LLMVM is a CLI based productivity tool that uses Large Language Models and local Python tools/helpers to reason about and execute your tasks. A CLI client (client.py) either connects directly to an LLM provider or will connect to a local server (server.py) that coordinates tool execution, Retrieval Agumented Generation, document search and more.
It supports Anthropic's Claude 3 (Opus, Sonnet and Haiku) vision models, OpenAI GPT 3.5/4/4 Turbo/4o models from OpenAI. Gemini is currently experimental (it really really doesn't want to generate code in 'code' tags). It's best used with the kitty terminal as LLMVM will screenshot and render images as work on vision based tasks progresses.
Update October 8th 2024: Gemini. Simply refuses to emit
<code></code>tags so we've had to switch to<helpers></helpers>and</helpers_result>. Had to update the tools prompt to really really force gemini to not go out of bounds.
Update October 5th 2024: Added full Browser API to helpers - LLM can click, type and navigate the browser; refactored the agentic/helper code so you can build class/instance based agents that keep state between requests (see browser.py as an example).
Update September 21st 2024: Added GPT o1-preview and o1-mini support, but it's not great. o1 seems to struggle to follow current prompt instructions, and really doesn't want to emit the 'code' blocks.
Update July 3rd 2024: I've refactored most of how LLMVM works to use "continuation passing style" execution, where queries result in query -> natural language interleaved with code -> result, rather than the old query -> code -> natural language -> result. This results in significantly better task performance, so will be the default from here.
LLMVM's features are best explored through use case examples. Let's install, then go through some:
$ pip install llmvm-cli
$ playwright install
$ python -m llmvm.server
Default executor is: anthropic
Default model is: claude-3-5-sonnet-20240620
Make sure to `playwright install`.
If you have pip upgraded, delete ~/.config/llmvm/config.yaml to get latest config and helpers.
Loaded helper: datetime
Loaded helper: search_linkedin_profile
Loaded helper: get_linkedin_profile
Loaded helper: get_report
Loaded helper: get_stock_price
Loaded helper: get_current_market_capitalization
Loaded helper: get_stock_volatility
Loaded helper: get_stock_price_history
Loaded helper: sample_normal
Loaded helper: sample_binomial
Loaded helper: sample_lognormal
Loaded helper: sample_list
Loaded helper: generate_graph_image
Loaded helper: get_code_structure_summary
Loaded helper: get_source_code
Loaded helper: find_all_references
Loaded helper: get_weather
Loaded helper: address_lat_lon
Loaded helper: get_currency_rates
Loaded helper: get_bitcoin_rates
Loaded helper: get_central_bank_rates
Loaded helper: get_tvshow_ratings_and_details
Loaded helper: click
Loaded helper: close
Loaded helper: find_and_click_on
Loaded helper: get_selector
Loaded helper: goto
Loaded helper: type_into
INFO: Started server process [71093]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8011 (Press CTRL+C to quit)
$ python -m llmvm.client
...
I am a helpful assistant that has access to tools. Use "mode" to
switch tools on and off.
query>>
For the best experience, turning on all logging and very thorough (but expensive) content analysis, run the client and server with these settings:
LLMVM_EXECUTOR_TRACE="~/.local/share/llmvm/executor.trace" LLMVM_FULL_PROCESSING="true" LLMVM_EXECUTOR="anthropic" LLMVM_MODEL="claude-3-5-sonnet-20240620" LLMVM_PROFILING="true" python -m llmvm.client # and llmvm.serverQuick intro video here:
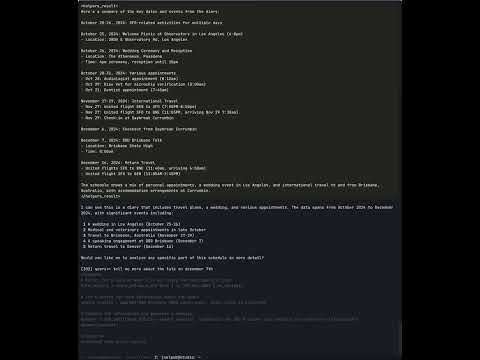
Now let's explore some use cases:
query>> go to https://ten13.vc/team and get the names of the people that work there
The LLMVM server is coordinating with the LLM to deconstruct the query into executable code calls various Python helpers that can be executed in the server process on behalf of the LLM. In this case, the server is using a headless Chromium instance to download the website url, screenshot and send progress back to the client, convert the website to Markdown, and hand the markdown to the LLM for name extraction. More on how this works later.
query>> I have 5 MSFT stocks and 10 NVDA stocks, what is my net worth in grams of gold?
...

Here we're calling Yahoo Finance to get the latest prices of Microsoft and NVidia. We're also using Google Search functionality to find the latest price of gold.
query>> -p docs/turnbull-speech.pdf "what is Malcolm Turnbull advocating for?"
LLMVM will parse and extract PDF's (including using OCR if the PDF doesn't extract text properly) and supply the LLM with the text as content for queries.
the -p path command can take shell globs, filenames and urls. Here's an example of collecting the entire llmvm codebase and passing it to LLMVM to build a tutorial in Markdown format:
query>> -p **/*.py !**/__init__.py !**/__main__.py "explain this codebase as a tutorial for a new person joining the team. Use markdown as the output"I bash/fish/zsh alias llm:
alias llm=LLMVM_EXECUTOR="anthopic" LLMVM_MODEL="claude-3-haiku-20240307" LLMVM_PROFILING="true" LLMVM_FULL_PROCESSING="true" python -m llmvm.clientor if you're using pyenv and want to hack on the source code and have your changes instantly reflected in the command line call:
function llm() {
local pyenv_ver=$(cat $HOME/llmvm/.python-version)
$PYENV_ROOT/versions/$pyenv_ver/bin/python -m llmvm.client "$@"
}and then:
cat somecode.py | llm -o direct "rewrite this code; make it cleaner and easier to read"Image understanding is supported on Anthropic Claude 3 models and OpenAI's GPT 4o vision model.
cat docs/beach.jpg | llm "generate a dalle prompt for the exact inverse of this image"
llm "generate cat names" > cat_names.txtllm -p meeting_notes.txt "correct spelling mistakes and extract action items"And some really nice Unix pipe foo:
llm "download the latest news about Elon Musk as bullet points" | \
llm "write a small blog post from the bullet points in the previous message" | \
llm "create a nice html file to display the content" > output.html
It integrates well with vim or your favorite editor to build multiline queries, or edit long message threads.
You can even Ctrl-y + p to paste images into the REPL for upload and parsing by Anthropic Claude 3 multimodal, or OpenAI's vision models.
You'll need either an OpenAI API account (including access to the GPT 4.x API), an Anthropic API account, or a Google Gemini API account. It's highly recommended to sign up for a free SerpAPI account to ensure that web searches (Google, News, Yelp and more) work. A sec-api.io is optional so LLMVM can download public company 10-K or 10-Q filings.
Ensure you have the following environment variables set:
ANTHROPIC_API_KEY # your Anthropic API key
OPENAI_API_KEY # your Openai API key, or ...
GEMINI_API_KEY # your Gemini API key
EDITOR # set this to your favorite terminal editor (vim or emacs or whatever) so you can /edit messages or /edit_ast the Python code before it gets executed etc.These are optional:
SERPAPI_API_KEY # https://serpapi.com/ API key for web and news searches.
SEC_API_KEY # if you want to use SEC's Edgar api to get 10K's and 10Q's etc, get an account at https://sec-api.io/and then:
pip install llmvm-cli
playwright install[Optional]
- Install viu for image rendering in macos/linux terminals
cargo install viu - (the kitty terminal renders images out of the box)
- run
docker.sh -g(builds the image, deploys into a container and runs the container) - python -m llmvm.server will automatically run on container port 8011. The host will open 8011 and forward to container port 8011.
- Use docker desktop to have a look at the running server logs; or you can ssh into the container, kill the server process, and restart from your own shell.
With the docker container running, you can run client.py on your local machine:
- export LLMVM_ENDPOINT="http://localhost:8011"
- python -m llmvm.client
You can ssh into the docker container: ssh llmvm@127.0.0.1 -p 2222
- open
~/.config/llmvm/config.yamland change executor to 'anthropic' or 'openai':
executor: 'anthropic' # or 'openai'
anthropic_model: 'claude-3-5-sonnet-20240620'or, you can set environment variables that specify the execution backend and the model you'd like to use:
export LLMVM_EXECUTOR='openai'
export LLMVM_MODEL='gpt-4o'
python -m llmvm.client "hello, who are you?"- open
~/.config/llmvm/config.yamland change profiling to 'true' or 'false'.
If the LLMVM server is running, profiling output will be emitted there, and if the server is not running, the LLMVM client will emit profiling information to the debug stream:
export LLMVM_PROFILING="true"
[0] query>> what is your name?
My name is Claude.
DEBUG ttlt: 1.19 ttft: 1.13 completion_time: 0.06 perf.py:132
DEBUG prompt_len: 12 completion_len: 8 perf.py:133
DEBUG p_tok_sec: 10.60 s_tok_sec: 1.68 stop_reason: end_turn perf.py:134
DEBUG p_cost: $0.00004 s_cost: $0.00003 request_id: perf.py:135
req_01CQhMdHqH6dWbp2n5mMNVCx
Assistant: My name is Claude.You can use the "expensive" mode of PDF and Markdown extraction where images are included along with the text of PDF and Markdown documents. The LLM will be used to guide the extraction process, resulting in a few extra calls and extra costs:
export LLMVM_FULL_PROCESSING="true"As an example of full processing, the HTML page at https://9600.dev/authors.html contains a table of best selling authors as an image (and not a html table):

Running this query with LLMVM_FULL_PROCESSING enabled:
query>> get https://9600.dev/authors.html and get all the author namesProduces:

When LLMVM_FULL_PROCESSING="true", all searches and their search results performed by LLMVM will be first "checked" to see if the url the Search Engine returned contains the actual data LLMVM cares about, and if not, will find the best available link on the page to click next to get the required data. (for example, Google links directly to the summary of arxiv.org papers, rather than the PDF paper itself, LLMVM will click the "View PDF" link to get the PDF)
I want to loosely compare the language outputs of two LLM calls, I can embed the result of an LLMVM call into the input of another using the -s (escape the result) and -t (add a string as a context message). An example:
[user_message] I want to compare the previous two messages. If they're loosely the same text or image, you can reply with "true". If they're different, reply with "false". "true" and "false" replies are case sensitive. You should focus on comparing context rather than word for word differences. If you're comparing images, they should be mostly the same image to return "true".
Ignore formatting and line breaks as differences. You can explain your reasoning for your choice after the # character, so: true # explanation
haiku -s -t \"$(haiku -s generate two sentences about prime ministers)\" -t \"$(haiku -s generate two sentences about presidents)\" -p scripts/compare.promptgives:
false # The two messages have different content. The first message is about the role and position of the prime minister in various countries, while the second message is about the role and position of the President of the United States. The context and subject matter of the two messages are different.
There are two helpers llm() and llmvm() you can use, or use the LLMVMClient class directly:
from llmvm.client.client import llm, llmvm, LLMVMClientassistant = llm('hello world')
Hello! How can I assist you today? Is there anything specific you'd like to talk about or any questions you have?
print(assistant)
Assistant(Hello! How can I assist you today? Is there anything specific you'd like to talk about or any questions you have?)
llm() connects directly to the specified executor (Anthropic, OpenAI, or Gemini), and llmvm() connects to an instance of the LLMVM server for tool handling and so on.

- Write arbitrary natural language queries that get translated into Python code and cooperatively executed.
- Upload .pdf, .txt, .csv and .html and have them ingested by FAISS and searchable by the LLMVM.
- Add arbitrary Python helpers by modifying ~/.config/llmvm/config.yaml and adding your Python based helpers. Note: you may need to hook the helper in python_runtime.py. You may also need to show examples of its use in prompts/python/python_tool_execution.prompt
- server.py via /v1/chat/completions endpoint, mimics and forwards to OpenAI's /v1/chat/completions API.
- Use client.py without running the server. Tools no longer work, but most other things do.
- TODO: build real time streaming, so you can wire up pipelines of llmvm execution to arbitrary streams of incoming data.
- TODO: search is weak. Make it better.
- TODO: all the threading and asyncio stuff is not great. Fix it. Might use RxPy.
- TODO: local llama can work, but doesn't work well.
Each step of statement execution is carefully evaluated. Calls to user defined helper functions may throw exceptions, and code may be semantically incorrect (i.e. bindings may be incorrect, leading to the wrong data being returned etc). LLMVM has the ability to back-track up the statement execution list (todo: transactional rollback of variable assignment is probably the right call here but hasn't been implemented yet) and work with the LLM to re-write code, either partially or fully, to try and achieve the desired outcome.
The code that performs error correction starts here, but there's still a bit more work to do here, including having the LLM engage in a "pdb" style debugging session, where locals in the Python runtime can be inspected for code-rewriting decisions.
You can define any arbitrary helper, and add it to the Python Runtime in pythonRuntime.setup(). It'll automatically generate the helper tool's one-shot prompt example for the LLM, and will appear in the LLM responses for Python generated code. The LLMVM runtime will sort out the binding and marshalling of arguments via llm_bind().
Here are the list of helpers written so far:
def BCL.datetime(self: object, expr: object, timezone: object) -> datetime # Returns a datetime object from a string using datetime.strftime(). Examples: datetime("2020-01-01"), datetime("now"), datetime("-1 days"), datetime("now", "Australia/Brisbane")
def WebHelpers.search_linkedin_profile(first_name: string, last_name: string, company_name: string) -> str # Searches for the LinkedIn profile of a given first name and last name and optional company name and returns the LinkedIn profile information as a string. If you call this method you do not need to call get_linkedin_profile().
def WebHelpers.get_linkedin_profile(linkedin_url: string) -> str # Extracts the career information from a person's LinkedIn profile from a given LinkedIn url and returns the career information as a string.
def EdgarHelpers.get_report(symbol: string, form_type: string, date: object) -> str # Gets the 10-Q, 10-K or 8-K report text for a given company symbol/ticker for a given date. This is useful to get financial information for a company, their current strategy, investments and risks. Use form_type = '' to get the latest form of any type. form_type can be '10-Q', '10-K' or '8-K'. date is a Python datetime.
def MarketHelpers.get_stock_price(symbol: string, date: string) -> float # Get the closing price of the specified stock symbol at the specified date
def MarketHelpers.get_current_market_capitalization(symbol: string) -> str # Get the current market capitalization of the specified stock symbol
def MarketHelpers.get_stock_volatility(symbol: object, days: object) -> float # Calculate the volatility of a stock over a given number of days.
def MarketHelpers.get_stock_price_history(symbol: object, start_date: object, end_date: object) -> Dict # Get the closing prices of the specified stock symbol between the specified start and end dates
def BCL.sample_normal(self: object, mean: object, std_dev: object) -> float # Returns a random sample from a normal distribution with the given mean and standard deviation. Examples: sample_normal(0, 1), sample_normal(10, 2)
def BCL.sample_binomial(self: object, n: object, p: object) -> float # Returns a random sample from a binomial distribution with the given number of trials and probability of success. Examples: sample_binomial(10, 0.5), sample_binomial(100, 0.1)
def BCL.sample_lognormal(self: object, mean: object, std_dev: object) -> float # Returns a random sample from a lognormal distribution with the given mean and standard deviation. Examples: sample_lognormal(0, 1), sample_lognormal(10, 2)
def BCL.sample_list(self: object, data: object) -> Any # Returns a random sample from a list. Examples: sample_list([1, 2, 3]), sample_list(["a", "b", "c"])
def BCL.generate_graph_image(self: object, data: object, title: object, x_label: object, y_label: object) -> NoneType # Generates a graph image from the given data and returns it as bytes.
def BCL.get_code_structure_summary(source_file_paths: object) -> str # Gets all class names, method names, and docstrings for each of the source code files listed in source_files. This method does not return any source code, only class names, method names and their docstrings.
def BCL.get_source_code(source_file_path: string) -> str # Gets the source code from the file at the given file path.
def BCL.get_all_references(source_file_paths: string, method_name: string) -> str # Find's all references to the given method in the source code files listed in source_files.Downloading web content (html, PDF's etc), and searching the web is done through special functions: download() and search() which are defined in the LLMVM runtimes base class libraries. download() as mentioned uses Chromium via Microsoft Playwright so that we can avoid web server blocking issues that tend to occur with requests.get(). search() uses SerpAPI, which may require a paid subscription.
For our first example:
query>> go to https://ten13.vc/team and extract all the namesLet's walk through each line of the generated Python:
Assistant: Certainly! I will download the webpage and extract the names of the people who work at Ten13
<helpers>
var1 = download("https://ten13.vc/team")
The <helpers> block creates a Python runtime context and the LLMVM server will extract this code and execute it. Once the code is executed, the <helpers></helpers> block is replaced with <helpers_result></helpers_result> but the Python runtime context is kept alive for any further execution of <helpers> blocks later.
The download() function is part of a set of user definable base class libraries that the LLM knows about: download() llm_call() llm_list_bind(), llm_bind(), answer() and so on. download() fires up an instance of Chromium via Playwright to download web or PDF content and convert them to Markdown.
var2 = llm_call([var1], "extract list of names") # Step 2: Extract the list of namesllm_call(expression_list, instruction) -> str takes an expression list, packages those expressions up into a stack of LLM User messages, and passes them back to the LLM to perform the instruction. If the stack of Messages is too big to fit in the context window, faiss is used to chunk and rank message content via the following pseudocode:
- Chunk content via tiktoken, 256 token chunks.
- Take the original query "Go to the https://ten13.vc/team website ..." and the instruction query "extract list of names" and vector search and rank on message content.
- Take a random sample of chunks, ask the LLM to decide if all content is required to achieve success in the task.
- If "YES", Map-Reduce the task over all Message chunks.
- If "NO", fit top (n) chunks sized to context window and perform instruction.
- Return instruction result.
The map-reduce is done per-message, allowing for multiple expressions to be chunked and ranked independently, which is useful for queries like "download document 1, and document 2 and compare and contrast".
for list_item in llm_list_bind(var2, "list of names"): # Step 3: Loop over the list of namesllm_list_bind(expression, instruction) -> List takes an arbitrary expression, converts it to a string, then has an LLM translate that string into a Python list ["one", "two", "three", ...].
In this particular case, var2 has the following string, the response from GPT:
Based on the provided data, here is a list of names:
- Steve Baxter
- Stew Glynn
- An Vo
- Alexander Cohen
- Margot McQueen
- Sophie Robertson
- Seamus Crawford
And llm_list_bind() takes this arbitrary text and converts it to: ["Steve Baxter", "Stew Glynn", "An Vo", "Margot McQueen", "Sophie Robertson", "Seamus Crawford"]
var3 = llm_bind(list_item, "WebHelpers.search_linkedin_profile(first_name, last_name, company_name)")llm_bind(expression, function_definition_str) -> Callable is one of the more interesting functions. It takes an expression and a string based function definition and tries to bind arbitrary data to the function arguments (turning the definition into a callsite). It performs these steps:
- For these scopes [expression, original query, dictionary of currently in scope locals()] ask the LLM to bind the arguments (in this case: first_name, last_name, company_name).
- If the LLM can't bind any of the arguments, specify "None", then add a comment string "#" to the end of the callsite with a natural language question that, if answered, would allow the callsite to be bound. e.g:
- WebHelpers.search_linkedin_profile("Steve", "Baxter", None) # Which company does Steve Baxter work for?
- Move up a scope, and include the original binding ask, plus the LLM generated question, which combined greatly improves the odds of argument binding.
- (in this particular case, the company Steve Baxter works for is defined in the original webpage download() string, and when the LLM is passed the locals() dictionary, is able to self-answer the question of "which company Steve Baxter works for" and thus bind the callsite properly).
- -> WebHelpers.search_linkedin_profile("Steve", "Baxter", "Transition Level Investments")
answer(answers) # Step 7: Show the summaries of the LinkedIn profiles to the useranswer() is a collection of possible answers that either partially solve, or fully solve for the original query. Once code is finished executing, each answer found in answers() is handed to the LLM for guidance on how effective it is at solving/answering the query. The result is then shown to the user, and in this case, it's a career summary of each of the individuals from TEN13 extracted from LinkedIn.
The underlying LLM programming model is as follows:
Query -> Natural Language interleaved with <helpers> blocks -> stop_token of <helpers> -> Python environment execution of <helpers> block -> replace <helpers> block with the result <helpers_result> of code execution -> ask the LLM to continue by passing the entire result in as an "Assistant" message which forces the LLM to continue a completion - natural language or code will continue to be written until the task is complete (repeat until stop_token='stop' or '</complete>').
The other 'nifty trick' here is that you give the LLM the ability to call itself within a <helpers> block with a fresh "call stack" via the llm_call() API, allowing for arbitrary compute without forcing the LLM to interpret the previous conversational User/Assistant messages.
The Python runtime uses Playwright to automate Chromium on its behalf. By default, it runs Chromium in headless mode, but this can be changed in ~/.config/llmvm/config.yaml:
chromium_headless: trueYou can also copy your own browsers cookies file into Playwright's Chromium automation instance. This allows the Playwright instance to use your session cookies for sites like LinkedIn. Simply:
- run
scripts/extract_firefox_cookies.sh > cookies.txt - move the cookies.txt file to a secure location
- update
config.yamlto point to the cookies file:
chromium_cookies: '~/.local/share/llmvm/cookies.txt'Chrome makes things more complicated. You can use J2Team Cookies extension to extract cookies per site, save as a json file, then:
cd scripts
cat cookie.txt | python extract_chrome_json.py >> ~/.local/share/llmvm/cookies.txtChatGPT supports 'function calling' by passing a query (e.g. "What's the weather in Boston") and a JSON blob with the signatures of supporting functions available to be called locally (i.e. def get_weather(location: str)...). Examples seen here.
However, this interaction is usually User Task -> LLM decides what helper function to call -> local host calls helper function -> work with result, and does not allow for arbitrary deconstruction of a task into a series of helper function calls that can be intermixed with both control flow, or cooperative sub-task execution.
This prototype shows that LLM's are capable of taking a user task, reasoning about how to deconstruct the task into sub-tasks, understanding how to program, schedule and execute those sub-tasks on its own or via a virtual machine, and working with the VM to resolve error cases. We ask the LLM to use Python expressed as A-normal form as the programming language, and execute Python statement-by-statement on a local Python interpreter. When errors arise (syntax errors, exceptions, or semantic problems), we pause execution and work with the LLM to understand and resolve the error by exposing the locals dictionary, and allowing the LLM to "debug" the current execution state.
You can use the act command, which will search awesome prompts and set the System Prompt to "act" like the awesome prompt you select.
A fun one is graphing "narrative extraction", which is useful for quickly summarizing news articles:
Download two news articles and put them in the "Messages" stack:
query>> url https://www.cnn.com/2023/08/27/football/what-happened-luis-rubiales-kiss-intl/index.html
query>> url https://www.bbc.com/sport/football/66645618query>> act graph"extract the narrative from the documents I sent you in the first two messages"Gives us a GraphVis visualization (cut off to fit screen):

And related narrative extraction + code:

Using the LLM to inspect a sourcebase also works quite well:
query>> looking at the source in ~/dev/llmvm, find the best place to add a shutdown() option to the client which shuts down the server.
Assistant: Certainly! Lets examine the source code structure in the ~/dev/llmvm directory to find the best place to add a shutdown() option to
the client that will shut down the server.
<helpers>
source_code_files = BCL.get_code_structure_summary(["~/dev/llmvm"])
answer(source_code_files)
</helpers>
<helpers_result>
... ...
...
- Error handling still needs a lot of work. I need to move this to be more continuation passing style than execute blocks of code then re-write.
- Working on Source Code insights (mode 'code'). You'll be able to hand it a project directory and work with the LLM to understand what the code is doing. Check out source.py
- Playwright browser control integration from the LLM -- it should be straight forward to have cooperative execution for the task of proceeding through web app flows (login, do stuff, extract info, logout).
- Fix bugs and refactor. The code is still pretty hacky as I've re-written it several times with different approaches.
- Write some better docs.
These days, I mostly run Anthropic's models. Their super fast, cheap, and smart. In my .zshrc, I have aliases for servers and clients, with full performance tracing and debugging enabled:
OPUS="claude-3-opus-20240229"
SONNET="claude-3-sonnet-20240229"
HAIKU="claude-3-haiku-20240307"
INSTANT="claude-instant-1.2"
# servers
alias sopus='ANTHROPIC_API_KEY=$ANT_KEY LLMVM_EXECUTOR="anthropic" LLMVM_FULL_PROCESSING="true" LLMVM_MODEL=$OPUS LLMVM_PROFILING="true" LLMVM_API_BASE="https://api.anthropic.com" LLMVM_EXECUTOR_TRACE="~/.local/share/llmvm/executor.trace" llmvm_serve'
alias ssonnet='ANTHROPIC_API_KEY=$ANT_KEY LLMVM_EXECUTOR="anthropic" LLMVM_FULL_PROCESSING="true" LLMVM_MODEL=$SONNET LLMVM_PROFILING="true" LLMVM_API_BASE="https://api.anthropic.com" LLMVM_EXECUTOR_TRACE="~/.local/share/llmvm/executor.trace" llmvm_serve'
alias shaiku='ANTHROPIC_API_KEY=$ANT_KEY LLMVM_FULL_PROCESSING="true" LLMVM_EXECUTOR="anthropic" LLMVM_MODEL=$HAIKU LLMVM_PROFILING="true" LLMVM_API_BASE="https://api.anthropic.com" LLMVM_EXECUTOR_TRACE="~/.local/share/llmvm/executor.trace" llmvm_serve'
alias sinstant='ANTHROPIC_API_KEY=$ANT_KEY LLMVM_EXECUTOR="anthropic" LLMVM_MODEL=$INSTANT LLMVM_PROFILING="true" LLMVM_API_BASE="https://api.anthropic.com" llmvm_serve'
alias sgpt4o='LLMVM_EXECUTOR="openai" LLMVM_MODEL="gpt-4o" LLMVM_PROFILING="true" llmvm_serve'
# clients
alias sonnet='ANTHROPIC_API_KEY=$ANT_KEY LLMVM_EXECUTOR="anthropic" LLMVM_FULL_PROCESSING="true" LLMVM_MODEL=$SONNET LLMVM_PROFILING="true" LLLMVM_EXECUTOR_TRACE="~/.local/share/llmvm/executor.trace" LMMVM_API_BASE="https://api.anthropic.com" llm'
alias haiku='ANTHROPIC_API_KEY=$ANT_KEY LLMVM_FULL_PROCESSING="true" LLMVM_EXECUTOR="anthropic" LLMVM_MODEL=$HAIKU LLMVM_PROFILING="true" LLMVM_API_BASE="https://api.anthropic.com" LLMVM_EXECUTOR_TRACE="~/.local/share/llmvm/executor.trace" llm'
alias opus='ANTHROPIC_API_KEY=$ANT_KEY LLMVM_FULL_PROCESSING="true" LLMVM_EXECUTOR_TRACE="~/.local/share/llmvm/executor.trace" LLMVM_EXECUTOR="anthropic" LLMVM_MODEL=$OPUS LLMVM_PROFILING="true" llm'
alias instant='ANTHROPIC_API_KEY=$ANT_KEY LLMVM_EXECUTOR="anthropic" LLMVM_MODEL=$INSTANT LLMVM_PROFILING="true" LLMVM_API_BASE="https://api.anthropic.com" llm'
alias gpt4o='LLMVM_EXECUTOR="openai" LLMVM_MODEL="gpt-4o" LLMVM_PROFILING="true" llm'
alias h=haiku
alias l=gpt4oAnd the zsh functions:
function llm() {
current_env=$CONDA_DEFAULT_ENV
conda activate llmvm
PYTHONPATH=$HOME/dev/llmvm python -m llmvm.client "$@"
conda activate $current_env
}
function llmvm_serve() {
current_env=$CONDA_DEFAULT_ENV
conda activate llmvm
PYTHONPATH=$HOME/dev/llmvm python -m llmvm.server
conda activate $current_env
}And then it's as simple as:
$ h "hello world"
Assistant: Hello! I'm an AI assistant created by Anthropic. How can I help you today?It's often helpful to pass in your command line history plus a little info about yourself to help the models rationalize your request:
In the file $HOME/dev/context.md, I have:
# Personal Information
My name is Sonny.
I live in the Bay Area in California.
I'm really interested in LLM's, hiking, biking and eating.
Today's date is {date +"%A, %d %B, %Y"}.Anything in { } brackets in this file, will be replaced by the return result from the execution of that command.
function con() {
if [ "$#" -ne 1 ]; then
echo "Usage: context 'instruction or query'"
return 1
fi
local instruction=$1
local result=$(cat ~/.zsh_history | tail -n 100 | cut -d';' -f2-)
temp_file=$(mktemp)
echo "The following is my linux command history for the last little while. It might be useful for future messages.\n\n" >> "$temp_file"
echo result >> "$temp_file"
# parse and execute commands in the context file
local context_file=$HOME/dev/context.md
local context_temp=$(mktemp)
while IFS= read -r line || [ -n "$line" ]; do
# Replace {command} with the output of the command
processed_line=$(echo "$line" | awk '{
while (match($0, /\{[^}]+\}/)) {
cmd = substr($0, RSTART+1, RLENGTH-2)
cmd | getline result
close(cmd)
$0 = substr($0, 1, RSTART-1) result substr($0, RSTART+RLENGTH)
}
print
}')
echo "$processed_line" >> "$context_temp"
done < "$context_file"
l -p $temp_file -p $context_temp $instruction
rm $temp_file
rm $context_temp
}$ con "hey there, can you give me a list of things to do?"Assistant:
Seeing as you life in the Bay Area, it offers a wide range of activities and attractions to suit various interests. Here are some ideas for things you can do today:
### Outdoor Activities:
1. **Golden Gate Park**: Explore the park's gardens, museums, and recreational areas.
2. **Hiking**: Try trails in places like Muir Woods, Mount Tamalpais, or the Marin Headlands.
3. **Biking**: Rent a bike and ride across the Golden Gate Bridge.
4. **Beaches**: Visit Ocean Beach, Baker Beach, or Crissy Field for a relaxing day by the water.
### Cultural Experiences:
1. **Museums**: Check out the San Francisco Museum of Modern Art (SFMOMA), the Exploratorium, or the California Academy of Sciences.The scripts directory also contains some fun stuff to try out:
scripts/buffer.py: A simple buffering script that will run a command, wait for the output to stop changing/rendering for a certain amount of time, and then emit the last 'frame' of output, allowing you to send a 'frame' of the command to an LLM:
python buffer.py -s 500 "htop -C" | sonnet "extract the top process"
Based on the htop output, the top process is:
PID: 24234
CPU%: 55.4
Command: htop -CWith a quick regex extractor for numbers:
function num() {
local input
# Check if there's piped input
if [[ -p /dev/stdin ]]; then
input=$(cat)
else
input="$1"
fi
# Use grep to extract the number
local number=$(echo "$input" | grep -oE '[+-]?[0-9]*\.?[0-9]+' | head -n1)
if [[ -n "$number" ]]; then
echo "$number"
return 0
else
echo "No number found in the input string." >&2
return 1
fi
}You can do fun things like:
python buffer.py -s 500 "htop -C" | sonnet "find spotify pid" | num | xargs kill -9scripts/generate_markdown.py: A script that will convert a PDF (any format, including image) to Markdown. It will also extract the images from the PDF and embed them in the Markdown output.
scripts/chrome-pdf.sh: A MacOS osascript script that will create a PDF from the current Chrome tab, save it to a temporary location, and then find a running instance of the llmvm client and paste the PDF into it.