Banyaknya jumlah informasi yang tersedia di internet saat ini. Banyak orang yang memiliki akses ke internet dan mencari informasi yang relevan dan terpercaya. Namun, dengan banyaknya informasi yang tersedia, seringkali menimbulkan kesulitan bagi pengguna untuk menemukan artikel yang sesuai dengan kebutuhan mereka.Terkadang, pengguna harus menelusuri berbagai sumber dan membaca banyak artikel sebelum menemukan yang mereka butuhkan. Ini dapat menjadi proses yang memakan waktu dan membosankan. Oleh karena itu, diperlukan sistem yang mampu membantu pengguna dalam menemukan artikel yang sesuai dengan kebutuhan mereka dengan cepat dan efisien.
Sebagai agregator, portal berita online menghadapi tantangan besar dalam memilih secara cermat kumpulan artikel yang akan ditampilkan kepada para penggunanya. Biasanya, artikel artikel kandidat tersebut direkomendasikan secara manual oleh editor platform dari kumpulan artikel yang jauh lebih besar yang dikumpulkan dari berbagai sumber. Proses pemilihan manual seperti itu membutuhkan banyak tenaga dan waktu.
Sistem recomendasi artikel memainkan peran penting dalam membantu pengguna menemukan artikel yang relevan dan terpercaya. Sistem ini menggunakan algoritma untuk menganalisis data seperti preferensi pengguna, tipe artikel yang dicari, dan interaksi sebelumnya dengan artikel lain. Berdasarkan analisis ini, sistem memberikan rekomendasi artikel yang sesuai dengan kebutuhan pengguna. Ini dapat membantu pengguna menemukan informasi yang mereka cari dengan lebih cepat dan mudah.
Bagaimana cara membuat sistem rekomendasi artikel yang dapat meningkatkan tingkat interaksi dan engagement pengguna dengan konten yang diterima?
Menjelaskan pernyataan masalah latar belakang:
- Kurangnya aksesibilitas terhadap artikel yang relevan bagi pengguna, sehingga membuat mereka kesulitan menemukan artikel yang sesuai dengan kebutuhan dan minat mereka.
- Artikel yang dibagikan seringkali tidak relevan dengan minat dan kebutuhan pengguna, sehingga membuat mereka tidak tertarik untuk membacanya.
- Terlalu banyak artikel yang tersedia, sehingga membuat pengguna kesulitan menemukan artikel yang sesuai dengan kebutuhan dan minat mereka.
- Sistem rekomendasi artikel yang tidak memperhitungkan perkembangan dan perubahan minat dan kebutuhan pengguna secara berkala.
Menjelaskan tujuan dari pernyataan masalah:
- Mengidentifikasi kebutuhan dan preferensi pembaca terhadap artikel yang akan mereka baca.
- Meningkatkan tingkat interaksi dan engagemen pembaca dengan artikel yang mereka baca.
- Memperbaiki relevansi dan keakuratan rekomendasi artikel.
- Meningkatkan brand awareness dan meningkatkan loyalitas pembaca.
- Menciptakan pengalaman yang lebih baik bagi pembaca dengan memberikan artikel yang sesuai dengan kebutuhan dan preferensi mereka
Solusi pada rekomendasi artikel akan menggunakan 2 model yaitu:
-
Content-based filtering adalah teknik rekomendasi yang berdasarkan pada karakteristik item yang direkomendasikan. Dalam artikel rekomendasi, content-based filtering dapat digunakan dengan menentukan fitur artikel seperti judul, deskripsi, kategori, tag, dll. Kemudian, algoritma menentukan artikel yang sesuai dengan preferensi pengguna berdasarkan bagaimana fitur artikel tersebut cocok dengan preferensi pengguna sebelumnya. Misalnya, jika seorang pengguna sering membaca artikel tentang teknologi, algoritma akan merekomendasikan artikel-artikel terbaru tentang teknologi yang sesuai dengan preferensi pengguna tersebut.
-
Collaborative filtering adalah teknik rekomendasi yang berdasarkan pada interaksi pengguna dengan item-item tertentu. Teknik ini membuat rekomendasi berdasarkan pengalaman pengguna lain yang mirip dengan preferensi pengguna saat ini. Dalam artikel rekomendasi, collaborative filtering dapat digunakan untuk menentukan artikel yang mungkin akan disukai oleh pengguna berdasarkan pada bagaimana pengguna lain dengan preferensi yang sama memberikan nilai pada artikel tertentu.
Dataset yang digunakan pada laporan ini berisi informasi tentang aktivitas pengguna dalam berbagi dan membaca artikel. Data ini diambil dari Deskdrop, sebuah platform internal untuk berbagi artikel bagi tim CI&T. Dataset ini berisi informasi tentang pengguna, artikel yang dibagikan dan dibaca, dan waktu aktivitas. Ini dapat digunakan untuk membuat sistem rekomendasi artikel yang memberikan rekomendasi artikel berdasarkan preferensi pengguna dan perilaku sebelumnya.Dataset ini terdiri dari dua file csv yaitu Shared_articles dan Users_interactions Kaggle Repository
Variabel-variabel pada Articles sharing and reading from CI&T DeskDrop Kaggle Dataset adalah sebagai berikut:
- "timestamp" memuat waktu pada saat suatu event terjadi, dan format UNIX timestamp digunakan untuk merepresentasikannya.
- "EventType" adalah variabel yang mencatat jenis aktivitas yang terjadi dalam sistem ada dua jenis aktivitas yang tercatat, yaitu "CONTENT SHARED" dan "CONTENT REMOVED".
- "contentId" adalah identifikasi unik untuk suatu konten, seperti ID artikel.
- "authorPersonId" adalah identifikasi unik untuk penulis suatu konten.
- "authorSessionId" adalah identifikasi unik untuk sesi penulis pada saat event terjadi.
- "authorUserAgent" adalah informasi mengenai perangkat atau browser yang digunakan oleh penulis saat event terjadi.
- "authorRegion" adalah informasi mengenai wilayah geografis penulis.
- "authorCountry" adalah informasi mengenai negara tempat tinggal penulis.
- "contentType" menjelaskan jenis konten, seperti HTML, VIDEO, dan RICH.
- "url" adalah URL untuk konten.
- "title" adalah judul konten.
- "text" adalah teks dari konten.
- "lan" adalah informasi mengenai bahasa konten.
- "timestamp" memuat waktu pada saat suatu event terjadi, dan format UNIX timestamp digunakan untuk merepresentasikannya.
- "eventType" adalah variabel yang mencatat jenis aktivitas yang terjadi dalam sistem ada beberapa jenis aktivitas seperti VIEW, LIKE, COMMENT CREATED, DLL
- "contentId" adalah identifikasi unik untuk suatu konten, seperti ID artikel.
- "personId" merupakan identitas unik dari setiap pengguna. Variabel ini digunakan untuk mengidentifikasi setiap pengguna secara individual.
- "sessionId" adalah identitas unik dari sesi aktivitas pengguna. Variabel ini digunakan untuk mengidentifikasi interaksi pengguna yang terkait dengan sesi tertentu.
- "userAgent" menyimpan informasi tentang perangkat dan browser yang digunakan oleh pengguna saat melakukan interaksi. Informasi ini dapat berisi nama perangkat, sistem operasi, versi browser, dll.
- "userRegion" menyimpan informasi tentang wilayah geografis dari pengguna. Ini dapat berisi informasi tentang negara atau provinsi dimana pengguna berada.
- "userCountry" menyimpan informasi tentang negara dari pengguna. Ini digunakan untuk mengidentifikasi negara asal pengguna dan dapat digunakan untuk analisis demografis.
- Jumlah baris: 3122
- Jumlah kolom : 13
- Info dataset:
| NO | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 1 | timestamp | 3122 non-null | int64 |
| 2 | eventType | 3122 non-null | object |
| 3 | contentId | 3122 non-null | int64 |
| 4 | authorPersonId | 3122 non-null | int64 |
| 5 | authorSessionId | 3122 non-null | int64 |
| 6 | authorUserAgent | 680 non-null | object |
| 7 | authorRegion | 680 non-null | object |
| 8 | authorCountry | 680 non-null | object |
| 9 | contentType | 3122 non-null | object |
| 10 | url | 3122 non-null | object |
| 11 | title | 3122 non-null | object |
| 12 | text | 3122 non-null | object |
| 13 | lang | 3122 non-null | object |
Tabel 1. Info detail tiap kolom Shared_articles
Pada tabel 1 terdiri atas 13 kolom dan tipe datanya terdiri atas 9 object dan 5 int64
- Jumlah baris: 72312
- Jumlah kolom : 8
- Info dataset:
| NO | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 1 | timestamp | 72312 non-null | int64 |
| 2 | eventType | 72312 non-null | object |
| 3 | contentId | 72312 non-null | int64 |
| 4 | personId | 72312 non-null | int64 |
| 5 | sessionId | 72312 non-null | int64 |
| 6 | userAgent | 56918 non-null | object |
| 7 | userRegion | 56907 non-null | object |
| 8 | userCountry | 56918 non-null | object |
Tabel 2. Info detail tiap kolom Users_interactions
Pada tabel 2 terdiri atas 8 kolom dan tipe datanya terdiri atas 4 object dan 4 int64
Teknik yang digunakan pada notebook secara berurutan :
- Handling eventType "user_interaction"
Terdapat 5 jenis interaksi, selanjutnya adalah dengan memberikan bobot tergantung pada jenis interaksinya Memmbuat dictionary untuk menampung masing-masing bobot eventType:
-
'COMMENT CREATED': 5
-
'FOLLOW': 4
-
'BOOKMARK': 3
-
'LIKE': 2
-
'VIEW': 1
-
Handling User cold-star
User cold-start adalah masalah yang sering dialami oleh sistem rekomendasi, di mana sulit untuk memberikan rekomendasi yang dipersonalisasi untuk pengguna yang tidak memiliki atau hanya memiliki sedikit item yang dikonsumsi. Hal ini disebabkan karena kurangnya informasi untuk memodelkan preferensi mereka. Untuk mengatasi masalah ini, dataset hanya mempertahankan pengguna dengan setidaknya 7 interaksi, karena dengan begitu lebih banyak informasi tersedia untuk memodelkan preferensi pengguna dan memberikan rekomendasi yang lebih baik.
- Smooth_user_preference
Agar distribusi interaksi antara pengguna dan item tidak terlalu ekstrem atau tidak terlalu bias, maka dilakukan transformasi logaritma dengan mengaplikasikan fungsi "smooth_user_preference". Transformasi ini bertujuan untuk memperhalus distribusi interaksi dan membuatnya lebih stabil sehingga lebih mudah dianalisis dan diterapkan pada sistem rekomendasi.
- Split data
Data training digunakan untuk melatih model, sedangkan data testing digunakan untuk mengevaluasi model yang sudah dilatih. Data set interactions_full_df akan dibagi menjadi interactions_train sebesar 80% dan interactions_test sebesar 20%. Stratify=interactions_full_df['personId'] mengatakan bahwa pembagian data harus dilakukan dengan proporsi yang sama dari setiap kelas dalam kolom "personId".Test_size=0.20 mengatakan bahwa 20% dari data set akan digunakan sebagai data testing.Random_state=42 adalah seed yang digunakan oleh fungsi random untuk memastikan bahwa hasil yang diperoleh selalu sama setiap kali dilakukan pembagian data.
- Content Based Filtering
Kelebihan content-based filtering:
- Personalisasi: Algoritme ini dapat memberikan rekomendasi berdasarkan preferensi pengguna, sehingga memberikan hasil yang lebih sesuai dengan kebutuhan dan minat mereka.
- Mudah dipahami: Content-based filtering menggunakan deskripsi konten dari item seperti genre, deskripsi, dan tag, sehingga mudah dipahami dan diterapkan.
- Ketergantungan pada data: Algoritme ini tidak terlalu bergantung pada data dari pengguna lain, sehingga hasil rekomendasi bisa tetap stabil meski tidak ada banyak data interaksi pengguna.
Kekurangan content-based filtering:
- Bias terhadap item yang dikenal: Algoritme ini akan memberikan rekomendasi yang lebih baik pada item yang sering dikenal oleh pengguna, sehingga item baru dan unik mungkin tidak terdeteksi.
- Terbatas pada preferensi saat ini: Content-based filtering hanya mempertimbangkan preferensi saat ini dari pengguna, sehingga bisa terbatas pada item yang sesuai dengan preferensi saat ini saja.
- Kurangnya rekomendasi baru: Karena fokus pada preferensi saat ini, rekomendasi yang diberikan mungkin terbatas dan kurang bervariasi.
Implementasi dari model content-based filtering untuk sistem rekomendasi artikel dilakukan dengan membuat Class ContentBasedRecommender memiliki beberapa method yang membantu mengimplementasikan model ini. Method get_model_name mengembalikan nama model yang digunakan. Method _get_similar_items_to_user_profile menghitung kemiripan antara profil pengguna dengan semua profil item menggunakan cosine similarity. Method recommend_items menyarankan item yang paling mirip dengan profil pengguna. Recommendations_df adalah dataframe yang menyimpan rekomendasi item yang diterima dari method _get_similar_items_to_user_profile.
- Colaboratative Filtering
Kelebihan Collaborative Filtering:
- Collaborative Filtering memiliki tingkat akurasi yang tinggi karena menggunakan data interaksi sebelumnya dari banyak pengguna untuk membuat rekomendasi.
- Collaborative Filtering bekerja dengan baik pada kasus dengan banyak data interaksi pengguna.
- Dapat membuat rekomendasi individual yang lebih tepat karena mempertimbangkan preferensi spesifik pengguna.
Kekurangan Collaborative Filtering:
- Ketergantungan pada data interaksi pengguna. Jika tidak ada interaksi pengguna yang cukup, Collaborative Filtering tidak akan bekerja dengan baik.
- Kecenderungan untuk mengikuti tren populer daripada menemukan item unik dan menarik.
- Kecenderungan untuk membuat rekomendasi yang mirip dengan yang sudah dikenal oleh pengguna.
- Kecenderungan untuk membuat rekomendasi yang sesuai dengan mayoritas pengguna dan mengabaikan preferensi individu.
- Bias terhadap item yang paling sering direkomendasikan karena lebih banyak data interaksi untuk item tersebut.
Implementasi dari collaborative filtering (CF) recommendation model. Dalam class CFRecommender, ada dua atribut yaitu cf_predictions_df dan items_df yang diambil dari inputan saat inisiasi. Kemudian, ada method recommend_items yang akan meng-return rekomendasi item bagi suatu user. Prosesnya adalah dengan mengambil data dari cf_predictions_df berdasarkan user_id dan mengurutkan nilai prediksi (recStrength) dari tertinggi ke terendah. Lalu, data dalam rekomendasi akan di-filter dengan menghilangkan item yang diinginkan untuk dihindari. Terakhir, jika verbose bernilai True, maka akan diteruskan informasi detail dari item seperti judul dan URL.
| recStrength | contentId | title | url | lang |
|---|---|---|---|---|
| 0.693135 | 5250363310227021277 | How Google is Remaking Itself as a "Machine Le... | https://backchannel.com/how-google-is-remaking... | en |
| 0.689209 | -7126520323752764957 | How Google is Remaking Itself as a "Machine Le... | https://backchannel.com/how-google-is-remaking... | en |
| 0.617085 | 638282658987724754 | Machine Learning for Designers | https://www.oreilly.com/learning/machine-learn... | en |
| 0.583306 | 5258604889412591249 | Machine Learning Is No Longer Just for Experts | https://hbr.org/2016/10/machine-learning-is-no... | en |
| 0.579381 | -8068727428160395745 | How real businesses are using machine learning | https://techcrunch.com/2016/03/19/how-real-bus... | en |
| 0.567638 | 2220561310072186802 | 5 Skills You Need to Become a Machine Learning... | http://blog.udacity.com/2016/04/5-skills-you-n... | en |
| 0.556181 | -229081393244987789 | Building AI Is Hard-So Facebook Is Building AI... | http://www.wired.com/2016/05/facebook-trying-c... | en |
| 0.551451 | -4571929941432664145 | Machine Learning as a Service: How Data Scienc... | http://www.huffingtonpost.com/laura-dambrosio/... | en |
| 0.550014 | -9033211547111606164 | Google's Cloud Machine Learning service is now... | https://techcrunch.com/2016/09/29/googles-clou... | en |
| 0.546016 | 54678605145828343 | Is machine learning the next commodity? | http://readwrite.com/2016/04/18/machine-learni... | en |
Tabel 3. Top 10 recomendation Artikel by Content Based Filtering
Pada tabel 3 menampilkan top 10 rekomendasi artikel dari salah satu user dimana rekomendasinya seputar algoritma Machine Learning dengan model Content Based Filtering
| recStrength | contentId | title | url | lang |
|---|---|---|---|---|
| 0.315666 | -8190931845319543363 | Machine Learning Is At The Very Peak Of Its Hy... | https://arc.applause.com/2016/08/17/gartner-hy... | en |
| 0.309676 | 2468005329717107277 | How Netflix does A/B Testing - uxdesign.cc - U... | https://uxdesign.cc/how-netflix-does-a-b-testi... | en |
| 0.300454 | 7507067965574797372 | Um bilhão de arquivos mostram quem vence a dis... | http://gizmodo.uol.com.br/disputa-tabs-vs-espa... | pt |
| 0.300092 | -6467708104873171151 | 5 reasons your employees aren't sharing their ... | http://justcuriousblog.com/2016/04/5-reasons-y... | en |
| 0.294277 | 4118743389464105405 | Why Google App Engine rocks: A Google engineer... | https://cloudplatform.googleblog.com/2016/04/w... | en |
| 0.292926 | 2589533162305407436 | 6 reasons why I like KeystoneML | http://radar.oreilly.com/2015/07/6-reasons-why... | en |
| 0.291189 | 7395435905985567130 | The AI business landscape | https://www.oreilly.com/ideas/the-ai-business-... | en |
| 0.289656 | -9033211547111606164 | Google's Cloud Machine Learning service is now... | https://techcrunch.com/2016/09/29/googles-clou... | en |
| 0.289142 | 5258604889412591249 | Machine Learning Is No Longer Just for Experts | https://hbr.org/2016/10/machine-learning-is-no... | en |
| 0.287894 | -5756697018315640725 | Being A Developer After 40 - Free Code Camp | https://medium.freecodecamp.com/being-a-develo... | en |
Tabel 4. Top 10 recomendation Artikel by Colaborative Filtering
Pada tabel 4 menampilkan top 10 rekomendasi artikel dari salah satu user dimana rekomendasinya seputar algoritma Machine Learning dengan model Colaborative Filtering
Pada tahap evaluasi digunakan Top-N accuracy metrics yang digunakan yaitu:
Top-N accuracy metrics adalah metrik yang digunakan untuk mengukur akurasi dalam rekomendasi artikel. Ini mengukur seberapa baik sistem rekomendasi dalam memprediksi item yang akan disukai oleh pengguna. Top-N accuracy mengacu pada presentasi item yang direkomendasikan dan benar-benar diterima oleh pengguna dalam daftar rekomendasi N teratas. Misalnya, jika sistem memrekomendasikan 10 artikel dan 5 dari mereka benar-benar diterima oleh pengguna, maka Top-5 accuracy-nya adalah 50%. Semakin tinggi nilai Top-N accuracy, semakin baik kinerja sistem rekomendasi.
Selanjutnya adalah Melakukan index dengan kolom personId. Tujuannya adalah untuk mempercepat pencarian saat melakukan evaluasi. Setelah di-index, kolom personId menjadi indeks dalam data frame dan memungkinkan pencarian yang lebih cepat terhadap baris tertentu dalam data frame berdasarkan nilai dari personId.
Implementasi dari Top-N accuracy metrics untuk melakukan evaluasi pada sebuah model rekomendasi artikel dengan menerapkan class ModelEvaluator digunakan untuk melakukan evaluasi pada model. Fungsi get_not_interacted_items_sample digunakan untuk mengambil sample dari item yang belum pernah diterima oleh pengguna sebanyak EVAL_RANDOM_SAMPLE_NON_INTERACTED_ITEMS (100 item). Fungsi _verify_hit_top_n digunakan untuk memastikan apakah item yang diterima pengguna berada dalam daftar rekomendasi Top-N. Fungsi evaluate_model_for_user digunakan untuk mengevaluasi model untuk seorang pengguna tertentu. Dalam fungsi ini, model di-rekomendasikan untuk membuat daftar rekomendasi untuk pengguna tertentu, dan kemudian di-filter untuk hanya menyertakan item yang diterima pengguna dan item acak yang belum diterima. Kemudian, dengan menggunakan _verify_hit_top_n, diperiksa apakah item yang diterima pengguna berada dalam daftar rekomendasi Top-N. Jika ya, hit_count ditingkatkan dan pemrosesan berlanjut ke item berikutnya. Setelah seluruh item diterima pengguna diterima, hit_count akan digunakan untuk menghitung Top-N accuracy.
Output pada global_metrics:
- "count_hits_at_7" adalah jumlah item yang direkomendasikan dan diterima oleh pengguna sebanyak 7 item.
- "count_hits_at_15" adalah jumlah item yang direkomendasikan dan diterima oleh pengguna sebanyak 15 item.
- "interacted_count" adalah jumlah item yang benar-benar diterima oleh pengguna.
- "recall_at_7" adalah rasio antara "recall_at_7" dan "interacted_count", yang menunjukkan seberapa baik sistem direkomendasikan item yang sebenarnya diterima oleh pengguna.
- "recall_at_15" adalah rasio antara "recall_at_15" dan "interacted_count", yang menunjukkan seberapa baik sistem direkomendasikan item yang sebenarnya diterima oleh pengguna.
| Index | count_hits_at_7 | count_hits_at_15 | interacted_count | recall_at_7 | recall_at_15 | person_id |
|---|---|---|---|---|---|---|
| 55 | 32 | 53 | 192 | 0.166667 | 0.276042 | 3609194402293569455 |
| 63 | 41 | 54 | 134 | 0.305970 | 0.402985 | -2626634673110551643 |
| 16 | 18 | 37 | 130 | 0.138462 | 0.284615 | -1032019229384696495 |
Tabel 5. global_metric Content Based Filtering
Pada tabel 5 di tampilkan beberapa sampel untuk membandingkan atribut- atribut dari global metric terhadap user dengan menggunakan model Content Based Filtering
| Index | count_hits_at_7 | count_hits_at_15 | interacted_count | recall_at_7 | recall_at_15 | person_id |
|---|---|---|---|---|---|---|
| 55 | 22 | 39 | 192 | 0.114583 | 0.203125 | 3609194402293569455 |
| 63 | 16 | 35 | 134 | 0.119403 | 0.261194 | -2626634673110551643 |
| 16 | 23 | 41 | 130 | 0.176923 | 0.315385 | -1032019229384696495 |
Tabel 6. global_metric Colaborative Filtering
Pada tabel 6 dengan menggunakan model Colaborative Filtering di tampilkan beberapa sampel untuk membandingkan atribut - atribut dari global metric terhadap user
| modelName | recall_at_7 | recall_at_15 |
|---|---|---|
| Content-Based | 0.215506 | 0.345072 |
| Collaborative Filtering | 0.397766 | 0.551248 |
Tabel 7. Perbandingan 2 model
Pada tabel 7 berdasarkan hasil perbandingan tersebut model Content Based Filtering menghasilkan recall yang lebih rendah pada recall_at_7 dan recall_at_15
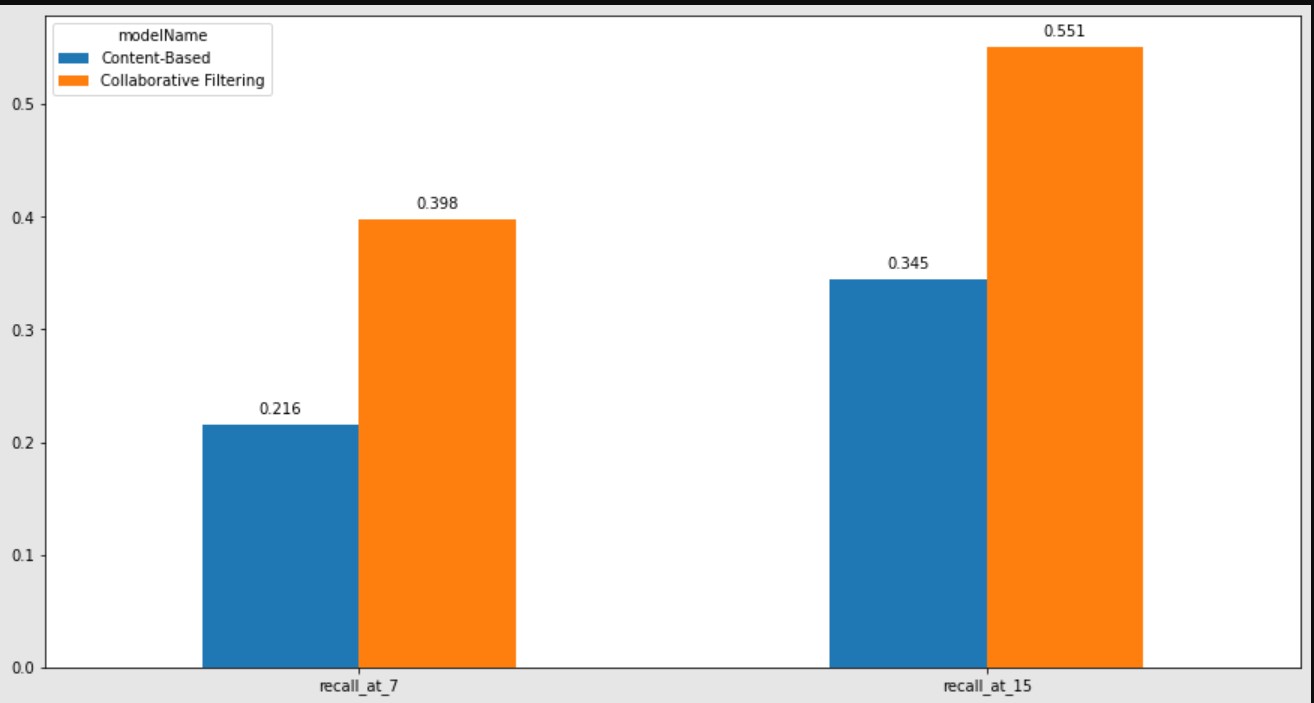
Gambar 1. Plot Recall Content Based Filtering dan Colaborative Filtering
Pada gambar tersebut terlihat plot hasil recall pada kedua model dan dapat diketahui bahwa Colaborative Filtering memiliki score recall_at_7 dan recall_at_15 lebih tinggi dibandingkan model Content Based Filtering
Sehingga dapat disimpulkan pada article recomendation ini model Colaborative Filtering lebih baik dari model Content Based Filtering melalui evaluasi Top-N accuracy metrics dengan membandingkan hasil recall kedua model tersebut.
Referensi: Wang, Xuejian, et al. "Dynamic attention deep model for article recommendation by learning human editors' demonstration." Proceedings of the 23rd acm sigkdd international conference on knowledge discovery and data mining. 2017.
---Ini adalah bagian akhir laporan---