FedEval is a benchmarking platform with comprehensive evaluation model for federated learning. The arxiv paper is available at: https://arxiv.org/abs/2308.11841
Our paper "A Survey for Federated Learning Evaluations: Goals and Measures" is accepted by TKDE.
This survey introduces the evaluation goals and measures of FL, and gives a detailed introduction of the FedEval platform in this repository. (Link to paper)
Our paper "Practical Lossless Federated Singular Vector Decomposition over Billion-Scale Data" (FedSVD) is accepted by KDD 2022.
FedSVD is implemented and benchmarked using FedEval, and the code is also open-sourced. Detail instructions of reproducing the results could be found at Here.
Link to benchmark results: https://di-chai.github.io/FedEval/BenchmarkResults.html
Link to reproduction guidelines: https://di-chai.github.io/FedEval/Reproduce.html
The FedEval evaluation model is the core of our benchmarking system. Currently, four evaluation metrics are
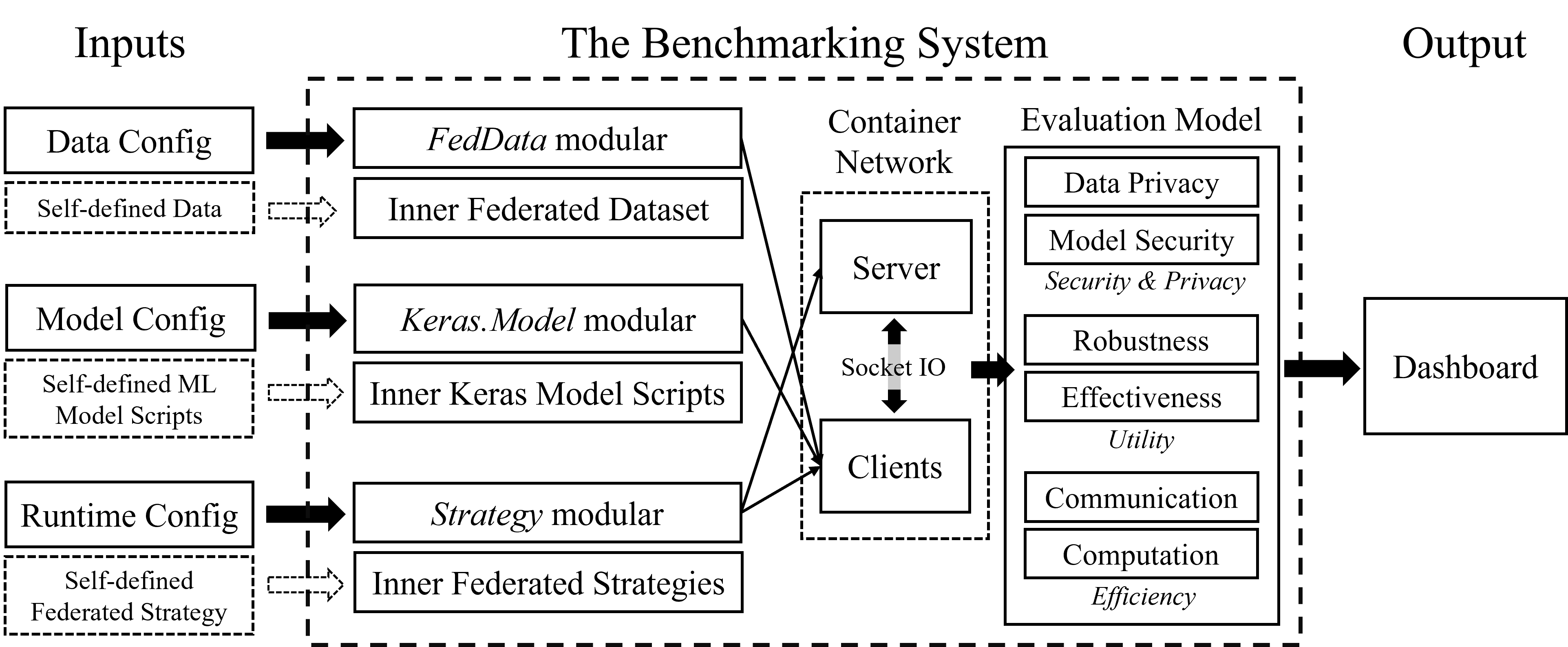
We propose a federated benchmarking system called FedEval shown in the above figure, which demonstrates the inputs, inner architecture, and outputs of the system. To use FedEval, users only need to provide a single script that contains the necessary FL functions or callback functions, such as how the server aggregates the parameters from different clients, to evaluate a new FL algorithm or test new attack/defense methods. The platform consists of three key modules.
- Data Config and the
FedDatamodule: FedEval currently provides seven standard FL datasets, including MNIST, CIFAR10, CIFAR100, FEMNIST, CelebA, Sentiment140, and Shakespeare. Different data settings (e.g., non-IID data) can be implemented by changing the data configs. Self-defined data is also supported. We only need to inherit theFedDataclass and define theload_datafunction to add a new dataset, which will share the same processing functions with the built-in datasets. - Model Config and the
Keras.Modelmodule: Currently, three machine learning models are built inside our system, includingMLP,LeNet, andStackedLSTM. We use TensorFlow as the backend, and all the models are made via subclassing the Keras model. Thus, adding new machine learning models is very simple in FedEval. - Runtime Config and the
strategymodule: One of the essential components in FedEval is thestrategymodule, which defines the protocol of the federated training. Briefly, the FL strategy module supports the following customization:- Customized uploading message, i.e., which parameters are uploaded to the server from the clients.
- Customized server aggregation method, e.g., weighted average.
- Customized training method for clients, e.g., the clients' model can be trained using regular gradient descent method or other solutions like knowledge distillation.
- Customized methods for incorporating the global and local model**, e.g., one popularly used method is replacing the local model with the global one before training.
We use the docker container technology to simulate the server and clients (i.e., each participant is a container), and use socket IO in the communication. The isolation between different containers guarantees that our simulation can reflect the real-world application. The entire system is open-sourced, with seven benchmark FL datasets, including MNIST, CIFAR10, CIFAR100, FEMNIST, CelebA, Sentiment140, and Shakespeare. The essential components (i.e., dataset, ML models, and FL strategy) can be easily used or self-defined. Thus researchers can implement their new idea and evaluate using FedEval very quickly.
Briefly, three steps are needed to start an experiment in our benchmarking system:
-
Step 1: Determine the benchmark dataset, ML model, and FL strategy, then modify the data, model, and runtime configs based on the templates.
-
Step 2: Use the built-in tool to generate data for clients and create the docker-compose files.
-
Step 3: Start the experiments using docker-compose, and monitor the dashboard for the evaluation status and results.