Performant Text Classification with Naive Bayes for Kaqchikel Maya - A Julia project for MIT Class 18.337
⚠️ under live development: I am new to NLP so do not expect the best practices 😅
This repository contains:
- basic directory structure
- under
/srcis/datasetswhere unstructured and structured Kaqchikel Corpora is placed
- under
- journal-styled paper that is through a GitHub action that auto-magically renders the
paper/paper.mdfile into a PDF and attached as an artifact to the GitHub action runner
Kaqchikel is a language in the Mayan language family, spoken in Guatemala by about 500,000 people. As of this writing, there are no existing Natural Language Processing (NLP) application for this Mayan language, which leads to a lack of tools that could be implemented to help preserve the language in an advancing and globalized world. The text classification will use a Term Frequency- Inverse Document Frequency (TF-IDF) parallel model and a parallel Naive Bayes algorithm to be evaluated on the Kaqchikel Chronicles, a collection or rare pre-colonial texts. The NLP pipeline developed may potentially make contributions to TextAnalysis.jl, MLJ.jl, and within the Julia NLP ecosystem in general.
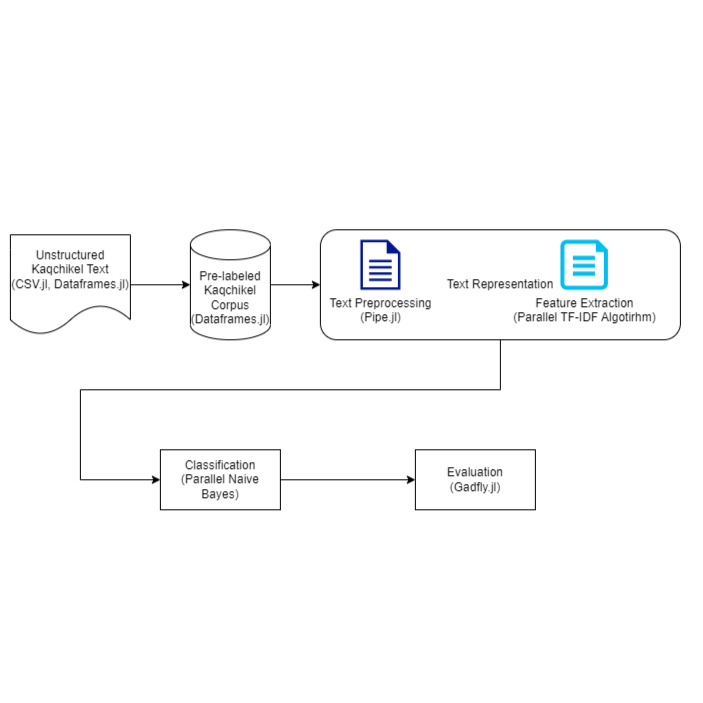
- [] Create a Kaqchikel Database from dictionaries or existing databases
- [] Perform text preprocessing by removing cases, numbers, HTML tags and punctuation (except glottals?)
- [] Create the TF-IDF matrix with default Julia boilerplate
- [] Create the Corpus object from the matrix
- [] Pass Corpus object to default Naive Bayes Classifier
- [] Evaluate the Pipeline
- [] Parallelize and optimize the TF-IDF matrix portion in terms of feature extraction [5]
- [] Parallelize and optimize the TF-IDF matrix portion in terms of feature extraction [5]
- [] Compare results with the new pipeline with previous pipeline