Home
 CenoOS is a real time operating system for IOT devices from cenocloud.
CenoOS is a real time operating system for IOT devices from cenocloud.
在根目录/conf/makefile.conf中修改如下配置:
# 开发板支持
ARCH=arm32
BOARD=ek-TM4C123gxl
MCU=TM4C123GH6PM
LINK_FILE=link.ld
OCD_CFG_FILE=ek-tm4c123gxl.cfg!> 其中选项对应board目录下支持的开发版
本人目前使用的开发板为:

OPENOCD_SCRIPT_DIR=/usr/local/share/openocd/scripts/boardBASE_DIR=/Users/neroyang/project/Ceno-RTOS
cd user
make openOCD_connectmake clean
make buildmake flash!> 多喝热水,早睡早起.记得吃饭.
晶体振荡器按照一定速率中断处理器.
每一次time interrupt即是一次System tick. 周期由硬件决定.
System time = 32 bits
- 如果一次tick为1ms,系统可以运行 (2<<32/(1000/60/24))
$\approx$ 50天. - 如果一次tick为20ms,系统可以运行 (2<<32/((1000/20)/60/24))
$\approx$ 2.5年. - 如果一次tick为50ms,系统可以运行 (2<<32/((1000/50)/60/24))
$\approx$ 7年.
保存正在执行的任务上下文
对system time+1 , 如果当前system time > left time 时,产生timing错误.
重置计数器
加载就绪队列中的第一个任务的上下文
Process,Thread and Task?
- Process: 一个运行中的程序
- Thread:是一个轻量级的Process,某种意义上,不同的Thread共享一个地址空间,code 和 data
- Task:是RTOS中的Thread
Task分为软实时(Soft real-time) 和 硬实时(Hard real-time)
- 软实时:截止日期很重要的系统,但如果偶尔错过最后期限,系统仍可正常运行。 例如。 银行系统,多媒体等
- 硬实时:系统必须在规定的期限内完成响应。 例如。 飞行控制系统,汽车系统,机器人等
单个系统可以具有硬实时任务和软实时任务。 实际上,许多系统都具有与错过每个期限相关联的成本函数。
Task状态:
- Ready
- Running
- Waiting/blocked/suspended ...
- Idling
- Terminated
- task id
- Task 状态
- Task 类型
- 优先级
- 上下文指针
- ...
- Task创建
- Task终止
- 修改优先级
- ...
- Task状态
- 程序正常运行
- 中断发生
- 寄存器状态保存
- 中断处理程序运行
- 中断处理程序结束
- 寄存器状态恢复
- 正常程序运行
- 保存运行中Task的上下文
- 读取第一个task的上下文到就绪队列
-
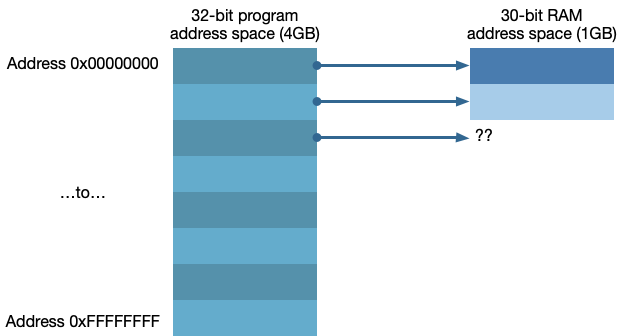
- 如果我们没有足够的RAM怎么办?
MIPS 给每个程序32位(2^32^ bytes = 4GB)的地址空间,也就是说程序可以访问他们32位地址空间(4GB)中的任何字节,那如果我们没有4GB的内存怎么办?
假设我们的物理内存只有1G
-
- 多个程序之间怎么分配,产生的巨大碎片怎么办?
假设我们有三个程序,Program 1需要1GB, Program 2需要2GB, Program 3需要2GB
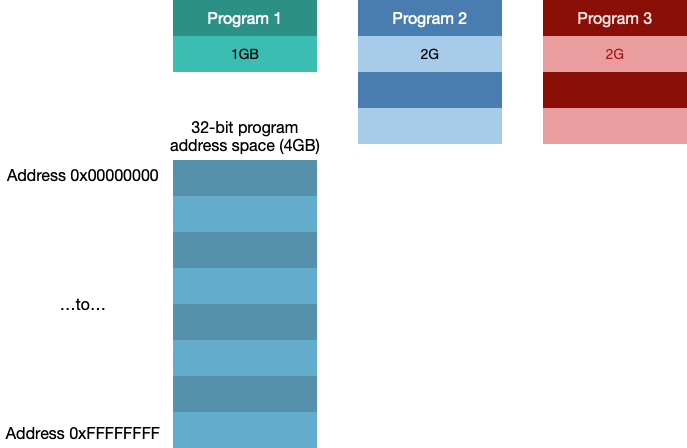
如果我们直接进行分配:
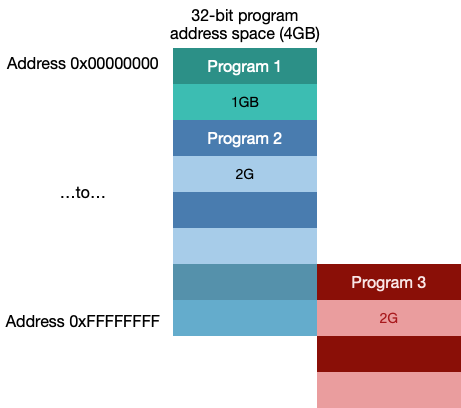
这样的话Program 1和Program 2正常运行, Program3内存不够,如果将Program 1退出,就会出现如下情况:
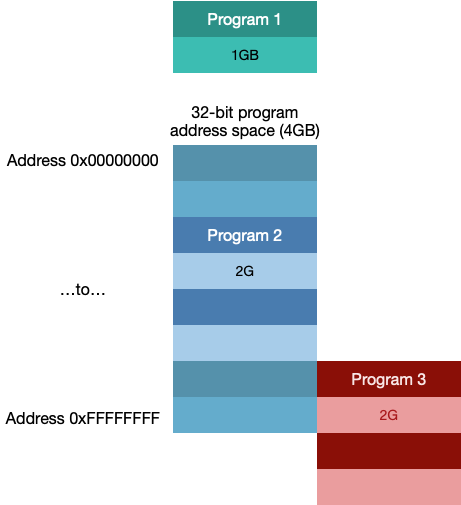
虽然有了2GB的空闲内存,但是还是无法运行Program 3
-
- 每个程序都可以访问任何32位内存地址,那么多个程序访问同样的内存地址怎么办?
如果Program 1 在0x1024的地方存了数据4700, 而Program 2同样在0x1024的位置存了数据80210000
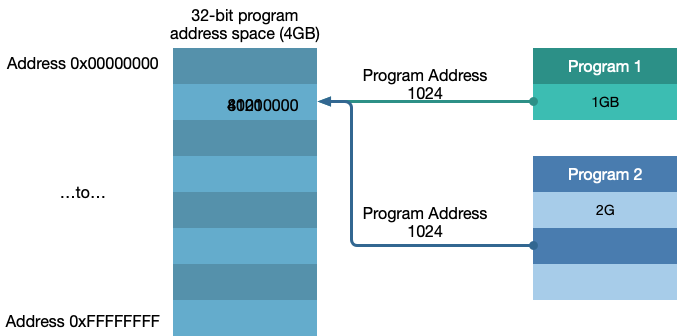
所以,如果所有的程序都去访问32位内存空间,就会出现如下情况:
- 如果内存小与4GB会 crash
- 如果所有的程序都运行的话会内存不够
- 会覆盖其他程序的数据
所以如何解决这个问题? 就是在使用全部内存的情况下能不能给每一个程序它自己的虚拟内存,如果可以的话我们可以将每个程序的内存映射到整个内存上,甚至我们可以将磁盘作为虚拟内存,虽然它会慢.
-
- 如果我们没有足够的RAM怎么办?
在没有虚拟内存的情况下,程序地址就是RAM地址,如下图
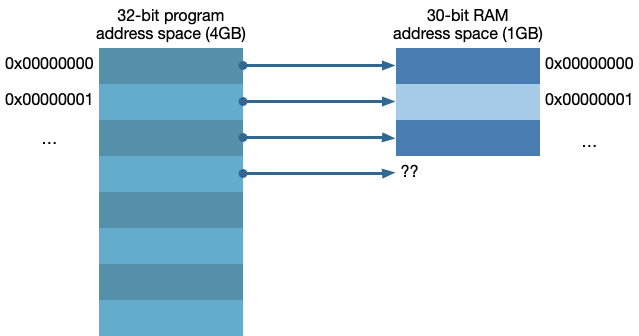
如果我们试图访问比我们实际拥有的RAM更多的时候,程序就会Crash
而虚拟内存通过逻辑映射的方式,将程序地址,映射到RAM地址上.
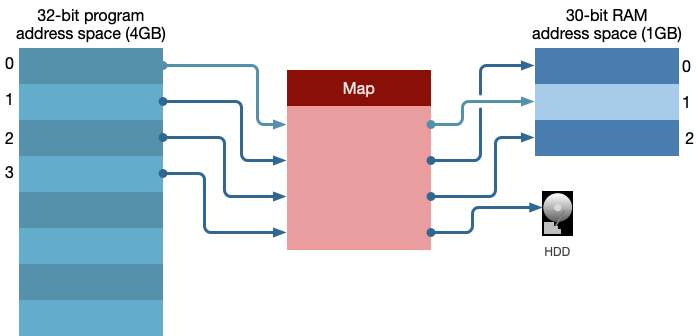
这种映射使得我们使用RAM的方式更加灵活,如果物理内存不够的时候,可以将虚拟内存映射到相对廉价的磁盘上.这样就解决了第一个问题.
-
- 多个程序之间怎么分配,产生的巨大碎片怎么办?
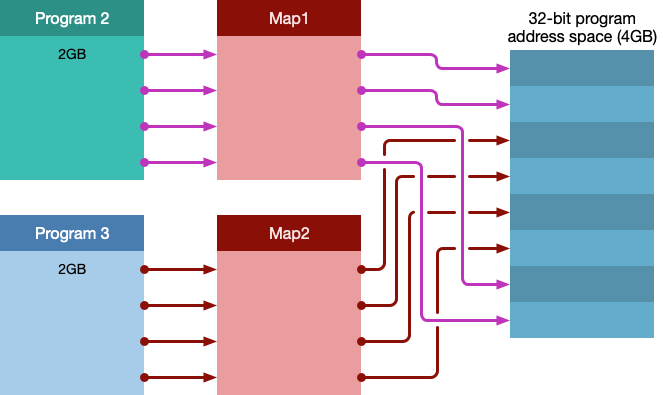
这样每个程序都有他的映射, 这个映射使得每个程序的数据可以放在任何地方.
-
- 如何保证程序的安全?
因为每个程序都有了自己的映射,所以上面的对于同一个地址的存储操作将会变成如下:
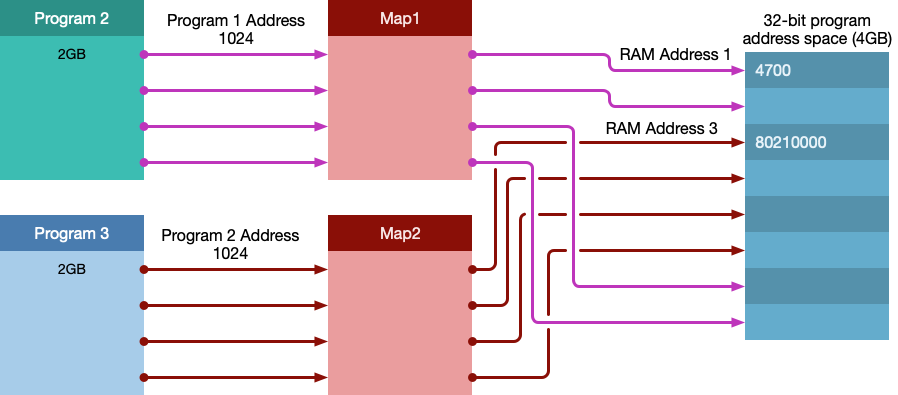
Program 2 将数据4700存在了地址1024上,然后映射表将映射到物理内存地址1上,同样Program 3 将数据80210000存在了地址1024上,然后映射表将映射到物理内存地址3上.这样就避免了多个程序对同一个物理地址操作的风险.
当然了,也有一些公共资源是需要共享的,比如字体等,重复存储只会造成内存的浪费,对于这种情况,映射的方式也可以解决:
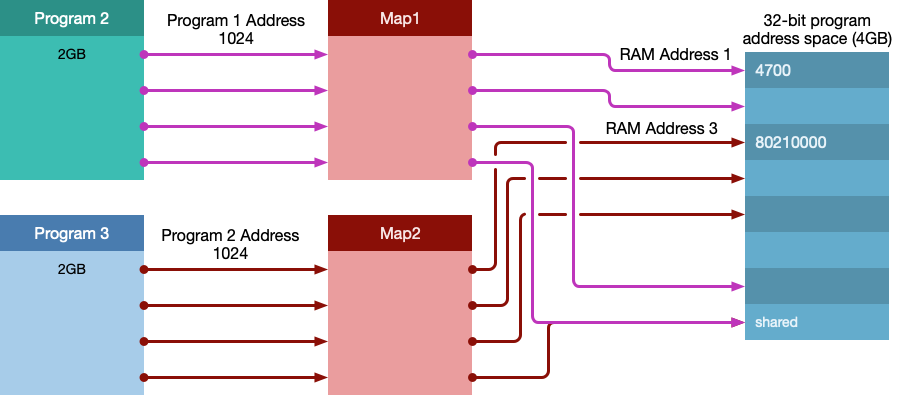
一些基本概念:
- 虚拟内存: 程序真正米面对的
- 物理内存: 计算机里的RAM
- 虚拟地址(VA): 程序使用的,在MIPS中为整个32bit地址空间,从0~2^32^-1
- 物理地址(PA): RAM的真实地址,地址空间由计算机上安装的RAM决定
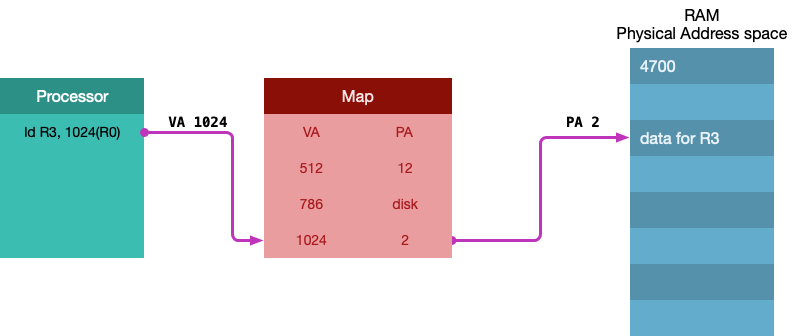
程序如何访问内存?
- 计算机将虚拟地址(VA)转换为物理地址(PA),如果物理地址不在内存里的话,操作系统会从磁盘上加载,然后计算机通过物理地址将数据返回给程序,如下:
对于一个加法操作,大致如下:
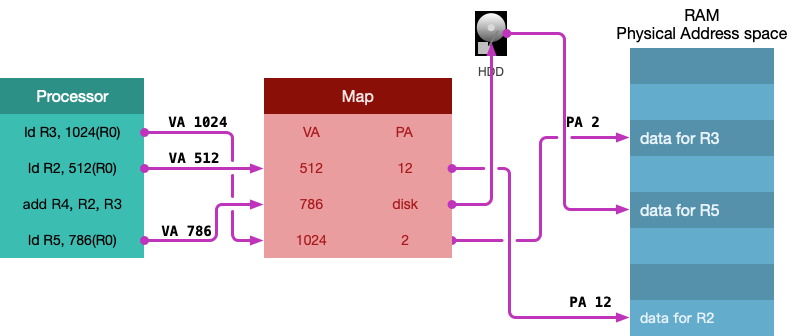
从磁盘加载数据到内存,并更新映射中内存地址:
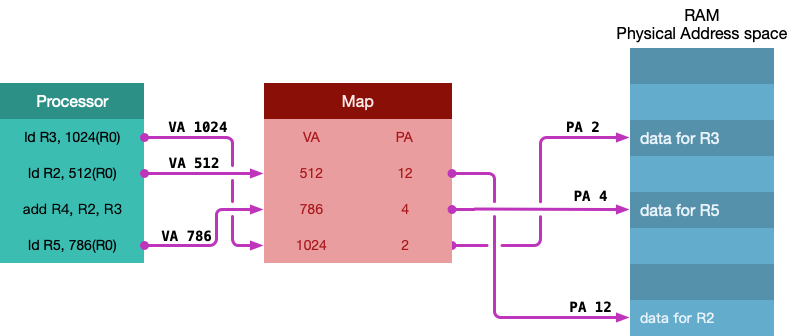
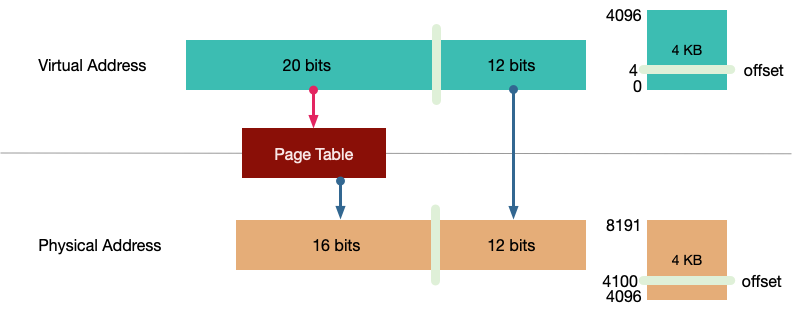
页表是从虚拟地址到物理地址的映射,即上面图中的Map,到目前为止我们对每个虚拟地址已经有了一个页表入口(PET)(Page Table Entry).那么问题来了,我们需要多少个Entry?大概如下:
- 一个字节一个Entry = 2^32^ = 4 billion
- 一个word一个Entry = 2^30^ = 1 billion
如果我们又一个word对齐的内存的话,意味着我们需要能访问到每一个word,也就是有1G的内存将用来做页表.这显然不太合理.
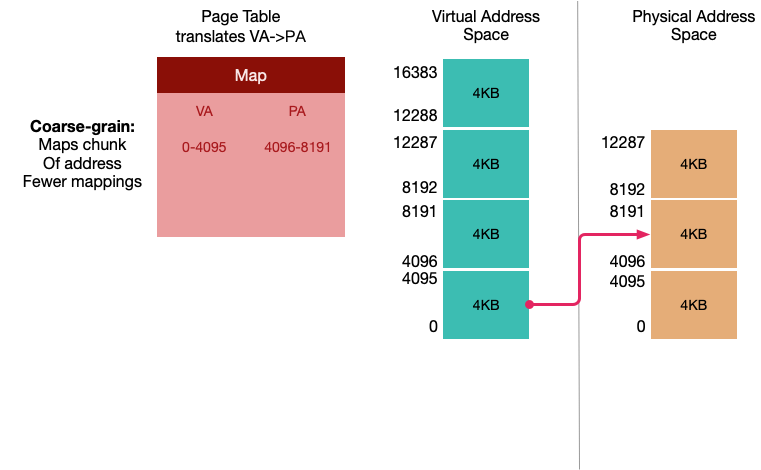
所以好的方案是把内存分为块(pages)来代替words,如下:

每一个Entry 覆盖 4KB 的数据,现在一般是4KB的pages(每一页1024words)
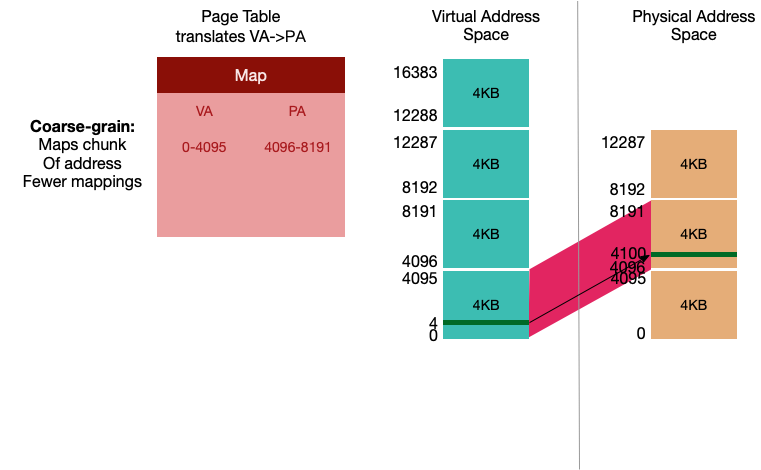
VA 4 是位于VA 0 的虚拟页偏移4字节,同样它的映射也是对应的物理地址偏移4字节
在一个只有256MB内存的32位机器上用4KB分页的话?
硬实时系统没有虚拟内存
- lock all pages in main memory
许多嵌入式实时操作系统没有内存保护机制,任务可以访问任何内存块,因为RTS一般提供给开发者的是RTS本身的源码,所以默认用户在写用户程序的时候设计是正确的,所以内存保护没有必要.这样做的优点如下:
- 实现可预测的时间
- 避免时间开销
大多数商用实时操作系统提供内存保护机制作为一个选项,当然它也有优势所在:
- 对于非法访问,可以进入安全模式
- 适用于复杂的可重构系统
异常包括,错过截止时间,内存不足,超时,死锁,除以零等...
主要分为系统级错误和任务级别错误
- 系统级错误: 死锁..
- 任务级错误: 超时..
typedef unsigned int os_task_id_t;
typedef unsigned int os_time_t;
typedef enum os_err{
OS_ERR =1,
OS_ERR_NONE =0
}os_err_t;
typedef void* cpu_stk_t;
typedef unsigned int cpu_stk_size_t;
typedef char cpu_char_t;
typedef unsigned int priority_t;
typedef unsigned int queue_size_t;
typedef unsigned int sem_count_t;
typedef unsigned int tick_t;对象类型
typedef enum obj_type{
OS_OBJ_TYPE_NONE = 0,
OS_OBJ_SEM_TYPE,
OS_OBJ_MUTEX_TYPE,
OS_OBJ_QUEUE_TYPE,
OS_OBJ_BUFFER_TYPE,
}obj_type_t;对象定义
typedef struct os_obj{
const cpu_char_t* name;
obj_type_t objType;
}os_obj_t;对象容器
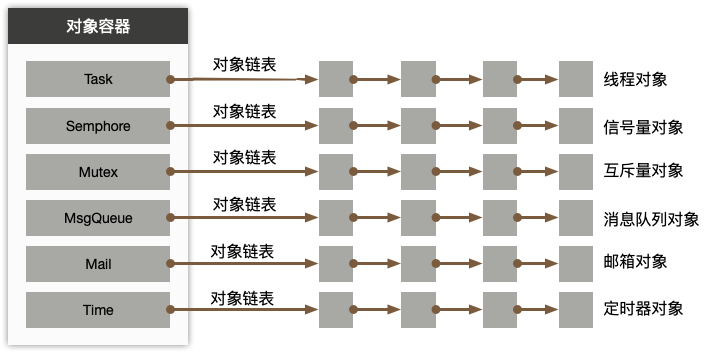
typedef struct os_obj_list{
os_list_t tashHead;
os_list_t mutexHead;
#ifdef __CENO_RTOS_CONFIG_SEM_ON__
os_list_t semHead;
#endif
#ifdef __CENO_RTOS_CONFIG_QUEUE_ON__
os_list_t queueHead;
#endif
#ifdef __CENO_RTOS_CONFIG_RING_BUFFER_ON__
os_list_t bufferHead;
#endif
}os_obj_list_t;链表
typedef struct os_list{
struct os_list* next;
struct os_list* prev;
}os_list_t;队列定义
typedef struct os_queue{
os_obj_t obj,
uint32_t size;
uint32_t start;
uint32_t end;
uint32_t front;
uint32_t rear;
void* elems;
void* ext; // you can write a message queue based on it
}os_queue_t;os_err_t os_queue_create(os_queue_t* me,const cpu_char_t* name, uint32_t size);
os_err_t os_queue_add_item(os_queue_t* queue, void* itemPtr);
os_err_t os_queue_remove();
os_err_t os_queue_clear();
task函数
typedef void (*os_task_handler_t)();task 状态
typedef enum task_state{
OS_STATE_DORMANT = 1,
OS_STATE_READY = 2,
OS_STATE_RUNNING = 1,
OS_STATE_PENDING = 4,
OS_STATE_INTERRUPTED = 4
}task_state_t;task定义
typedef struct os_task{
os_task_id_t id;
cpu_char_t* name;
cpu_stk_t stkPtr;
cpu_stk_size_t stackSize;
os_task_handler_t taskHandler;
task_state_t state; // 32 bit maybe more, but can be faster.
os_time_t timeout;
priority_t priority;
os_task_t* nextTask;
os_task_t* prevTask;
}os_task_t;创建task
os_err_t os_task_create(os_task_t *me,
cpu_char_t *name,
priority_t priority,
cpu_stk_t stkPtr,
cpu_stk_size_t stackSize,
os_task_handler_t taskHandler){
/* round down the stack top to the 8-byte boundary
* NOTE: ARM Cortex-M stack grows down from hi -> low memory
*/
uint32_t *sp = (uint32_t *)((((uint32_t)stkPtr + stackSize) / 8) * 8);
uint32_t *stk_limit;
*(--sp) = (1U << 24); /* xPSR */
*(--sp) = (uint32_t)taskHandler; /* PC */
*(--sp) = 0x0000000EU; /* LR */
*(--sp) = 0x0000000CU; /* R12 */
*(--sp) = 0x00000003U; /* R3 */
*(--sp) = 0x00000002U; /* R2 */
*(--sp) = 0x00000001U; /* R1 */
*(--sp) = 0x00000000U; /* R0 */
/* additionally, fake registers R4-R11 */
*(--sp) = 0x0000000BU; /* R11 */
*(--sp) = 0x0000000AU; /* R10 */
*(--sp) = 0x00000009U; /* R9 */
*(--sp) = 0x00000008U; /* R8 */
*(--sp) = 0x00000007U; /* R7 */
*(--sp) = 0x00000006U; /* R6 */
*(--sp) = 0x00000005U; /* R5 */
*(--sp) = 0x00000004U; /* R4 */
/* save the top of the stack in the thread's attibute */
me->stkPtr = sp;
/* round up the bottom of the stack to the 8-byte boundary */
stk_limit = (uint32_t *)(((((uint32_t)stackSize - 1U) / 8) + 1U) * 8);
/* pre-fill the unused part of the stack with 0xDEADBEEF */
for (sp = sp - 1U; sp >= stk_limit; --sp) {
*sp = 0xDEADBEEFU;
}
/* 将线程放到线程数组里*/
me->id = 1;
me->name = name;
me->priority = priority;
if(priority > 0U ){
me->state=OS_STATE_READY;
}
taskQueue->add_task(me)
}信号量是一个可以通过一个或多个任务获取或释放,以实现同步或互斥的内核对象。简单来说,信号量只不过是一个值或变量或数据,在并行编程环境中可以控制不同任务之间的资源分配。 内核具有不同类型的信号量,包括二进制,计数和互斥(互斥)信号量。
二进制信号量可以具有0或1的值。当二进制信号量的值为0时,信号量被视为不可用(或空)。 当值为1时,二进制信号量被认为可用。
计数信号量使用计数允许多次获取或释放。 在创建计数信号量时,为信号量分配一个数值,该数值表示它最初具有的信号量标记的数量。
互斥(互斥)信号量是一种特殊的二进制信号量,它支持所有权,递归访问,任务删除安全以及一个或多个协议,以避免互斥所固有的问题。 这意味着互斥锁是一个只能有两个状态的同步对象。 他们不归并拥有。
消息队列是一个类似缓冲区的对象,用于向任务发送一个或多个消息,即消息队列用于建立内部任务通信。 基本上队列是一个邮箱数组.Tash和ISR可以通过内核提供的服务向队列发送和接收消息。 从队列中提取消息遵循FIFO或LIFO结构。
长度为1的消息队列称为邮箱。
管道是内核对象,提供非结构化数据交换并促进任务之间的同步。 在传统实现中,管道是单向数据交换设施。
在创建管道时,将返回两个描述符,一个用于管道的每一端(一端用于读取,另一端用于写入)。 数据通过一个描述符写入并通过另一个描述符读取。 数据作为非结构化字节流保留在管道中。 以FIFO顺序从管道读取数据。
MQTT报文定义
https://mcxiaoke.gitbooks.io/mqtt-cn/content/mqtt/02-ControlPacketFormat.html
CenoOS is released under the Apache 2.0 license