Don't insert redundant run layer calls inside a basic block #1665
Conversation
Signed-off-by: Chris Hellmuth <chellmuth@gmail.com>
|
Looks great. Is there any change to the output of the shader? Does this change the number of actual layer-to-layer calls when a shader is executed? |
| else | ||
| already_run->insert(con.srclayer); // mark it | ||
| } | ||
|
|
There was a problem hiding this comment.
Can you explain a bit on what the difference between the removed code block with the "local" already_run set and the m_layers_already run? And how removing the block improves things?
There was a problem hiding this comment.
Definitely!
The "local" already_run is restricted in scope to preventing redundant checks originating from a single useparam op. The new m_call_layers_inserted set will prevent all redundant checks in the scope of an entire basic block.
Consider this shader:
shader example_shader(ConnectionData my_input = {})
{
if (u > 0.0) {
float r = my_input.x * my_input.y;
Ci = color(r, 0, 0) * emission();
} else {
float r = my_input.x * u;
float g = my_input.y * v;
Ci = color(r, g, 0) * emission();
}
}
Its control flow graph looks like this:
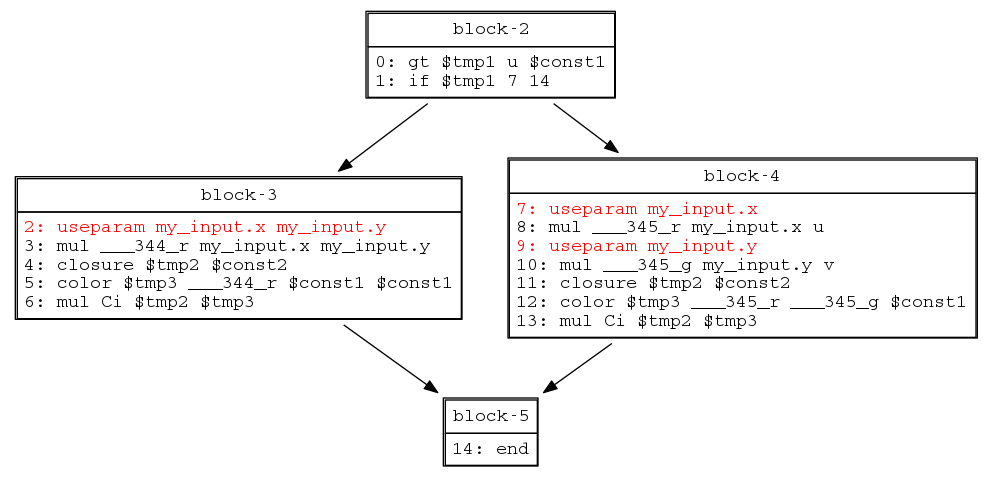
The existing already_run check would catch the "then" redundancy (block-3), but not the "else" redundancy (block-4). m_call_layers_inserted catches both- hence the removal of already_run.
m_layers_already_run is scoped to the entire main section of the instance, but only catches cases where the prior call happened outside of a conditional. That's why all my examples are wrapped in if-statements.
There was a problem hiding this comment.
This may be the most interesting reply to a review comment in this project's history. The visualization of the oso IR is extremely helpful.
Is the script or whatever you used to generate that graph something that makes sense to check into the project? I can imagine it being really helpful for a variety of debugging tasks, not to mention documenting internals of the shader optimization.
There was a problem hiding this comment.
Thank you! The script generation is pretty messy - I write metadata to a file during basic block construction, then transform it into a .dot file with a python script later on.
I'll open a draft PR with what I've got, and maybe you'll have some advice for getting it into a mergeable state. (It would open the door for PR'ing shader group instance graphs as well)
There was a problem hiding this comment.
Make a draft, sure. I've never looked directly at the .dot format to see what it looks like, so I'll be interested to see the interplay with what you output from our library and what you do with the python script after. Considering how generally useful this kind of output seems as a debugging tool, I wonder if it's worth investing in a simple wrapper class that hides the details and will output the .dot directly? (Or maybe something exists? I'm thinking of the kind of library like where you can make just a couple calls to make a nested dictionary and they it'll output a correctly formatted json.)
There shouldn't be any semantic difference. While testing, I changed all omitted layer checks to assertions that the layer had already been run, and didn't trigger any exceptions.
It shouldn't, and would be a bug if it did, but I didn't log that and verify. |
| @@ -2606,6 +2608,8 @@ class OSOProcessorBase { | |||
| std::vector<char> m_in_conditional; ///< Whether each op is in a cond | |||
| std::vector<char> m_in_loop; ///< Whether each op is in a loop | |||
| int m_first_return; ///< Op number of first return or exit | |||
| std::set<std::pair<int, int>> | |||
| m_call_layers_inserted; ///< Lookup for (bblockid, layerid) | |||
There was a problem hiding this comment.
Would something more self documenting than std::pair<int,int> be useful for readability and maintenance? IE:
struct CallLayerKey {
int bblockid;
int layerid;
};
There was a problem hiding this comment.
Cool, I'll improve this in a follow-up PR that also ports the changes to the batched code path.
|
Could you add the same changes in the batched version: batched_llvm_gen.cpp and batched_llvm_instance.cpp? |
|
Alex is right. I was thinking that this was all oso manipulation, and it slipped my mind that because this happens as we're generating LLVM IR from he oso IR, it will need a corresponding change for batched shading, so I merged without remembering to make that request. It should be straightforward a straightforward change for you, Chris, since this doesn't in any way need any deep knowledge of how the SIMD code works. |
Copy-paste the run layer call checks from #1665 into the batched execution mode. Signed-off-by: Chris Hellmuth <chellmuth@gmail.com>
This patch is a very simple part one of work to optimize the number of conditional run layer calls that OSL makes, which take the form:
if (!groupdata->run[parentlayer])
parent_layer([...]);
After examining our slowest JIT’ing shaders on gpu, @tgrant-nv showed us that these run layer calls were significantly bloating our ptx and slowing down their compilation. Many of them are unnecessary because static analysis can show we are guaranteed to have already run the layer in question.
For example, reading different fields from a connected struct like below will often generate multiple conditional run layer calls:
```
struct Pair {
float x;
float y;
};
shader example_shader(Pair p = {})
{
if ([…]) {
float xx = p.x;
float yy = p.y;
[…]
}
}
```
Since this is not really a performance issue on cpu (runtime overhead is just checking the conditional bit), OSL doesn’t make a huge effort to optimize away these redundant cases. Each useparam op will be careful not to insert more than one per layer, and code that is called unconditionally in the main section of the shader will also not have redundant checks, but there are plenty of examples like above that are not currently removed.
This patch takes a basic first step, adding metrics to track run layer call counts and removing duplicate run layer calls inside a basic block, covering cases like the example above.
On my set of production test scenes, this alone removes anywhere from 20-50% of total run layer calls, with our biggest shaders seeing the most improvement. Total ptx line reduction varies between 3-20%, and optix module compilation (jit time) is reduced between 1-15%.
Signed-off-by: Chris Hellmuth <chellmuth@gmail.com>
Copy-paste the run layer call checks from #1665 into the batched execution mode. Signed-off-by: Chris Hellmuth <chellmuth@gmail.com>
…d false positive (#1672) My initial implementation of the run layer check optimizations didn’t account for the fact that init ops for symbols have their llvm code generated before we build basic blocks from the OSL IR. This caused the code to be wrong in two ways: 1) the set of known run layer calls was being reset between instances too late in the pipeline, so a useparam inside an init op would actually be checking the previously compiled layer’s set, and 2) even when reset earlier, it assumed valid basic block ids existed for the init ops when they did not. So, if a layer had a useparam inside one of its init ops that generally matched the same code location as a useparam in the previously compiled layer, the run layer check could be incorrectly omitted. I’ve updated the code so that the default optimization behavior is reverted to the way it was before #1665, and added a new option opt_useparam that can be turned on to enable a fixed, restricted version of the optimization that only applies to code in the main section. I'm working on a test that properly triggers the issue. Signed-off-by: Chris Hellmuth <chellmuth@gmail.com>
Description
This patch is a very simple part one of work to optimize the number of conditional run layer calls that OSL makes, which take the form:
After examining our slowest JIT’ing shaders on gpu, @tgrant-nv showed us that these run layer calls were significantly bloating our ptx and slowing down their compilation. Many of them are unnecessary because static analysis can show we are guaranteed to have already run the layer in question.
For example, reading different fields from a connected struct like below will often generate multiple conditional run layer calls:
Since this is not really a performance issue on cpu (runtime overhead is just checking the conditional bit), OSL doesn’t make a huge effort to optimize away these redundant cases. Each useparam op will be careful not to insert more than one per layer, and code that is called unconditionally in the main section of the shader will also not have redundant checks, but there are plenty of examples like above that are not currently removed.
This patch takes a basic first step, adding metrics to track run layer call counts and removing duplicate run layer calls inside a basic block, covering cases like the example above.
On my set of production test scenes, this alone removes anywhere from 20-50% of total run layer calls, with our biggest shaders seeing the most improvement. Total ptx line reduction varies between 3-20%, and optix module compilation (jit time) is reduced between 1-15%.
Tests
I don't know how to write a test that asserts an intermediate result of an optimization (fewer run layer calls) instead of asserting that an image looks correct.
Internally, I replaced omitted run layer calls with asserts that
groupdata->run[parentlayer] == true, and ran against several test scenes totaling around a hundred or so shaders.Checklist: