-
数组下标都是从0开始的。
-
数组的元素是不能删的,只能覆盖。
-
数组内存空间的地址是连续的。正是因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。
-
二维数组在内存的空间地址不是连续的。
二分法
- 在
数组:每次遇到二分法,都是一看就会,一写就废这道题目中,考察的数据的基本操作,思路很简单,但是在通过率在简单题里并不高,不要轻敌。 - 理解循环不变量原则,只有在循环中坚持对区间的定义,才能清楚的把握循环中的各种细节。
- 二分法是算法面试中的常考题,建议通过这道题目,锻炼自己手撕二分的能力。
双指针法(快慢指针法)
- 通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
- 双指针法在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法。
滑动窗口
- 在
数组:滑动窗口拯救了你这道题目中,要理解滑动窗口如何移动窗口起始位置,达到动态更新窗口大小的,从而得出长度最小的符合条件的长度。 - 滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置,从而将O(n2)的暴力解法降为O(n)。
- 如果没有接触过这一类的方法,很难想到类似的解题思路,滑动窗口方法还是很巧妙的。
模拟行为
- 模拟类的题目在数组中很常见,不涉及到什么算法,就是单纯的模拟,十分考察大家对代码的掌控能力。
- 相信大家又遇到过这种情况:感觉题目的边界调节超多,一波接着一波的判断,找边界,踩了东墙补西墙,好不容易运行通过了,代码写的十分冗余,毫无章法,其实真正解决题目的代码都是简洁的,或者有原则性的。
-
链表:是一种通过指针串联在一起的线性结构,每一个节点是由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
-
链表的存储方式:链表是通过指针域的指针链接在内存中各个节点,所以链表中的节点在内存中不是连续分布的,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理
-
单链表:每一个节点只有一个指针域,指向节点的下一个节点。
-
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。既可以向前查询也可以向后查询。
-
循环链表:顾名思义,就是链表首尾相连。可以用来解决约瑟夫环问题。
链表节点的定义,很多同学会在面试的时候都写不好。这是因为平时在刷leetcode的时候,链表的节点都默认定义好了,直接用就行了,所以同学们都没有注意到链表的节点是如何定义的。而在面试的时候,一旦要自己手写链表,就写的错漏百出。
这里给出C/C++的定义链表节点方式,如下所示:
// 单链表
struct ListNode {
int val; // 节点存储的元素
ListNode* next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
}通过自己定义构造函数初始化节点:
ListNode *head = new ListNode(5);所以如果不定义构造函数使用默认构造函数的话,在初始化的时候就不能直接给变量赋值!
Java定义链表节点的方式如下图所示:
// java
public class ListNode {
int val;
ListNode next;
// 构造函数
public ListNode() { }
public ListNode(int val) {
this.val = val;
}
public ListNode(int val, ListNode next) {
this.val = val;
this.next = next;
}
}链表的特性和数组的特性进行一个对比,如图所示:
| 插入/删除(时间复杂度) | 查询(时间复杂度) | 适用场景 | |
|---|---|---|---|
| 数组 | O(n) | O(1) | 数据量固定,频繁查询,较少增删 |
| 链表 | O(1) | O(n) | 数据量不固定,频繁增删,较少查询 |
虚拟头节点
- 链表的一大问题就是操作当前节点必须要找前一个节点才能操作。这就造成了,头结点的尴尬,因为头结点没有前一个节点。
- 每次对应头结点的情况都要单独处理,所以使用虚拟头结点的技巧,就可以解决上述问题。
链表的基本操作
- 获取链表第index个节点的数值
- 在链表的最前面插入一个节点
- 在链表的最后面插入一个节点
- 在链表第index个节点前面插入一个节点
- 删除链表的第index个节点的数值
反转链表
- 双指针法:首先定义一个cur指针,指向头结点,再定义一个pre指针,初始化为null。然后就要开始反转了,首先要把cur->next节点用tmp指针保存一下,用来改变cur->next的指向。接下来,就是循环走下去了,直到cur指针指向null。
- 递归法:递归法相对抽象一些,但是其实和双指针法是一样的逻辑,同样是当cur为空的时候循环结束,不断将cur指向pre的过程。双指针法写出来之后,理解如下递归写法就不难了,代码逻辑都是一样的。
环形链表
- fast指针一定先进入环中,如果fast指针和slow指针相遇的话,一定是在环中相遇,这是毋庸置疑的。
- fast和slow都进入环里之后,fast相对于slow来说,fast是一个节点一个节点的靠近slow的,注意是相对运动,所以fast一定可以和slow重合。
- 从头结点出发一个指针,从相遇节点也出发一个指针,这两个指针每次只走一个节点,那么当这两个指针相遇的时候就是环形入口的节点。
-
哈希表(Hashtable):根据关键码的值而直接进行访问的数据结构,一般哈希表都是用来快速判断一个元素是否出现集合里。 例如要查询一个名字是否在这所学校里。要枚举的话时间复杂度是O(n),但如果使用哈希表的话,只需要O(1)就可以做到。我们只需要初始化把这所学校里学生的名字都存在哈希表里,在查询的时候通过索引直接就可以知道这位同学在不在这所学校里了。
-
哈希函数:将哈希表中元素的关键键值映射为元素存储位置的函数。 把学生的姓名直接映射为哈希表上的索引,然后就可以通过查询索引下表快速知道这位同学是否在这所学校里了。
-
哈希碰撞:如果两个输入串的hash函数的值一样,则称这两个串是一个碰撞。一般哈希碰撞有两种解决方法,拉链法和线性探测法。 如果学生的数量大于哈希表的大小怎么办,此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表同一个索引下表的位置。
- 数组
- set(集合)
- map(映射)
在C++语言中,set和map分别提供了以下三种数据结构,其底层实现以及优劣如下表所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(logn) | O(logn) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
std::unordered_set底层实现为哈希表,std::set和std::multiset的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可更改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可以重复 | key不可更改 | O(logn) | O(logn) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可更改 | O(1) | O(1) |
std::unordered_map 底层实现为哈希表,std::map和std::multimap的底层实现是红黑树。同理,std::map和std::multimap的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)。
当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。
那么再来看一下map,在map是一个key,value的数据结构,map中,对key是有限制,对value没有限制的,因为key的存储方式使用红黑树实现的。
数组作为哈希表
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- 很多题目用map确实也可以,但使用map的空间消耗要比数组大一些,因为map要维护红黑树或者符号表,而且还要做哈希函数的运算。所以数组更加简单直接有效!
set作为哈希表
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下表位置,因为要返回x和y的下表,所以set 也不能用。
map作为哈希表
- map是一种<key, value>的结构,可以用key保存数值,用value在保存数值所在的下标。
- 虽然map是万能的,但也要知道什么时候用数组,什么时候用set。
- 二叉树的种类:满二叉树、完全二叉树、二叉搜索树、平衡二叉搜索树
- 二叉树的遍历方式:
- 深度优先遍历
- 前序遍历(递归法、迭代法)
- 中序遍历(递归法、迭代法)
- 后序遍历(递归法、迭代法)
- 广度优先遍历
- 层序遍历(迭代法)
- 深度优先遍历
- 二叉树的定义:
// 二叉树节点 C++
struct TreeNode {
int val; // 节点存储的元素
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
}// 二叉树节点 Java
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() { }
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}1、二叉树的递归遍历(以前序为例)
- **确定递归函数的参数和返回值:**因为要打印出前序遍历节点的数值,所以参数⾥需要传⼊vector在 放节点的数值,除了这⼀点就不需要在处理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
void traversal(TreeNode *cur, vector<int> vec)- **确定终⽌条件:**在递归的过程中,如何算是递归结束了呢,当然是当前遍历的节点是空了,那么本层递归就要要结束了,所以如果当前遍历的这个节点是空,就直接return,代码如下:
if (cur == nullptr) return;- **确定单层递归的逻辑:**前序遍历是中左右的循序,所以在单层递归的逻辑,是要先取中节点的数值,代码如下:
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右- 完整代码:
// C++
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result);
return result;
}
};// Java
class solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
traversal(TreeNode root, List<Integer> result);
return result;
}
private void traversal(TreeNode root, List<Integer> result) {
if (root == null) return null;
result.add(root.val);
traversal(root.left, result);
traversal(root.right, result);
}
}2、二叉树的迭代遍历(利用stack)
递归的实现就是:每⼀次递归调⽤都会把函数的局部变量、参数值和返回地址等压⼊调⽤栈中,然后递归返回的时候,从栈顶弹出上⼀次递归的各项参数,所以这就是递归为什么可以返回上⼀层位置的原因。
- 前序迭代遍历(中左右) 前序遍历是中左右,每次先处理的是中间节点,那么先将跟节点放⼊栈中,然后将右孩⼦加⼊栈,再加⼊左孩⼦。为什么要先加⼊右孩⼦,再加⼊左孩⼦呢?因为这样出栈的时候才是中左右的顺序。
// C++
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
st.pop();
result.push_back(node->val); // 中
if (node->right) st.push(node->right); // 右(空节点不⼊栈)
if (node->left) st.push(node->left); // 左(空节点不⼊栈)
}
return result;
}
};// Java
class Solution {
public List<Integer> preordertraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
Stack<TreeNode> st = new Stack<>();
if (root == null) return result;
st.push(root);
while (!st.isEmpty()) {
TreeNode node = st.pop();
result.add(node.val); // 中
if (node.right != null) st.push(node.right); // 右
if (node.left != null) st.push(node.left); // 左
}
return result;
}
}- 中序迭代遍历(左中右) 访问的元素和要处理的元素顺序是不⼀致的,那么在使⽤迭代法写中序遍历,就需要借⽤指针的遍历来帮助访问节点,栈则⽤来处理节点上的元素。
// C++
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
TreeNode* cur = root;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top(); // 从栈⾥弹出的数据,就是要处理的数据(放进result数组⾥的数据)
st.pop();
result.push_back(cur->val); // 中
cur = cur->right; // 右
}
}
return result;
}
};// Java
class Solution {
public List<Integer> inorderTraversal(TreeNode node) {
List<Integer> result = new ArrayList<>();
Stack<TreeNode> st = new Stack<>();
TreeNode cur = root;
while (cur != null || !st.isEmpty()) {
if (cur != null) {
st.push(cur);
cur = cur.left; // 左
} else {
cur = st.pop();
result.add(cur.val); // 中
cur = cur.right; // 右
}
}
return result;
}
}- 后序迭代遍历(左右中)

所以后序遍历只需要前序遍历的代码稍作修改就可以了,代码如下:
// C++
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top(); // 中
st.pop();
result.push_back(node->val);
if (node->left) st.push(node->left); // 左
if (node->right) st.push(node->right); // 右
}
reverse(result.begin(), result.end()); // 中右左->左中右
return result;
}
};// Java
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
Stack<Integer> st = new Stack<>();
if (root == null) return result;
while (!st.isEmpty()) {
TreeNode node = st.pop(); // 中
result.add(node.val);
if (node.left != null) st.push(node.left); // 左
if (node.right != null) st.push(node.right); // 右
}
Collections.reverse(result);
return result;
}
}- 二叉树的统一迭代法(以中序为例)
那我们就将访问的节点放⼊栈中,把要处理的节点也放⼊栈中但是要做标记。如何标记呢,就是要处理的节点放⼊栈之后,紧接着放⼊⼀个空指针作为标记。这种⽅法也可以叫做标记法。
// C++
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
if (root != NULL) st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop(); // 将该节点弹出,避免重复操作,下⾯再将右中左节点添加到栈中
if (node->right) st.push(node->right); // 右
st.push(node); // 中
st.push(NULL); // 中节点访问过,但是还没有处理,加⼊空节点做为标记。
if (node->left) st.push(node->left); // 左
} else { // 只有遇到空节点的时候,才将下⼀个节点放进结果集
st.pop(); // 将空节点弹出
node = st.top(); // 重新取出栈中元素
st.pop();
result.push_back(node->val); // 加⼊到结果集
}
}
return result;
}
};3、二叉树的层序遍历
⼆叉树层序遍历的模板如下所示:
// C++
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
queue<TreeNode*> que;
if (root != NULL) que.push(root);
vector<vector<int>> result;
while (!que.empty()) {
int size = que.size();
vector<int> vec; // 使⽤固定⼤⼩size,不要使⽤que.size(),因为que.size是不断变化的
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
vec.push_back(node->val);
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
result.push_back(vec);
}
return result;
}
};// Java
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
Queue<TreeNode> que = new LinkedList<>();
if (root != null) que.offer(root);
while (!que.isEmpty()) {
int size = que.size();
List<Integer> levelList = new ArrayList<>();
for (int i = 0; i < size; i++) {
TreeNode node = que.poll();
levelList.add(node.val);
if (node.left != null) que.offer(node.left);
if (node.right != null) que.offer(node.right);
}
result.add(new ArrayList<>(levelList));
}
return result;
}
}4、总结
二叉树递归遍历、迭代遍历和层序遍历是二叉树题目的基础,一定要重点掌握!!!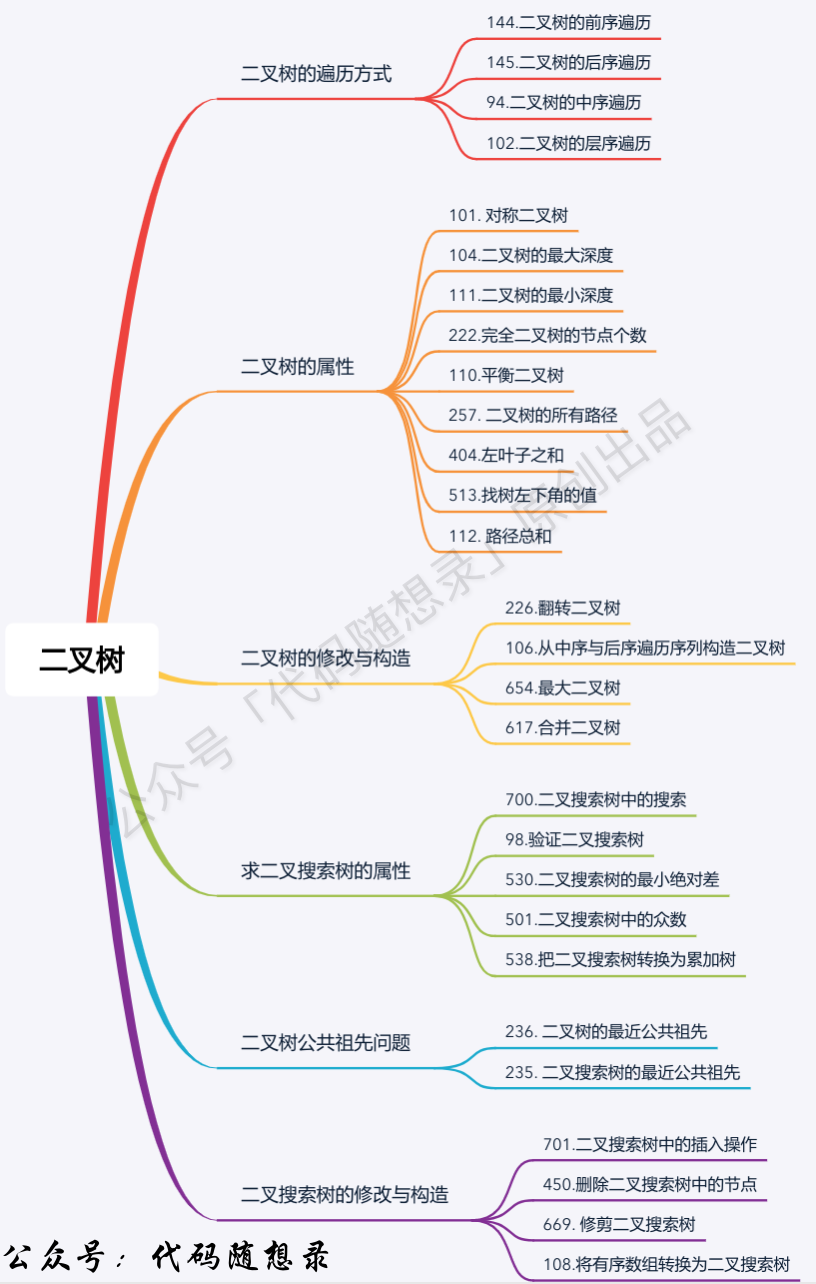
- 确定入口参数
- 确定终止条件
- 单层递归逻辑
回溯法一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成的树的深度。如图:
大家可以从图中看出for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。分析完过程,回溯算法模板框架如下:
priavte void backTracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backTracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}例如,求组合的实际的java代码为:
class Solution {
List<List<Integer>> result = new ArrayList<>();
LinkedList<Integer> path = new LinkedList<>();
public List<List<Integer>> combine(int n, int k) {
backTracking(n, k, 1);
return result;
}
/**
* 每次从集合中选取元素,可选择的范围随着选择的进行而收缩,调整可选择的范围,就是要靠startIndex
* @param startIndex 用来记录本层递归的中,集合从哪里开始遍历(集合就是[1,...,n] )。
*/
private void backTracking(int n, int k, int startIndex){ // 1 入口参数
// 2 终止条件
if (path.size() == k){
result.add(new ArrayList<>(path));
return;
}
// 3 单层递归逻辑
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++){ // 这里隐藏着剪枝
path.add(i);
backTracking(n, k, i + 1);
path.removeLast();
}
}
}- 将问题分解为若干个子问题
- 找出适合的贪心策略
- 求解每一个子问题的最优解
- 将局部最优解堆叠成全局最优解
- 确定dp数组(dp table)以及下标的含义
- dp数组如何初始化
- 确定递推公式
- 确定遍历顺序
- 举例推导dp数组
- 基本动态规划
top-down最大的缺点是:为了计算某个长度的solution,会计算两个subsolution。 但是,subsolution会被重复计算很多次。比如说,当len=7时,会计算len=3和len=4;当len=8时,会计算len=3和len=5,这样len=3被计算了两次。 如果我们每碰到一个新的subsolution就记录下来,之后直接用即可,这样就可以节省很多的计算。这就是动态规划的核心思想。
// CUT-ROD(p, n)
if n == 0
return 0
q = - ∞
for i = 1 to n
q = max(q, p[i] + CUT-ROD(p, n - i))
retrun q- 01背包
有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。
二维dp数组01背包
1.先遍历物品,再遍历背包重量 (此方法更加便于理解)
// weight数组的大小 就是物品个数
for (int i = 0; i < weight.length; i++) { // 遍历物品
for (int j = 0; j <= bagWeight; j++) { // 遍历背包容量
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = Math.max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}2.先遍历背包,再遍历物品
// weight数组的大小 就是物品个数
for (int j = 0; j <= bagWeight; j++) { // 遍历背包容量
for (int i = 1; i < weight.length; i++) { // 遍历物品
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}一维dp数组01背包
倒序遍历是为了保证物品i只被放入一次!
for (int i = 0; i < weight.length; i++) { // 遍历物品
for (int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}- 完全背包
有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i]。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。
完全背包和01背包问题唯一不同的地方就是,每种物品有无限件。
我们知道01背包内嵌的循环是从大到小遍历,为了保证每个物品仅被添加一次。而完全背包的物品是可以添加多次的,所以要从小到大去遍历,即:
// 先遍历物品,再遍历背包
for (int i = 0; i < weight.length; i++) { // 遍历物品
for (int j = weight[i]; j <= bagWeight ; j++) { // 遍历背包容量
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}-
多重背包
-
背包问题大总结