A quick overview of the first assignment of CS50 AI: implement an algorithm to find the shortest path between two actors.
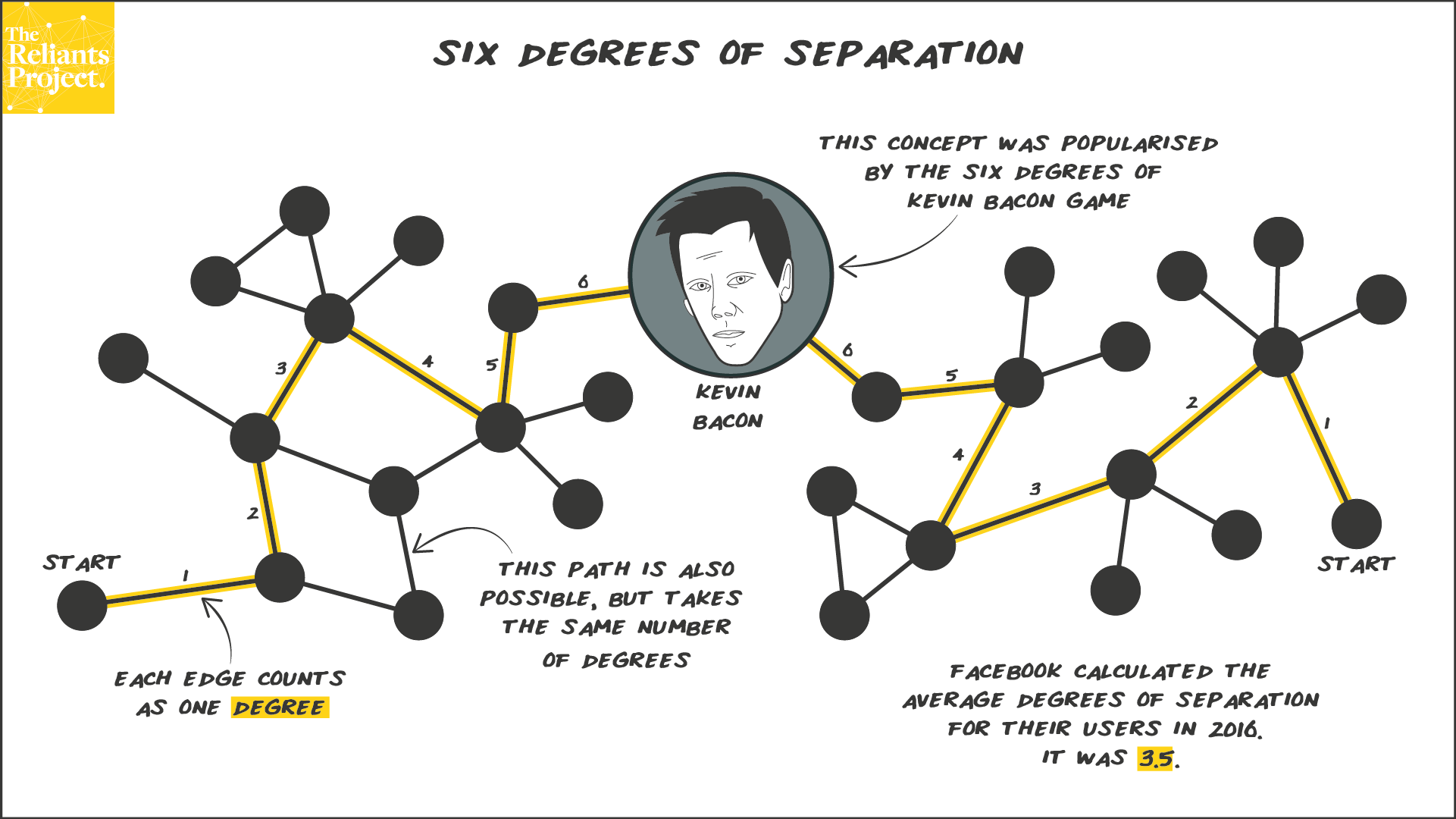
In this case we will be searching for the shortest path between two actors but without Bacon in between.
To run the program, execute the following command, then add 2 names of actors:
$ python degrees.py large
Loading data...
Data loaded.
Name: Emma Watson
Name: Jennifer Lawrence
3 degrees of separation.
1: Emma Watson and Brendan Gleeson starred in Harry Potter and the Order of the Phoenix
2: Brendan Gleeson and Michael Fassbender starred in Trespass Against Us
3: Michael Fassbender and Jennifer Lawrence starred in X-Men: First Class
The assignment specification can be found here: https://cs50.harvard.edu/ai/2020/projects/0/degrees/
Complete the implementation of the shortest_path function such that it returns the shortest path from the person with id source to the person with the id target.
- Assuming there is a path from the source to the target, your function should return a list, where each list item is the next (movie_id, person_id) pair in the path from the source to the target. Each pair should be a tuple of two strings. -- For example, if the return value of shortest_path were [(1, 2), (3, 4)], that would mean that the source starred in movie 1 with person 2, person 2 starred in movie 3 with person 4, and person 4 is the target.
- If there are multiple paths of minimum length from the source to the target, your function can return any of them.
- If there is no possible path between two actors, your function should return None.
- You may call the neighbors_for_person function, which accepts a person’s id as input, and returns a set of (movie_id, person_id) pairs for all people who starred in a movie with a given person.
You should not modify anything else in the file other than the shortest_path function, though you may write additional functions and/or import other Python standard library modules.
The implementation is based on the breadth-first search algorithm. The algorithm is implemented in the shortest_path function in degrees.py. The function takes two arguments: the source and the target. The function returns a list of actors that form the shortest path between the source and the target. If no path exists, the function returns None.
The main function in degrees.py takes care of the user input and the output. The function first asks the user for the name of the source actor. The function then asks the user for the name of the target actor. The function then calls the shortest_path function with the source and target as arguments. If a path exists, the function prints the path. If no path exists, the function prints a message to that effect.
The load_data function in util.py loads the data from the large dataset. The function returns a dictionary that maps actors to a set of movies in which they have acted. The function also returns a dictionary that maps movies to a set of actors that have acted in the movie.
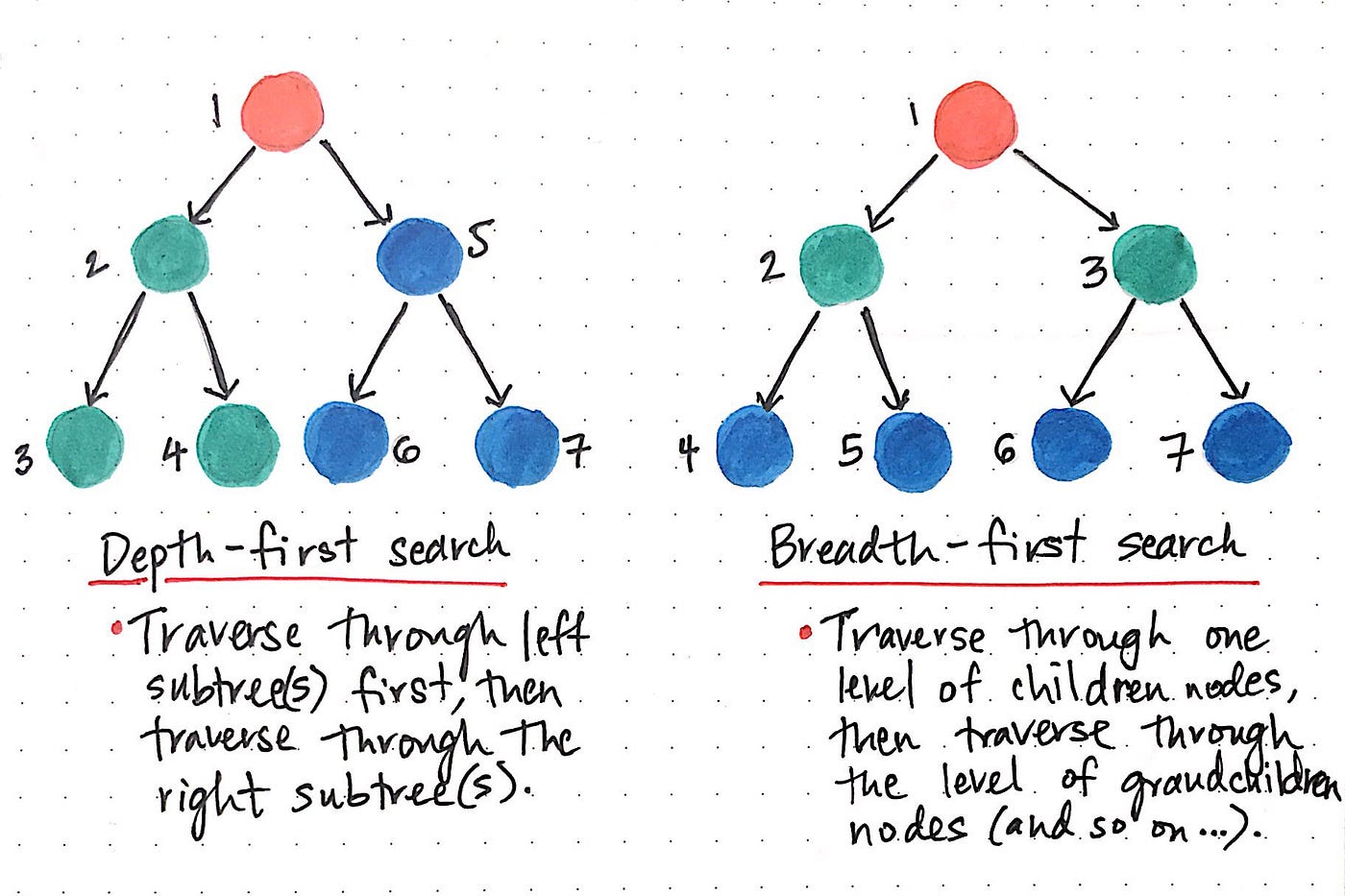
Breadth-first search is an algorithm for traversing or searching tree or graph data structures. It starts at the tree root (or some arbitrary node of a graph, sometimes referred to as a 'search key'[1]), and explores all of the neighbor nodes at the present depth prior to moving on to the nodes at the next depth level. It uses the opposite strategy as depth-first search, which instead explores the node branch as far as possible before being forced to backtrack and expand other nodes.
The data used in this project is based on the IMDb dataset. The data is available in the large and small datasets. The small dataset contains data for 100 actors and 100 movies. The large dataset contains data for 1M+ actors and 344k+ movies.