Arbitrary nesting of heap types in contract returns #1046
Assignees


Labels
blocked
enhancement
New feature or request
epic
An epic is a high-level master issue for large pieces of work.
Comments
|
Waiting to see how far away encoding support is in sway. |
|
Hi there! |
Closed
5 tasks
hal3e
added a commit
that referenced
this issue
Apr 2, 2024
) closes: #1278, #1279, #1046 This PR adds support for the new encoding scheme for contracts, scripts and predicates. I have added a new `ExperimentalBoundedEncoder` which can be activated with the `experimental` cfg flag. I have tried to minimize the impact of the new encoder as much as possible to make it easier for review. A full refactor of the whole sdk is necessary once the new encoding becomes the default one. - The function selector changed and now it is the name of the method. - The `CALL` opcode changed with the new encoding and is expecting the following call data: ContractID, pointer to fn_selector (name of the method), pointer to encoded arguments, number of coins, asset_id, gas_forwarded.
|
Closed by #1303. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Discussed in #944
Originally posted by segfault-magnet April 26, 2023
@hal3e and I have been discussing something, details to follow:
Currently, the Rust SDK cannot handle a nested heap type (e.g.
-> Option<Vec<u64>>) in the return type of a contract/script. The limitation stems from the fact that returning heap types only returns pointers which are useless without the VM's memory.A partial workaround was implemented where we would inject some extra bytecode after the contract call. The injected bytecode would generate a ReturnData receipt containing the previously inaccessible heap data. This allowed for returning a single non-nested heap type (e.g.
-> Vec<u64>). The injected bytecode is currently incapable of handling anything more complex.We suggest taking this to the extreme and supporting arbitrarily nested heap types.
There are three main problems we need to solve: structs, enums, and heap types nested in other heap types. Let's start with structs:
Structs
Let's consider the following example:
Encoded it looks something like this
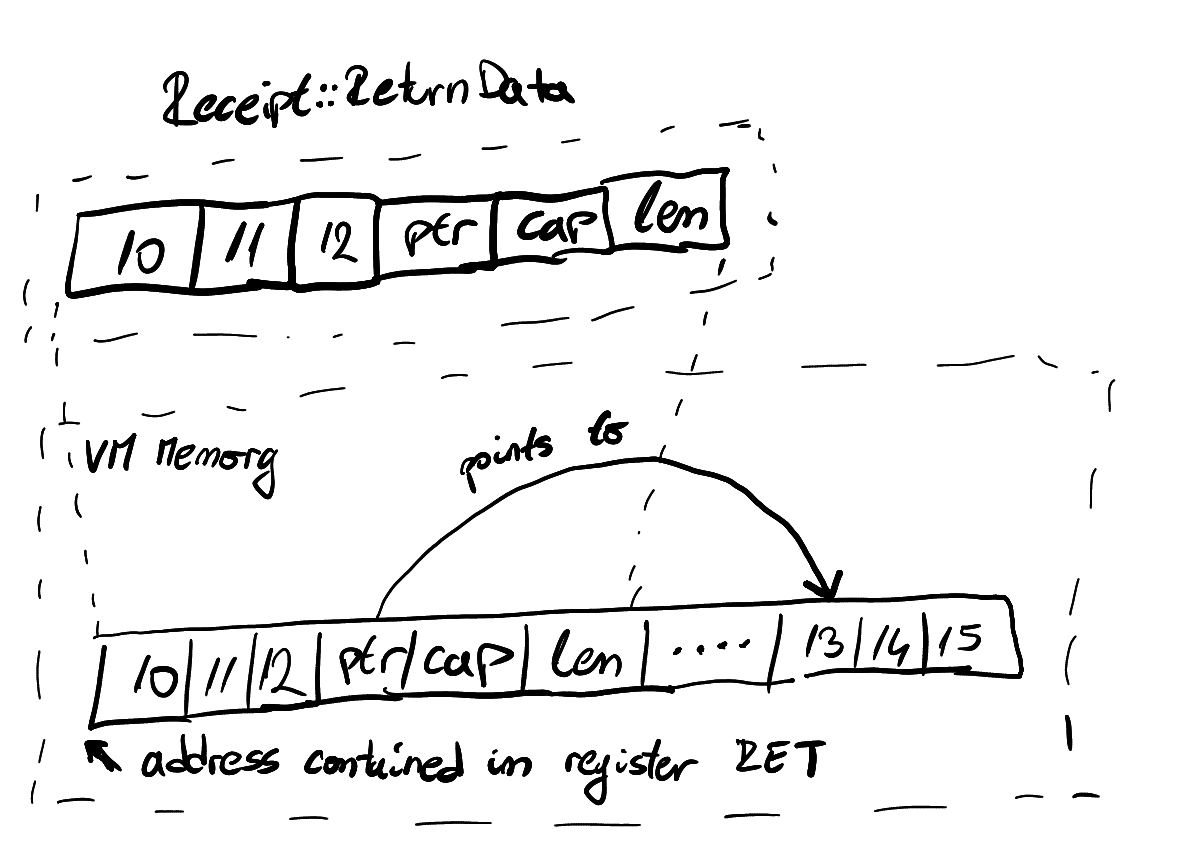
In order to support this we would need to inject a
retdinstruction that will yank the missing heap data into a separate receipt.The only difference between this and our current workaround is that the vector pointer isn't encoded immediately at the start. We would need to calculate this offset and add it to the address in the RET register in order to yank the heap data.
This can be done easily since we already know the exact size of every part of the struct.
In this case, it doesn't matter how deep the vector is inside nested structs, a single
retdwith a correct offset can get its data.Enums
Let's consider the following example:
With enums, we need to inject bytecode that will branch depending on the enum discriminant. Variants that don't contain heap types don't need to be considered, e.g. our example will only check if the enum carries the second variant.
After the variant is determined, the enum data can be used to generate the additional receipt data as before.
Heap types in other heap types
In order to get all the necessary data we'd need to issue 3
retdinstructions.Notice that this issue is recursive in nature. Once we issue the first and simplest
retdwe're right back to the same problem only now the starting address has been moved along.After collecting the receipts
Due to the structured and deterministic way we've approached walking the type tree (a post-order transversal) we can now use the extra receipts to decode the return type.
Since the abi encoder also does post-order transversing we can adapt it to accept a stack of receipts, popping one each time a heap type is to be decoded.
Or we can merge all the receipts into one, taking care to update the pointers to point to their respective data. Decoding would then be trivial as though we had the VMs memory loaded.
But that is an implementation detail, not that relevant right now. The point is, decoding is possible.
Other technical challenges also exist, such as registry management, but nothing unsolvable as far as we can see.
Considerations
The indexer
They will not be able to use this every time, just as they weren't able to use the current injection approach. If the contract wasn't called directly through the SDK then the bytecode was never injected and the additional receipts were never generated.
They could handle returning raw or typed slices but nested heap types would not be possible then.
Logging
Logging would not be supported since we cannot inject bytecode at the appropriate places. Logging heap types will only be possible through typed slices without the support of nested heap types.
Script support
We need to investigate the possibility of injecting the bytecode at the end of user-provided scripts. If it transpires that we'll always have a deterministic way of reaching the script return data, then the approach will be the same as for contracts.
The text was updated successfully, but these errors were encountered: