# 1、Modified librosa with log mel scale
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=n_mels, fmin=fmin,
fmax=fmax, hop_length=hop_length)
mfcc_lib_log = librosa.feature.mfcc(S=np.log(S+1e-6), n_mfcc=n_mfcc, htk=False,hop_length=hop_length,win_length=win_length)
# 2、Default librosa with db mel scale
mfcc_lib_db = librosa.feature.mfcc(y=y, sr=sr, n_fft=n_fft,
n_mfcc=n_mfcc, n_mels=n_mels,
hop_length=hop_length,
fmin=fmin, fmax=fmax, htk=False)
# 3、Python_speech_features
mfcc_speech = python_speech_features.mfcc(signal=y, samplerate=sr, winlen=win_length / sr, winstep=hop_length / sr,
numcep=n_mfcc, nfilt=n_mels, nfft=n_fft, lowfreq=fmin, highfreq=sr//2,
preemph=0.0, ceplifter=0, appendEnergy=False, winfunc=hann)
# 4、Torchaudio 'textbook' log mel scale
mfcc_torch_log = torchaudio.transforms.MFCC(sample_rate=sr, n_mfcc=n_mfcc,
dct_type=2, norm='ortho', log_mels=True,
melkwargs=melkwargs)(torch.from_numpy(y))
# 5、Torchaudio 'librosa compatible' default dB mel scale
mfcc_torch_db = torchaudio.transforms.MFCC(sample_rate=sr, n_mfcc=n_mfcc,
dct_type=2, norm='ortho', log_mels=False,
melkwargs=melkwargs)(torch.from_numpy(y))
# 6、mfcc c++ implement (log mfcc)
data = []
with open('data.txt', 'r') as file:
for line in file:
# 使用 np.fromstring 将每行的字符串转换为浮点数数组
# sep=', ' 指定了分隔符为逗号和一个空格
data.append(np.fromstring(line, sep=', ', dtype=float))
# 将列表转换为 numpy 数组
data_array = np.array(data)1、打印所有算法库的实现结果:
print(mfcc_lib_log.T.shape)
print(mfcc_torch_db.T.shape)
print(mfcc_speech.shape)
print(mfcc_torch_log.T.shape)
print(mfcc_lib_db.T.shape)
print(data_array.shape)#c++ implement(73, 13) torch.Size([73, 13]) (71, 13) torch.Size([73, 13]) (73, 13) (70, 14)
2、可视化对比
plt.subplot(2, 1, 1)
# 绘制不同的MFCC数据集,使用不同的颜色和图例
plt.subplot(2, 1, 1) # 2行1列的第一个子图
plt.plot(mfcc_lib_log.T[3:, feature], 'k', label='Black - Lib Log') # 黑色
plt.plot(mfcc_torch_db.T[:, feature], 'b', label='Blue - Torch DB') # 蓝色
plt.plot(mfcc_speech[1:, feature], 'r', label='Red - Speech') # 红色
plt.plot(mfcc_torch_log.T[3:, feature], 'c', label='Cyan - Torch Log') # 青色
plt.plot(data_array[:, feature], 'g', label='Green - C++ Imp') # 绿色
plt.plot(mfcc_lib_db.T[:, feature], 'y', label='Yellow - Lib DB') # 黄色
plt.legend()
plt.grid()
plt.subplot(2, 2, 3)
plt.plot(mfcc_lib_log.T[:,feature], 'k')
plt.plot(mfcc_torch_log.T[:,feature], 'c')
plt.plot(mfcc_speech[:,feature], 'r')
plt.plot(data_array[:,feature], 'g')
plt.grid()
plt.subplot(2, 2, 4)
plt.plot(mfcc_torch_db.T[:,feature], 'b')
plt.plot(mfcc_lib_db.T[:,feature], 'y')
plt.grid()
plt.show()特征一:
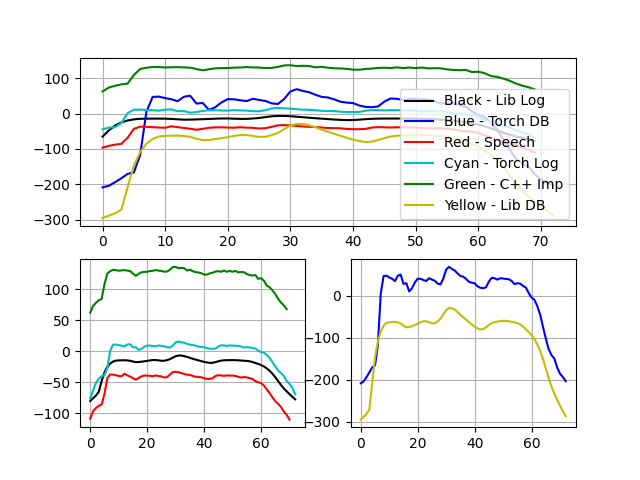
特征二:
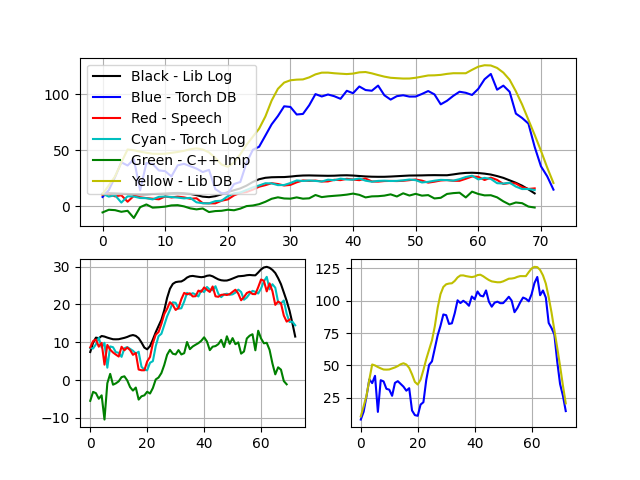
特征三:
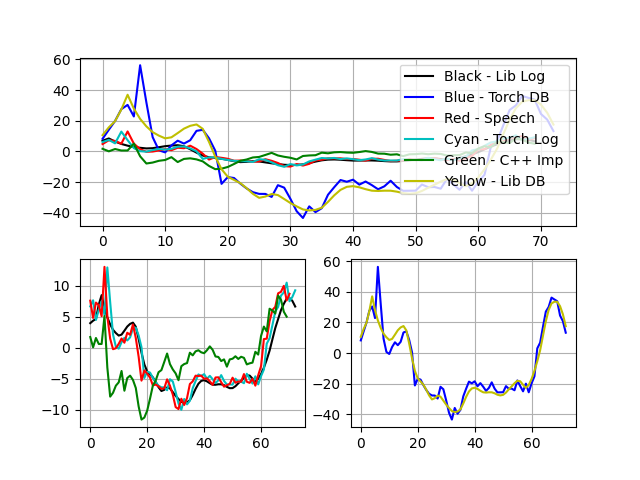
特征四:
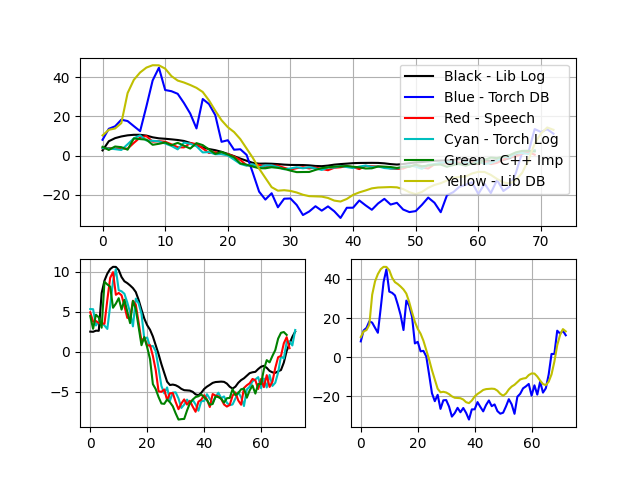
特征五:
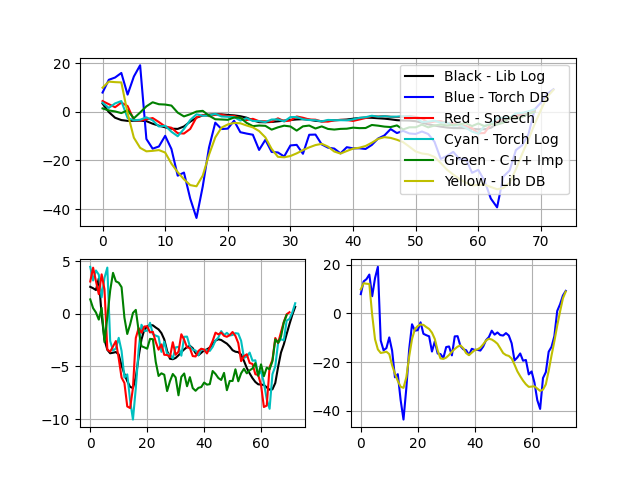
特征六:
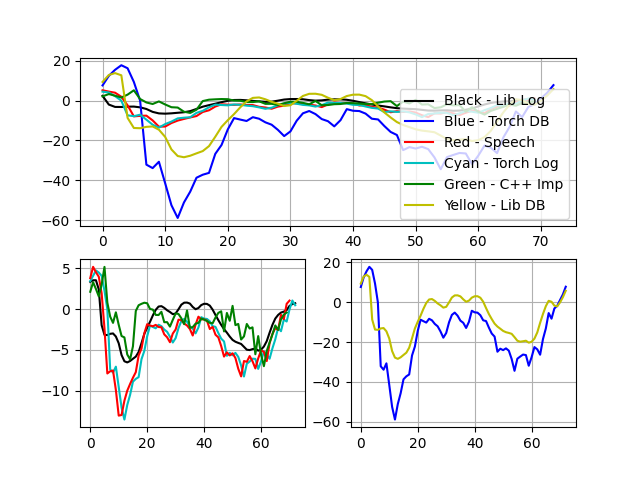
...
可以看出c++实现的MFCC结果(绿色)与torch,Speech,librosa库实现结果趋势基本一致,数值差异在于归一化不同。
感谢您对本项目的支持和关注!如果您觉得这个项目对您有所帮助,请考虑给它一个星标(star)或 fork。您的支持是我们持续改进和发展的动力。
本项目遵循 GNU 许可协议。请参阅 LICENSE 文件以获取更多信息。