时归还给CentralCache
- 配合慢启动(MaxSize()) _maxsize初识为1
- Size(), 归还给CentralCache时的条件需要用到:链表有几个节点
SpanList结构:双向带头循环链表,CentralCache和PageCache都会有一个此类型的数组(虽然下标映射方式不同)
- 节点定义如下:
struct Span { //存储span对象的特征 PAGE_ID _pageId = 0; // 大块内存起始页的页号 size_t _n = 0; // 页数 Span* _next; Span* _prev; size_t _useCount = 0;//分配给ThreadCache void* _freelist = nullptr;//切好的FreeList链表 bool _inUse=false;//用于Page Cache的合并,false表示空闲,可以合并 };这里的PAGE_ID,32位下是size_t, 64位下是unsigned long long(32位机器,4 GB(2^32^) 的进程地址空间(2GB用户,2GB内核),64位同理) 页大小这里定为8k,也就是32位机器进程地址空间满了能有2^19^页,64位机器有2^51^页
- _pageId:页号,建立和内存地址的映射关系(内存地址>>PAGE_SHIFT=_pageId, _pageId<<PAGE_SHIFT=内存地址)
- _useCount:用于判断ThreadCache是否全部归还,0表示全部归还
- _inUse:用于Page Cache的合并,false表示空闲,可以合并
需要实现的:
- PopFront:头删,复用Erase
- PushFront :头插,复用Insert
- Begin:返回_head->_next;
- End:返回_head
- pos位置插入
- 删除pos位置
- 判空
- 公有一个互斥锁(桶锁)
tcmalloc中为了方便统计,将ThreadCache由双链表链接起来了,这里未实现
设计框架:
- 私有_freelist[]是哈希桶结构,每个桶是一个FreeList自由链表。每个线程都会有一个ThreadCache对象,每个线程通过pTLSThreadCache获取对象和释放对象时是无锁的
声明 *pTLSThreadCache 为 TLS
static __declspec(thread) class ThreadCache { public: void* Allocate(size_t size); void ListTooLong(FreeList& list, size_t size); void Deallocate(void* ptr, size_t size); void* FetchFromCentralCache(size_t idx, size_t size); void* StealFromPeer(); private: FreeList _freelist_array[MAXFREELIST]; }*pTLSThreadCache;//写法1:声明 *pTLSThreadCache为tls默认为nullptr三个函数接口:
- Allocate:分配空间(从_freelist对应下标处头删,取得空间) (无锁)
- Deallocate:归还空间(将空间头插入_freelist对应下标处) (无锁)
- FetchFromCentralCache:_freelist为空从CentralCache获取空间 (有桶锁)
- ListTooLong:释放逻辑,见下面
- StealFromPeer:当前线程_freelist为空,相邻线程_freelist不为空,从相邻线程偷空间 ==待实现==

慢启动算法:(slow-start algorithm),类似TCP的拥塞控制算法
- 一次只需要一个,但为了减少每次从CentralCache取空间,加锁解锁的消耗,一次可以给多个(慢启动控制)
int num = SMALL_OBJ_MAX_BYTE / size;// 对象小,一次批量多取一些,对象大,一次批量少取一些- lambda函数LimitContral控制num在[2, 512]区间
- 慢启动逻辑:
min(_freelist_array[idx].MaxSize(), LimitContral()),取小的 若未超过LimitContral区间,则继续慢启动_freelist_array[idx].MaxSize() += 1//可控制启动速度(改为乘方...)获取空间:
- 调用CentralCache::FetchRangeFreeListForThreadCache(start, end, BatchNum, size)函数进行切分,BatchNum为慢启动计算出的目的freelist个数
- FetchRangeFreeListForThreadCache()逻辑:取得一块非空Span,进行切分,如果达不到BatchNum个,获得实际ActualNum个,返回
tcmalloc中并没有单独为CentralCache封装为一个类,只是一个逻辑上的概念,其本质是CentralFreeList类型的数组
这里将CentralCache设计为单例模式的饿汉模式 ==(注意:懒汉模式在配合定长内存池脱离使用new的时候有问题,见后面部分)==
- 系统中该类只有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享
单例模式参考:C++设计模式
class CentralCache { public: static CentralCache* GetInstance(); //class RecycleCentralCache { //public: // ~RecycleCentralCache() // { // if (CentralCacheInstance) // CentralCache::CCPool.OP_delete(CentralCacheInstance); // } //}; //static RecycleCentralCache RCC;//程序结束自动调用RecycleCentralCache析构函数释放单例对象 private: //singleton_pattern CentralCache()//防构造 {} CentralCache(const CentralCache& copy) = delete;//删除拷贝构造 CentralCache& operator=(const CentralCache& lvalue) = delete;//删除operator= static CentralCache CentralCacheInstance; //static ObjectPool<CentralCache> CCPool; public: // 获取一个非空的span Span* FetchOneSpan(size_t size); // 从CentralCache获取一定数量的对象给thread cache size_t FetchRangeFreeListForThreadCache(void*& start, void*& end, size_t batchNum, size_t size); void ReleaseListToSpans(void* start, size_t size); static std::mutex _mtx;//所有线程共享互斥锁 private: //spanlist SpanList _spanlist_array[MAXSPANLIST]; //std::vector<SpanList> _spanlist_array; };三个成员函数
- FetchRangeFreeListForThreadCache:从_spanlist_array为ThreadCache获取一段空间
- FetchOneSpan:配合FetchRangeFreeListForThreadCache使用,当_spanlist_array为空,从PageCache获取
- ReleaseListToSpans:ThreadCache::ListTooLong调用的函数,用于释放逻辑,见下面

逻辑:
- 先调用FetchOneSpan,模拟迭代器遍历_spanlist_array[idx],如果没有,找pagecache(注意加锁),
- 调用PageCache::FetchNewSpan,获取到span,把大块内存切成自由链表链接起来,把span挂到对应的桶里
- 回到FetchRangeFreeListForThreadCache函数, 从span->_freelist开始走,向后走BatchNum-1个Node到达end,但可能此span拆分成的FreeList节点不足BatchNum-1个,所以要记录ActualNum实际ThreadCache可以获得的自由链表节点数
- 注意:
span->_useCount += ActualNum;释放逻辑需要
tcmalloc中将其命名为PageHeap,堆,也就是接管了程序使用的内存空间,空间资源在这一层不用继续再向下归还,程序结束后会自动将所有空间释放
- 同时在这一层不止有一个大小129的SpanList数组,还有一个std::set用来管理超过1MB(128个page)的大span
这里简化了没有管理128page以上的span
同PageCache一样这里将CentralCache设计为单例模式的饿汉模式 ==(注意:懒汉模式在配合定长内存池脱离使用new的时候有问题,见后面部分)==
- 系统中该类只有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享
class PageCache { public: static PageCache* GetInstance(); /*class RecyclePageCache { public: ~RecyclePageCache() { if (PageCacheInstance) PCPool.OP_delete(PageCacheInstance); } }; static RecyclePageCache RPC;*/ private: PageCache() {} PageCache(const PageCache& copy) = delete; PageCache& operator=(const PageCache& lvalue) = delete; static PageCache PageCacheInstance; //static ObjectPool<PageCache> PCPool; public: Span* FetchNewSpan(size_t size); Span* MapToSpan(void* obj); void ReleaseSpanToPageCache(Span* span); static std::mutex _mtx;//既用于GetInstance也用于PageCache访问(static???) private: SpanList _pagelist_arry[MAXPAGELIST];//129个元素,0号元素不存储,1~128下标对应1~128大页Span ObjectPool<Span> _SpanPool; std::unordered_map<PAGE_ID, Span*> _pageMap; };三个函数接口:
- FetchNewSpan(加锁)
- MapToSpan:用于释放逻辑,见下面
- ReleaseSpanToPageCache:用于释放逻辑,见下面 (加锁)
锁:
- 如果仍用桶锁,效率低类比for循环外加锁和循环内 加锁
set管理128page以上的空间
- ==有时间再实现==

逻辑:
- 和FetchFromCentralCache中num一样的慢启动逻辑,针对页,计算页数,一次向系统获取几个页
- 先检查第PageNum个桶里面有没有span
- 检查后续桶,不为空就将其切分为两部分,分别链接到对应的桶 (==注意处理好_pageMap的映射关系,为回收内存准备==)
- 为空,向堆申请128页大小的空间,链入128page的桶,
- ==注意这里return FetchNewSpan(size):设计(递归一次)如果不这样写需要加锁:写法1:子函数_FetchNewSpan()内加锁 写法2:加递归锁recursive_mutex==
全局静态属性:申请释放:注意防止头文件包多个文件链接冲突 两个函数:
static void* ConcurrentAlloc(size_t size):调用ThreadCache::Allocate(通过TLS 每个pTLSThreadCache无锁的获取自己的专属的ThreadCache对象)static void ConcurrentFree(void* ptr, size_t size):调用ThreadCache::Deallocate
没有设计set来存大span
- 在ConcurrentAlloc中对于大于128page的申请,调用PageCache::FetchNewSpan逻辑:大于128 page的直接用VirtualAlloc向堆申请
tcmalloc中需要考虑更多的情况及逻辑,这里省略+简化
大体过程:

在ThreadCache::Deallocate()逻辑,先把需要释放部分Push到对应的FreeList,此时:
- 如果当前FreeList 的 Size > MaxSize,链表长度大于一次批量申请的内存时就调用ListTooLong()还一段MaxSize大小的链表给CentralCache
- FreeList类新增PopRange()成员函数,_size成员变量(注意PopFront PushFront, PushRange, PopRange对_size的操作) PopRange注意:截取后需要将NextNode(end)置空,切断与后续链表的链接
- PopRange获取起始位置start,调用CentralCache的ReleaseListToSpans函数
ReleaseListToSpans函数实现:
- 通过PageCache的成员函数MapToSpan函数获取当前对象属于哪块Span ==(对象,页号,Span映射关系及设计见PageCache回收内存 )==
- 注意:建立映射:FetchNewSpan逻辑中,PageNum_span中的每一个页号都要与PageNum_span建立映射,因为从ThreadCache还到CentralCache的freelist range其中的节点对象内存地址可能属于任意一个page,而需要页号才能找到span(==见下面PageCache的理论依据==)
- 只要在这块span上有任何内存还在被使用就不应该还回PageCache (同时不用管还回来的freelist节点的顺序已经乱了,注意物理地址一直都是连续的,只是链表逻辑乱序,直接头插就可以了,_useCount为0直接置空还回PageCache)

==理论依据==:任何内存地址>>PAGE_SHIFT都可以找到所在页的页号
- 测试:假设有两个页号分别为3000,3001
PAGE_ID id1 = 3000; PAGE_ID id2 = 3001; char* p1 = (char*)(id1 << PAGE_SHIFT); char* p2 = (char*)(id2 << PAGE_SHIFT); while (p1 < p2) { cout << (void*)p1 << ":" << ((PAGE_ID)p1 >> PAGE_SHIFT) << endl; p1 += 8;//每次+8字节(表示不同的地址) }结果如下:页号均相同
0000000001770000:3000 0000000001770008:3000 0000000001770010:3000 #... 0000000001771FE8:3000 0000000001771FF0:3000 0000000001771FF8:3000
PageCache需要一个_pageId和Span*的映射:unordered_map最快
- 对于为CentralCache提供的MapObjectToSpan接口(逻辑:通过对象地址找页号,再通过页号在unordered_map中找Span*)
- 对于私有成员
unordered_map<PAGE_ID, Span*> _pageMap用来记录_pageId与Span*的映射关系,==注意:tcmalloc中采用了两级PageMap减少TCMalloc元数据的内存占用(基数树,见后面)==
PageCache需要解决外碎片问题:
- 对于SizeClass的向上取整产生的内部碎片是不可避免的,只能尽量减少,但是这里的外碎片问题可以解决(防止过多小Span):将多个小span合并为大span
- PageCache里的Span向前后进行合并(==注意,判断前后Span是否空闲不能使用_useCount,因为在CentralCache中可能刚通过FetchNewSpan获得这个Span,正在进行切分(此时_useCount为0),有线程安全问题==),而应该再为Span增加一个属性:
bool _inUse是否正在使用- 注:FetchNewSpan逻辑中:切分Span后剩下的left_span只需要首尾页和left_pan的映射(PageCache合并的时候只是找前一个和后一个)
- 当判断合并会超过128pages的时候不进行合并
- 注意 delete被合并的span
- 注意合并完后插入后要再进行页号与span的映射,方便下次合并

对于大空间回收:ConcurrentFree调用PageCache::ReleaseSpanToPageCache逻辑:大于128 page的直接用VirtualAlloc归还给系统,
关于内存的问题非常难调试,加上多线程
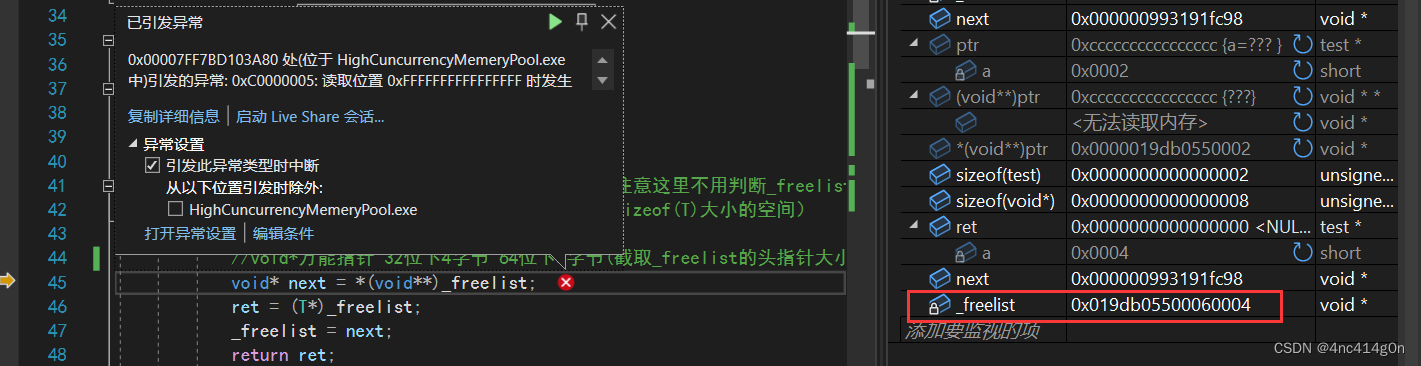
- ==错误1:找_pageId的时候:>>写成了<< (这里还算好调,跟着逻辑走一步,调用内存分布观察)==
- ==错误2:向PageCache获得span后进行切分,最后没有将切分好的freelist尾部置空,即NextNode(cur)=nullptr== (调试技巧:NextNode返回nullptr ,查看监视窗口,_size和实际的freelist的值不符合,在每一个需要改变_size的操作后加上_size和freelist实际大小的比较,找到第一层出错的地方,调用堆栈,向上层函数继续查找)
- ==建立映射只在if else 的else中进行了操作,if中未建立映射(最难调试)==
- ==脱离使用new的时候static ObjectPool<ThreadCache> TCPool; 去掉static(static变量导致线程安全问题,导致有线程OP_new获取返回的ret为NULL)==
可见即使借鉴tcmalloc的结构仍然比malloc慢不少,优化见下面

当无空间的时候VirtualAlloc向内存申请,分配给对象,对象释放时形成_freelist自由链表,暂时不归还给内存,下次再申请时不用向内存直接向_freelist申请
设计:(私有成员)
char* _memory = nullptr;//向堆申请的memory char1字节方便每次分配后指针向后++移动size_t _remainspacesize = 0;//memory剩余的空间大小(byte)void* _freelist = nullptr;//自由链表(管理归还的内存对象)详细设计,参见代码
- 设计自由链表(注意
sizeof(T)<sizeof(void*)?sizeof(void*):sizeof(T)情况,见下)- 使用replacement new模拟new在分配好空间后调用对象的构造函数的行为
- 显式调用对象的析构函数
速度测试:测试T对象为test (私有一个short型的成员函数)
- 参见文件:ObjectPool_speed_test.cpp
- 测试结果:
new/delete(malloc): 38ms ObjectPool :OP_new/OP_delete(VirtualAlloc): 11ms
注意:
- Windows下malloc底层也调用的VirtualAlloc,但malloc需要处理各种场景(综合条件下肯定更优秀)
- 这里的实现的简易定长内存池ObjectPool仅仅为了脱离使用new,针对的场景只有一种,不需要处理各种其他业务逻辑,速率自然相对更快

关于
*(void**)ptr取ptr头上指针个字节:
- 复习
*(void*)ptr,void 型指针,不知道指向的地址内容要怎么去引用它,而*(int*)ptr就可以正确打印,而 void 型的指针的指针*(void**),却可以知道其指向的地址内容是一个地址
- 对于
*(int*)ptr打印 0- 对于
*(void**)ptr打印0000000000000000- 对于
(void*)ptr打印000002A4EA4F0000- 对于
(void**)ptr打印000002A4EA4F0000
注意:
(*(void**))ptr语法报错,要么直接*(void**)ptr或显式加上括号*((void**)ptr)
关于
sizeof(T)<sizeof(void*)?sizeof(void*):sizeof(T)
- 为了正确形成_freelist链表 (防止T对象的大小小于一个指针的大小)
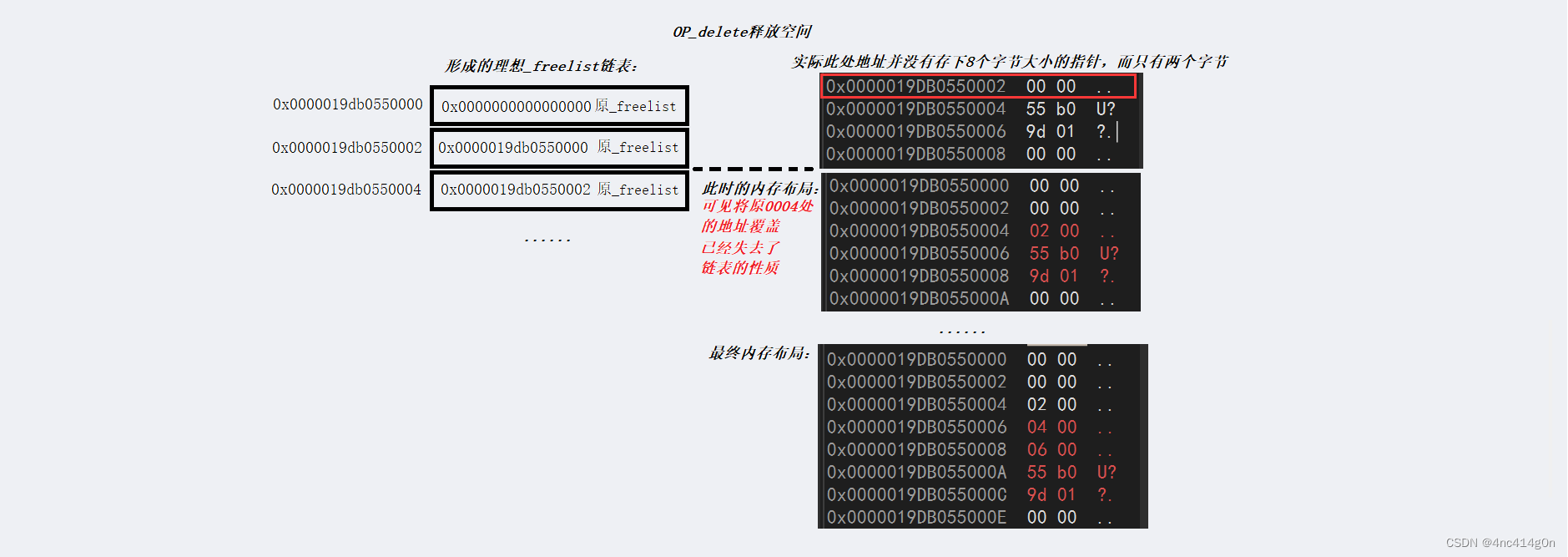
- 假设为按顺序释放(方便过程分析,delete顺序不一样没有影响):第一次OP_delete释放空间,形成_freelist
- 定长内存池再次分配空间:此时从_freelist取:
- 此时_freelist并不是理想的0x0000019DB0550004而是一个未分配给程序的空间地址0x019db05500060004

==上面说到不能使用懒汉模式==:
- 对于懒汉模式: 以CentralCache为例,static GetInstance函数内会使用new创建单例对象,使用定长内存池来替换new时,需要定义一个
static ObjectPool<CentralCache> CCPool对象来进行OP_new()操作,OP_new()内的定位new会显式调用对象的构造函数,而单例模式,构造函数私有化,调用replacement new报错,还有,单例对象私有的SpanList数组也不能初始化,导致之后使用锁资源时出错- 而对于饿汉模式: 在main函数开始之前就创建对象并初始化,而完美避开
ObjectPool<CentralCache> CCPool,所以在这里饿汉模式是较好的选择
脱离new:
- 为SpanList类定义一个私有的
ObjectPool<Span> SpanPool;- ConcurrentAlloc内部创建ThreadCache对象时的
static ObjectPool<ThreadCache> TCPool;- ...
- 宏定义(static const取代宏):==static const 代替 #define( effective c++ 条款02 )==
//static const 代替 #define( effective c++ 条款02 ) static const size_t SMALL_OBJ_MAX_BYTE = 256 * 1024;//小对象 < 256kb static const size_t BIG_OBJ_MAX_BYTE = 1024 * 1024;//256kb < 中对象 < 1MB, //大对象 > 1MB static const size_t PAGE_SHIFT = 13;//8kb一页 static const size_t MAXFREELIST = 208;//ThreadCache static const size_t MAXSPANLIST = 208;//CentralCache static const size_t MAXPAGELIST = 129;//PageCache
- 32和64位下的PAGE_ID类型的定义:
#ifdef _WIN64 typedef unsigned long long PAGE_ID; #elif _WIN32 typedef size_t PAGE_ID; #else// linux #endif
- windows.h:VirtualAlloc/VirtualFree (Linux:brk/mmap / sbrk/unmmap)
#ifdef _WIN32 //windows中 _WIN32(64/32 均有此macro) #include<windows.h> //VirtualAlloc #else //Linux #include <unistd.h>//brk #include <sys/mman.h>//mmap #endif //SystemAlloc void* SystemAlloc(size_t size)//封装统一接口 { //按页申请 size_t kpages = (size >> 13); #ifdef _WIN32 void* newmemory = VirtualAlloc(0, kpages << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE); //void* newmemory = (void*)VirtualAlloc(0, kpages*(1>>12), MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE); #else //mmap: void* ptr = mmap(0, kpage * (1 << 13), PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, 0, 0); //brk... #endif if (newmemory == nullptr) throw std::bad_alloc(); return newmemory; } //SystemFree inline static void SystemFree(void* ptr) { #ifdef _WIN32 VirtualFree(ptr, 0, MEM_RELEASE); #else #include "PageCache.h" Span* span = PageCache::GetInstance()->MapToSpan(ptr); size_t size = span->_objSize; munmap(ptr, size); // sbrk ... #endif }
- WindowsTLS 和 Linux gcc TLS
#ifdef _WIN32 static __declspec(thread) ThreadCache* pTLSThreadCache = nullptr;//写法2: #else //linux static tls GCC语言级别(非API)... static __thread ThreadCache* pTLSThreadCache = nullptr; //pthread库:API(动态) //int pthread_key_create(pthread_key_t* key, void (*destructor)(void*)); //int pthread_key_delete(pthread_key_t key); //void* pthread_getspecific(pthread_key_t key); //int pthread_setspecific(pthread_key_t key, const void* value); #endif
- 自旋锁:Linux的pthread库有实现,直接调用即可(Windows需自行实现) linux下使用Centralcache使用
自旋锁:POISX库 Windows自己实现自旋锁实现:见后面的优化
Linux中可以使用:
void* malloc(size_t size) THROW attribute__ ((alias (tc_malloc)))进行直接替换工程中使用的malloc为tcmalloc 详见:关于tcmalloc:参考上一篇博客
Windows vs studio中没有gcc的这个属性需要使用hook:Windows中的Hook机制
Linux的pthread库中实现了一套自旋锁API
DEFINE_SPINLOCK(spinlock_t lock) //定义并初始化化一个自旋锁 int spin_lock_init(spinlock_t *lock) //初始化自旋锁 void spin_lock(spinlock_t *lock) //获取指定的自旋锁 即加锁 void spin_unlock(spinlock_t *lock) //释放自旋锁 或 解锁 int spin_trylock(spinlock_t *lock) //尝试获取指定的自旋锁,如果没有获取到就返回 0 int spin_is_locked(spinlock_t *lock) //检查指定的自旋锁是否被获取,如果没有被获取就返回非 0,否则返回 0 void spin_lock_irq(spinlock_t *lock) //禁止本地中断,并获取自旋锁 void spin_unlock_irq(spinlock_t *lock) //激活本地中断,并释放自旋锁 void spin_lock_irqsave(spinlock_t *lock,unsigned long flags) //保存中断状态,禁止本地中断,并获取自旋锁 void spin_unlock_irqrestore(spinlock_t*lock, unsigned long flags)C++并没有提供自旋锁API,需要自行实现( ==待实现==),在Linux中为了方便使用,可以将pthread库封装为一个类方便使用: Linux:C++ 封装pthread
Free的时候只要一个指针参数即可,而ConcurrentFree还需要一个size参数: 将size优化掉:
- 法1:单独用一个和_pageMap一样的容器建立size和_pageId的映射
- 法2:struct Span再增加一个属性_objSize记录span对应的size,在从PageCache获得newspan后为newspan属性附上_objSize=size,ConcurrentFree调用时先用MapToSpan由指针获得对应的span,再从而获得size
关于_pageMap的访问加锁问题(防止死锁,使用RAII)
这里是引用
实现。。。