
![]()
![]()
pmu tools is a collection of tools for profile collection and performance analysis on Intel CPUs on top of Linux perf. This uses performance counters in the CPU.
其他参考 Performance Prediction Toolkit (PPT)
Execution-Cache-Memory Performance Model: Introduction and Validation
Quantifying performance bottlenecks of stencil computations using the Execution-Cache-Memory model
pmu-tools 是运行在 Intel CPU 的 Linux 上的一个集工具配置文件收集和性能分析工具。它有一个包装器来“穿孔”,提供了一个完整的核心事件列表为常见的英特尔cpu。这允许您使用所有英特尔事件,不仅仅是内装式事件的穿孔。支持英特尔“offcore”事件在较旧的系统不支持这个在英特尔。Offcore事 件允许您配置文件位置的内存访问外CPU的缓存。它实现了解决了一些问题与事件offcore Sandy Bridge EP(Intel Xeon E5第一代)。这是自动启用了各自的活动,也可作为一个独立的程序。有些实用程序来访问pci msrs空间或在命令行上。一个实用程序程序直接从用户空间的测压装置(pmumon.py)计算。这主要是用于测试和实验目的。一个图书馆自我剖析与 Linux因为Linux 3.3(对于自我剖析在旧的内核,您就可以使用简单的测压装置。一个示例程序地址剖析在Nehalem和后来英特尔cpu(addr)。一个程序,打印当 前运行的事件(事件rmap)。
现代 CPU 大多具有性能监控单元(Performance Monitoring Unit, PMU),用于统计系统中发生的特定硬件事件,例如 缓存未命中(Cache Miss) 或者 **分支预测错误(Branch Misprediction)**等。同时,多个事件可以结合计算出一些高级指标,例如每指令周期数(CPI),缓存命中率等。一个特定的微体系架构可以通过 PMU 提供数百个事件。对于发现和解决特定的性能问题,我们很难从这数百个事件中挑选出那些真正有用的事件。 这需要我们深入了解微体系架构的设计和 PMU 规范,才能从原始事件数据中获取有用的信息。
自顶向下的微体系架构分析方法(Top-Down Microarchitecture Analysis Method, TMAM)可以在乱序执行的内核中识别性能瓶颈,其通用的分层框架和技术可以应用于许多乱序执行的微体系架构。TMAM 是基于事件的度量标准的分层组织,用于确定应用程序中的主要性能瓶颈,显示运行应用程序时 CPU 流水线的使用情况。
现代高性能 CPU 的流水线非常复杂。 一般来说,CPU 流水线在概念上分为两部分,即前端(Front-end)和后端(Back-end)。Front-end 负责获取程序代码指令,并将其解码为一个或多个称为微操作(uOps)的底层硬件指令。uOps 被分配给 Back-end 进行执行,Back-end 负责监控 uOp 的数据何时可用,并在可用的执行单元中执行 uOp. uOp 执行的完成称为退役(Retirement),uOp 的执行结果提交并反馈到>架构状态(CPU 寄存器或写回内存)。 通常情况下,大多数 uOps 通过流水线正常执行然后退役,但有时候投机执行的 uOps 可能会在退役前被取消,例如在分支预测错误的情况下。
在最近的英特尔微体系结构上,流水线的 Front-end 每个 CPU 周期(cycle)可以分配4个 uOps ,而 Back-end 可以在每个周期中退役4个 uOps。流水线槽(pipeline slot) 代表处理一个 uOp 所需的硬件资源。 TMAM 假定对于每个 CPU 核心,在每个 CPU 周期内,有4个 pipeline slot 可用,然后使用专门设计的 PMU 事件来测量这些 pipeline slot 的使用情况。在每个 CPU 周期中,pipeline slot 可以是空的或者被 uOp 填充。 如果在一个 CPU 周期内某个pipeline slot 是空的,称之为一次停顿(stall)。如果 CPU 经常停顿,系统性能肯定是受到影响的。TMAM 的目标就是确定系统性能问题的主要瓶颈。
下图展示并总结了乱序执行微体系架构中自顶向下确定性能瓶颈的分类方法。这种自顶向下的分析框架的优点是一种结构化的方法,有选择地探索可能的性能瓶颈区域。 带有权重的层次化节点,使得我们能够将分析的重点放在确实重要的问题上,同时无视那些不重要的问题。
例如,如果应用程序性能受到指令提取问题的严重影响, TMAM 将它分类为 Front-end Bound 这个大类。 用户或者工具可以向下探索并仅聚焦在 Front-end Bound 这个分类上,直到找到导致应用程序性能瓶颈的直接原因或一类原因。
- 1、Front-end Bound 表示 pipeline 的 Front-end 不足以供应 Back-end。
- 2、Front-end 是 pipeline 的一部分,负责交付 uOps 给 Back-end 执行。
- 3、Front-end Bound 进一步分为 Fetch Latency(例如,ICache or ITLB misses,指令延迟)和 Fetch Bandwidth(例如,sub-optimal decoding,取指带宽)。
- 1、1Back-end Bound 表示由于缺乏接受执行新操作所需的后端资源而导致
- 2、停顿的 pipeline slot 。它进一步分为分为 Memory Bound (由于内存子系统造成的执行停顿)和 Core Bound(执行单元压力 Compute Bound 或者缺少指令级并行 ILP)。
- 1、Bad Speculation 表示由于分支预测错误导致的 pipeline slot 被浪费,
- 2、主要包括 (1) 执行最终被取消的 uOps 的 pipeline slot,以及 (2) 由于从先前的错误猜测中恢复而导致阻塞的 pipeline slot。
-
1、Retiring 表示运行有效 uOp 的 pipeline slot。 理想情况下,我们希望看到所有的 pipeline slot 都能归类到 Retiring.
-
2、因为它与 IPC 密切相关。 尽管如此,高 Retiring 比率并不意味着没有提升优化的空间。
后两者 3、4 表示非停顿的 pipeline slot,前两者表示停顿的 pipeline slot。
下图描述了一个简单的决策树来展示向下分析的过程。如果一个 pipeline slot 被某个 uOp 使用,它将被分类为 Retiring 或 Bad Speculation,具体取决于它是否最终提交。
如果 pipeline 的 Back-end 部分不能接受更多操作(也称为 Back-end Stall),未使用的 pipeline slot 被分类为 Back-end Bound。Front-end Bound 则表示>在没有 Back-end Stall 的情况下没有操作(uOps)被分配执行。
uOp 微操作 被分配? alloc
| 是 | 否 (pipeline slot流水线停顿导致 指令未未分配执行)
-
pmu-tools is now generally python3 clean (but still runs with python2 by default). One exception is parser which would need to be ported to the python3 construct.
-
New tool utilized.py to remove idle CPUs from toplev output
-
toplev --import can now directly decompress xz and gz files. -o / --valcsv / --perf-output can now directly compress files if their names are specified with .xz or .gz.
-
toplev update to Ahmad Yasin's/Anton Hanna's TMA 4.0: New Models ICL: New model for IceLake client processor
Note that running on Icelake with HyperThreading enabled requires updating the perf tool to a recent version that supports the "percore" notifier.
New Metrics and Info groups
- IpFLOP: Instructions per Floating Point (FP) Operation [BDW onwards]
- New breakdown for Frontend_Bandwidth per fetch unit: MITE, DSB & LSD
- IO_{Read|Write}_BW: Average IO (network or disk) Bandwidth Use for {Reads|Writes} [server models]
- LSD_Coverage: Fraction of Uops delivered by the LSD (Loop Stream Detector; aka Loop Cache)
- New Info group: Frontend that hosts LSD_Coverage, DSB_Coverage and IpBAClear
Key Enhancements & fixes
- Tuned/balanced Frontend_Latency & Frontend_Bandwidth (Bandwidth exposed as a very short FE latency) [SKL onwards]
- Tuned/balanced Memory_Bound & Core_Bound in Backend_Bound breakdown [SKL onwards]
- Tuned L2_Bound Node for high memory BW workloads [SKL onwards]
- BpTB, IpL, IpS & IpB renamed to BpTkBranch, IpLoad, IpStore & IpBranch respectively (Inst_Mix info metrics)
- Backporting IpFarBranch to all pre SKL models
- Renamed DRAM_{Read_Latency|Parallel_Reads} to MEM_{Read_Latency|Parallel_Reads}
- Fixed Count Domain for (Load|Store|ALU)_Op_Utilization [SNB onwards]
- Removed OCR L3 prefetch Remote HitM events [SKX,CLX]
- Fixed descriptions for Ports_Utilized_{0|1|2|3m}
- Fixed Pause latency [CLX]
-
toplev can now generate a script with --gen-script to collect toplev data on a different system. The generated data can be then imported with --import
-
toplev / event_download / ocperf have been ported to python3. They still work with python2, which is so far the default and used by the standard #! shebangs. But on systems that have no python2 they can be run with a python3 interpreter. This feature is still experimental, please report any regressions.
-
toplev now supports --per-core / --per-socket output in SMT mode, and also a --global mode. This also works with reprocessed data (from --perf-output / --import), so it is possible to slice a single collection. It is also possible to specify them at the same time to get separate summaries. With --split-output -o file the different aggregations are written to different files.
-
toplev update to Ahmad Yasin's/Anton Hanna's TMA 3.6:
- {Load|Store}_STLB_(Hit|Miss): new metrics that breakdown DTLB_{Load|Store} costs
- L2_Evictions_(Silent|NonSilent)_PKI: L2 (silent|non silent) evictions rate per Kilo instructios
- IpFarBranch - Instructions per Far Branch
- Renamed 0/1/2/3m_Ports_Utilized
- DSB_Switches is now available
- Count Domain changes for multiple nodes. New threshold for IpTB ( Instructions per Taken Branches )
- Re-organized/renamed Metric Group (e.g. Frontend_Bound => Frontend)
-
toplev now can run with the NMI watchdog enabled
- This may reduce the need for being root to change this setting
- It may still require kernel.perf_event_paranoid settings <1, unless --single-thread --user is used. Some functionality like uncore monitoring requires root or kernel.perf_event_paranoid < 0.
-
toplev now supports running in KVM guests
- The guest needs to have the PMU enabled (e.g. -cpu host for qemu)
- The guest should report the same CPU type as the host (also -cpu host), otherwise the current CPU needs to be overriden with FORCECPU=../EVENTMAP=..
- PEBS sampling, offcore response, and uncore monitoring are not supported
- The "ocperf" wrapper to "perf" that provides a full core performance counter event list for common Intel CPUs. This allows to use all the Intel events, not just the builtin events of perf. Can be also used as a library from other python programs
- The "toplev.py" tool to identify the micro-architectural bottleneck for a workload. This implements the TopDown or TopDown2 methodology.
- The "ucevent" tool to manage and compute uncore performance events. Uncore is the part of the CPU that is not core. Supports many metrics for power management, IO, QPI (interconnect), caches, and others. ucevent automatically generates event descriptions for the perf uncore driver and pretty prints the output. It also supports computing higher level metrics derived from multiple events.
- A library to resolve named intel events (like INST_RETIRED.ANY) to perf_event_attr (jevents) jevents also supports self profiling with Linux since Linux 3.3. Self profiling is a program monitoring its own execution, either for controlled benchmarking or to optimize itself. For self-profiling on older kernels you can use simple-pmu
- Support for Intel "offcore" events on older Linux systems where the kernel perf subsystem does not support them natively. Offcore events allow to categorize memory accesses that go outside the core.
- Workarounds for some issues with offcore events on Sandy Bridge EP (Intel Xeon E5 v1) This is automatically enabled for the respective events with ocperf, and also available as a standalone program or python library.
- A variety of tools for plotting and post processing perf stat -I1000 -x, or toplev.py -I1000 -x, interval measurements.
- An example program for address profiling on Nehalem and later Intel CPUs (addr)
- Some utility programs to access pci space or msrs on the command line
- A utility program to program the PMU directly from user space (pmumon.py) for counting. This is mainly useful for testing and experimental purposes.
- A program to print the currently running events (event-rmap)
- Support for analyzing the raw PEBS records with perf.
- A pandas/scipy data model for perf.data analytics (work in progress)
- The plotting tools could use a lot of improvements. Both tl-serve and tl-barplot. If you're good in python or JS plotting any help improving those would be appreciated.
Check out the repository. Run the tools from the directory you checked out (but it does not need to be the current directory) They automatically search for other modules and data files in the same directory the script was located in.
You can set the PATH to include the repository to run the tools from other directories:
export PATH=/path/to/pmu-tools:$PATH
You want to:
- understand CPU bottlenecks on the high-level: use toplev.
- display toplev output graphically: use tl-server or toplev --graph
- know what CPU events to run, but want to use symbolic names: use ocperf.
- measure interconnect/caches/memory/power management on Xeon E5+: use ucevent
- Use perf events from a C program: use jevents
- Query CPU topology or disable HyperThreading: use cputop
- Change Model Specific Registers: use msr
- Change PCI config space: use PCI
The other tools are for more obscure usages.
All tools (except for parser/) should work with a python 2.7 standard installation. All need a reasonably recent perf (RHEL5 is too old)
ocperf.py should work with python 2.6, or likely 2.5 when the json module is installed. msr.py will also work with 2.6 if argparse is installed (it is enough to copy those files from a python 2.7 installation)
Except for the modules in parser/ there are no special dependencies outside a standard python install on a recent Linux system with perf.
parser/ needs a scipy stack with pandas and pyelftools.
The perf tool should not be too old.
toplev has kernel dependencies, please see https://github.com/andikleen/pmu-tools/wiki/toplev-kernel-support
simple-pebs and pebs-grabber require a Linux kernel source tree to build. They may not build on some older versions of Linux (patches welcome)
ocperf is a wrapper to "perf" that provides a full core event list for common Intel CPUs. This allows to use all the Intel defined events, not just the builtin events of perf.
A more detailed introduction is in Andi's blog
Ahmad Yasin's toplev/TopDown tutorial
ocperf.py list List all the events perf and ocperf supports on the current CPU
ocperf.py stat -e eventname ...
ocperf.py record -c default -e eventname ...
ocperf.py report
When an older kernel is used with offcore events (events that count types of memory accesses outside the CPU core) that does not support offcore events natively, ocperf has to run as root and only one such profiling can be active on a machine.
When "-c default" is specified for record, the default sampling overflow value will be filled in for the sampling period. This option needs to be specified before the events and is not supported for all CPUs. By default perf uses a dynamic sampling period, which can cause varying (and sometimes large) overhead. The fixed period minimizes this problem.
If you have trouble with one of the many acronyms in the event list descriptions, the Intel optimization manual describes many of them.
ocperf.py can be also used as a python module to convert or list events for the current CPU:
import ocperf
emap = ocperf.find_emap()
if not emap:
sys.exit("Unknown CPU or cannot find event table")
ev = emap.getevent("BR_MISP_EXEC.ANY")
if ev:
print "name:", ev.output()
print "raw form:", ev.output(use_raw=True)
print "description:, ev.descTo retrieve data for other CPUs set the EVENTMAP environment variable to the csv file of the CPU before calling find_emap()
The msr.py, pci.py, latego.py can be used as standalone programs or python modules to change MSRs, PCI config space or enable/disable the workarounds.
For example to set the MSR 0x123 on all CPUs to value 1 use:
$ sudo ./msr.py 0x123 1
To read MSR 0x123 on CPU 0
$ sudo ./msr.py 0x123
To read MSR 0x123 on CPU 3:
$ sudo python
>>> import msr
>>> msr.readmsr(0x123, 3)
To set bit 0 in MSR 0x123 on all CPUs:
$ sudo python
>>> import msr
>>> msr.writemsr(0x123, msr.readmsr(0x123) | 1)
(this assumes the MSR has the same value on all CPUs, otherwise iterate the readmsr over the CPUs)
Identify the micro-architectural bottleneck of a workload.
The bottlenecks are expressed as a tree with different levels (max 5). Each bottleneck is only meaningful if the parent higher level crossed the threshold (it acts similar to a binary search). The tool automatically only prints meaningful ratios, unless -v is specified.
This follows the "Top Down" methodology. The best description of the method is in the "A top-down method for performance analysis and counter architecture" paper (ISPASS 2014, available here) I didn't invent it, I'm just implementing it.
A more gentle introduction is in andi's blog
Please also see the manual and tutorial
toplev.py only supports counting, that is it cannot tell you where in the program the problem occurred, just what happened. There is now an experimental --show-sample option to suggest sampling events for specific problems. The new --run-sample option can also automatically sample the program by re-running.
Requires Intel CPUs Sandy Bridge (Core 2nd gen, Xeon 5xxx) or newer or Atom Silvermont or newer. Quark or Xeon Phi are not supported.
By default the simple high level model is used. The detailed model is selected with -lX, with X being the level.
On non-SMT systems only the program is measured by default, while with SMT on the whole system is measured.
toplev.py -l2 program measure whole system in level 2 while program is running
toplev.py -l1 --single-thread program measure single threaded program. system must be idle.
toplev.py -l3 --no-desc -I 100 -x, sleep X measure whole system for X seconds every 100ms, outputting in CSV format.
toplev.py --all --core C0 taskset -c 0,1 program Measure program running on core 0 with all nodes and metrics enables
General operation: --interval INTERVAL, -I INTERVAL Measure every ms instead of only once --no-multiplex Do not multiplex, but run the workload multiple times as needed. Requires reproducible workloads. --single-thread, -S Measure workload as single thread. Workload must run single threaded. In SMT mode other thread must be idle. --fast, -F Skip sanity checks to optimize CPU consumption --import _IMPORT Import specified perf stat output file instead of running perf. Must be for same cpu, same arguments, same /proc/cpuinfo, same topology, unless overriden --gen-script Generate script to collect perfmon information for --import later
Measurement filtering: --kernel Only measure kernel code --user Only measure user code --core CORE Limit output to cores. Comma list of Sx-Cx-Tx. All parts optional.
Select events: --level LEVEL, -l LEVEL Measure upto level N (max 6) --metrics, -m Print extra metrics --sw Measure perf Linux metrics --no-util Do not measure CPU utilization --tsx Measure TSX metrics --all Measure everything available --frequency Measure frequency --power Display power metrics --nodes NODES Include or exclude nodes (with + to add, -|^ to remove, comma separated list, wildcards allowed) --reduced Use reduced server subset of nodes/metrics --metric-group METRIC_GROUP Add (+) or remove (-|^) metric groups of metrics, comma separated list from --list-metric-groups.
Query nodes: --list-metrics List all metrics --list-nodes List all nodes --list-metric-groups List metric groups --list-all List every supported node/metric/metricgroup
Workarounds: --no-group Dont use groups --force-events Assume kernel supports all events. May give wrong results. --ignore-errata Do not disable events with errata --handle-errata Disable events with errata
Output: --per-core Aggregate output per core --per-socket Aggregate output per socket --per-thread Aggregate output per CPU thread --global Aggregate output for all CPUs --no-desc Do not print event descriptions --desc Force event descriptions --verbose, -v Print all results even when below threshold or exceeding boundaries. Note this can result in bogus values, as the TopDown methodology relies on thresholds to correctly characterize workloads. --csv CSV, -x CSV Enable CSV mode with specified delimeter --output OUTPUT, -o OUTPUT Set output file --split-output Generate multiple output files, one for each specified aggregation option (with -o) --graph Automatically graph interval output with tl-barplot.py --graph-cpu GRAPH_CPU CPU to graph using --graph --title TITLE Set title of graph --quiet Avoid unnecessary status output --long-desc Print long descriptions instead of abbreviated ones. --columns Print CPU output in multiple columns for each node --summary Print summary at the end. Only useful with -I --no-area Hide area column --perf-output PERF_OUTPUT Save perf stat output in specified file
Environment: --force-cpu {snb,jkt,ivb,ivt,hsw,hsx,slm,bdw,bdx,skl,knl,skx,clx,icl} Force CPU type --force-topology findsysoutput Use specified topology file (find /sys/devices) --force-cpuinfo cpuinfo Use specified cpuinfo file (/proc/cpuinfo) --force-hypervisor Assume running under hypervisor (no uncore, no offcore, no PEBS) --no-uncore Disable uncore events --no-check Do not check that PMU units exist
Additional information: --print-group, -g Print event group assignments --raw Print raw values --valcsv VALCSV, -V VALCSV Write raw counter values into CSV file --stats Show statistics on what events counted
Sampling: --show-sample Show command line to rerun workload with sampling --run-sample Automatically rerun workload with sampling --sample-args SAMPLE_ARGS Extra rguments to pass to perf record for sampling. Use + to specify - --sample-repeat SAMPLE_REPEAT Repeat measurement and sampling N times. This interleaves counting and sampling. Useful for background collection with -a sleep X. --sample-basename SAMPLE_BASENAME Base name of sample perf.data files
Other perf arguments allowed (see the perf documentation) After -- perf arguments conflicting with toplev can be used.
toplev defaults to measuring the full system and show data for all CPUs. Use taskset to limit the workload to known CPUs if needed. In some cases (idle system, single threaded workload) --single-thread can also be used.
The lower levels of the measurement tree are less reliable than the higher levels. They also rely on counter multi-plexing, and can not run each equation in a single group, which can cause larger measurement errors with non steady state workloads
(If you don't understand this terminology; it means measurements in higher levels are less accurate and it works best with programs that primarily do the same thing over and over)
If the program is very reproducible -- such as a simple kernel -- it is also possible to use --no-multiplex. In this case the workload is rerun multiple times until all data is collected. Do not use together with sleep.
toplev needs a new enough perf tool and has specific requirements on the kernel. See http://github.com/andikleen/pmu-tools/wiki/toplev-kernel-support
Other CPUs can be forced with FORCECPU=name This usually requires setting the correct event map with EVENTMAP=...
Please see the ucevent documentation
interval-plot.py can plot the output of perf stat -I1000 -x
Requires matplotlib to be installed.
Below is the level 2 toplev measurement of a Linux kernel compile. Note that tl-barplot below is normally better to plot toplev output.
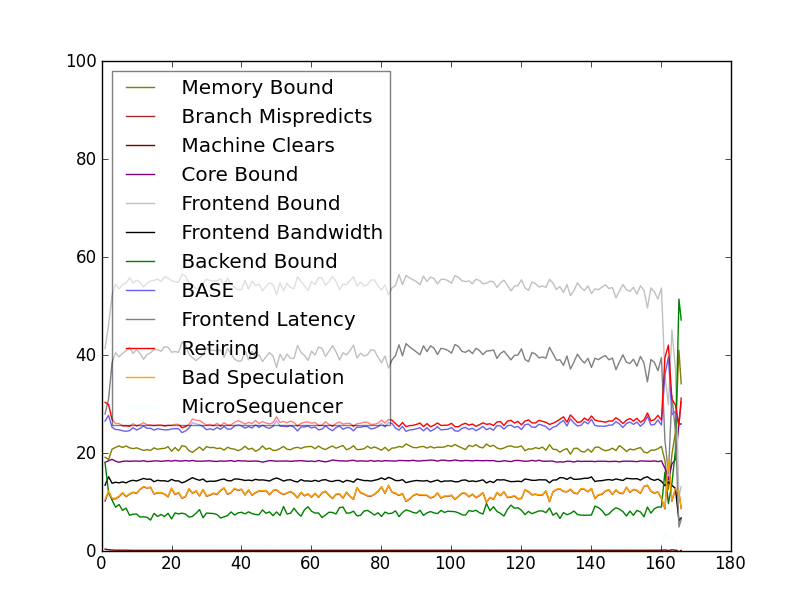
This converts the output of perf stat -Ixxx -x, / toplev.py -Ixxx -x, to a normalized output (one column for each event). This allows easier plotting and processing with other tools (spreadsheets, R, JMP, gnuplot etc.)
Plot an already normalized data file. Requires pyplot to be installed.
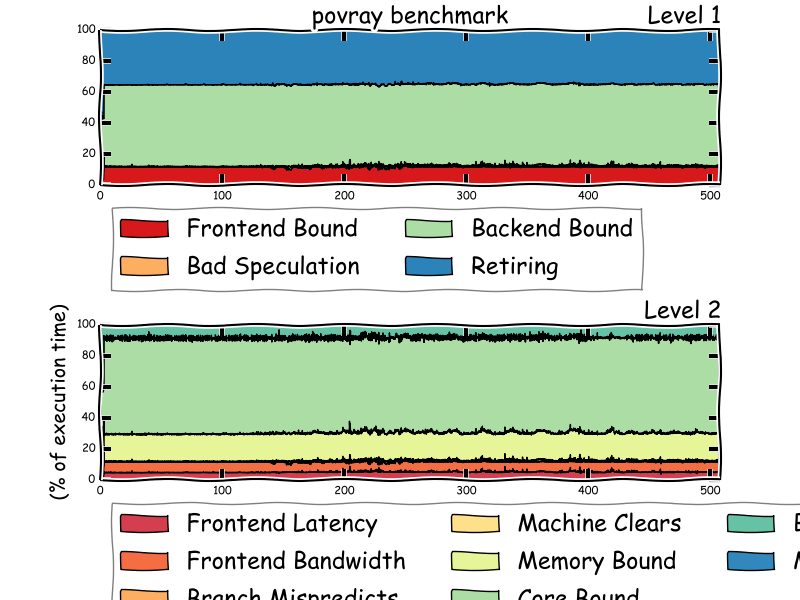
Plot output from toplev.py -I 1000 -v -x, --output file.csv -lLEVELS toplev outputs percentages, so it's better to use a stacked plot, instead of the absolute values interval-plot displays. tl-barplot implements a stacked barplot plot.
Requires matplotlib to be installed.
toplev.py --single-thread -l3 --title "GNU grep" --graph grep -r foo /usr/*

This assumes the workload is single threaded. tl-barplot can only display a single CPU, if --single-thread is not appropriate then the CPU to plot needs to be specified with --graph-cpu.
With a new enough matplotlib you can also enable xkcd mode (install Humor Sans first)
{kind=link}
{kind=link}
Display toplev.py output in a web browser.
Download dygraphs. Only needs to be done once.
wget http://dygraphs.com/1.0.1/dygraph-combined.js
Run toplev:
toplev.py --all -I 100 -o x.csv ...
tl-serve.py x.csv
Then browse http://localhost:9001/ in your web browser.
query cpu topology and print all matching cpu numbers cputop "query" ["format"]
query is a python expression, using variables: socket, core, thread or "offline" to query all offline cpus format is a printf format with %d. %d will be replaced with the cpu number. format can be offline to offline the cpu or online to online
Print all cores on socket 0
cputop "socket == 0"
Print all first threads in each core on socket 0
cputop "thread == 0 and socket == 0"
Disable all second threads (disable hyper threading)
cputop "thread == 1" offline
Reenable all second threads (reenable hyper threading)
cputop "thread == 0" online
Older perf doesn't export the raw PEBS output, which contains a lot of useful information. PEBS is a sampling format generated by Intel CPUs for some events.
pebs-grabber grabs PEBS data from perf. This assumes the perf pebs handler is running, we just also do trace points with the raw data.
May need some minor tweaks as kernel interface change, and will also not likely work on very old kernels.
This will create two new trace points trace_pebs_v1 and trace_pebs_v2 that log the complete PEBS record. When the CPU supports PEBSv2 (Haswell) the additional fields will be logged in pebs_v2.
make [KDIR=/my/kernel/build/dir]
insmod pebs-grabber.ko
# needs to record as root
perf record -e cycles:p,pebs_v1,pebs\_v2 [command, -a for all etc.]
perf report
perf script to display pebs data
# alternatively trace-cmd and kernelshark can be also used to dump
# the pebs data
See http://download.intel.com/products/processor/manual/253669.pdf 18.10.2 for a description of the PEBS fields.
Note this doesn't work with standard FC18 kernels, as they broke trace points in modules. It works with later and earlier kernels.
event-rmap [cpu] prints the currently running events. This provides an easier answer to question Q2j in Vince Weaver's perf events FAQ.
When modifying toplev please run tl-tester. For ocperf run tester. For jevents run jevents/tester. other-tester tests other random tools. The all-tester script runs all test suites.
Please post to the linux-perf-users@vger.kernel.org mailing list. For bugs please open an issue on https://github.com/andikleen/pmu-tools/issues
ocperf, toplev, ucevent, parser are under GPLv2, jevents is under the modified BSD license.
Andi Kleen pmu-tools@halobates.de