Include test function span information (file, module path, line number) in forc test output
#3266
Comments
OK, this should be good to go! ## Highlights - Adds support for multiple entry points to IR. Adds a tests for serializing entry functions to/from IR. - Enables ASM generation for libraries (to support test function entry points). - Track entry points through ASM generation so we can return entry point metadata as a part of the compilation result. This doesn't affect ASM generation, but allows tools using `sway-core` as a library to work with different entry points. - Updated E2E test harness with a new test category "UnitTestsPass". - Added E2E tests with multiple unit tests for each type of Sway program (library, script, predicate, contract). - Gets `forc test` working with pretty output! Here's the output from the new `lib_multi_test`: 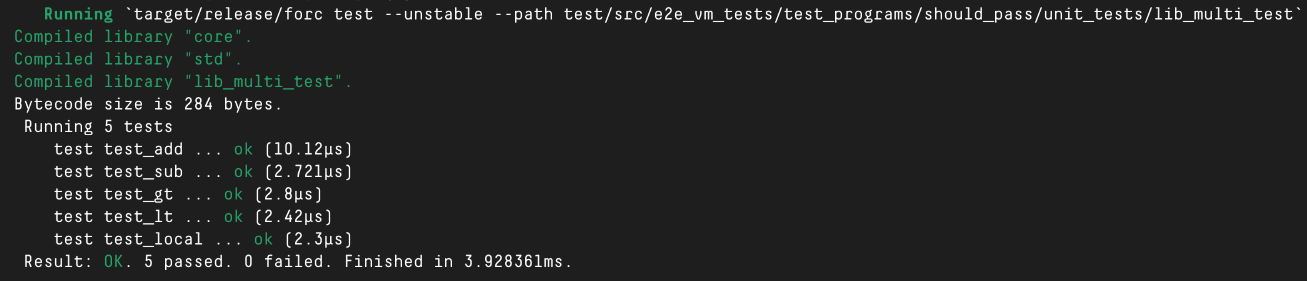 ## Test running implementation Currently, it seems like there's no publicly accessible approach to execute a script directly from a custom entry point. As a result, for each test, we patch the bytecode with a `JI` instruction that jumps from after the data section setup to the test's entry point. This is a bit hairy, but works for now! As a follow-up, we may want to consider adding support upstream in `fuel-vm` for executing scripts directly from a given entry point. Even if this was only exposed from the interpreter API, this would make the `forc-test` implementation quite a bit cleaner and avoid the need to patch the bytecode. Alternatively, when building projects we could return more metadata along with the compiled output (whether in memory or bytecode header) to indicate how to work with different entry points in a more reliable manner (rather than the magic const offset currently used in `forc-test`). # TODO - [x] Add `include_tests` flag to `BuildConfig`, allowing `forc` to trigger compilation of test functions. - [x] Include `#[test]` fns as entry points within dead code analysis. - [x] IR and ASM generation for test entry points. - [x] Add `forc build --tests`. - [x] Add `forc test`. - [x] Always include test fns in `TyProgram` (for DCA), but omit from IR if not building tests. - [x] Work out how to iterate over different entry points during `forc test`. - [x] Only generate tests for top-level "members" (not all dependencies). ### Follow-up: - #3260 - #3261 - #3262 - #3263 - #3264 - #3265 - #3266 - #3267 - #3268 Closes #1832.
{kind=link}
…their related function declaration (#3509) closes #3508. To continue with improving in-language testing (like the linked issues), we need to have a way of getting the original function declaration for the test that we are running from `forc-test`. Currently `forc-test` only works on `FinalizedEntry`s generated by the tests and we cannot get the function declaration from the entry point. Here I am introducing an optional field to the `FinalizedEntry` for tests. If the `FinalizedEntry` is generated from a test function, corresponding `FinalizedEntry`'s declaration id is populated and can be retrieved. To pass this declaration id information I needed to preserve it in the IR generation step to do that I added a metadata for it and populate it for the test function declarations. So for test function declarations we are inserting their declaration index to the metadata. I did not insert the `DeclarationId` since it does not implement `Hash`, and we are already inserting the span for the function declaration. Since `DeclarationId` is basically the index + span, storing only the index was enough. After the IR generation before creating an entry point I construct the `DeclarationId` from index and span (which comes from the metadata) and pass that to `FinalizedEntry`. This way in the IR generation step we are not losing the declaration index + span (and thus, the declaration id) and can retrieve the test function's declaration later on. unblocks #3490. unblocks #3266.
|
I think cargo only prints line number, file path and module path when a test is ignored (maybe also for failing ones too), I think that makes sense if a test is passing it results less noise in the terminal and only if something that may require your attention those details are printed. I am leaning towards doing the same thing. File path and line number should not be a problem but it is not really clear how can we get the module path. Do we even have modules? If a test named |
Yeah, I think we don't have that info yet, but it's coming as a part of @emilyaherbert 's work on the DE and CC. |
…their related function declaration (#3509) closes #3508. To continue with improving in-language testing (like the linked issues), we need to have a way of getting the original function declaration for the test that we are running from `forc-test`. Currently `forc-test` only works on `FinalizedEntry`s generated by the tests and we cannot get the function declaration from the entry point. Here I am introducing an optional field to the `FinalizedEntry` for tests. If the `FinalizedEntry` is generated from a test function, corresponding `FinalizedEntry`'s declaration id is populated and can be retrieved. To pass this declaration id information I needed to preserve it in the IR generation step to do that I added a metadata for it and populate it for the test function declarations. So for test function declarations we are inserting their declaration index to the metadata. I did not insert the `DeclarationId` since it does not implement `Hash`, and we are already inserting the span for the function declaration. Since `DeclarationId` is basically the index + span, storing only the index was enough. After the IR generation before creating an entry point I construct the `DeclarationId` from index and span (which comes from the metadata) and pass that to `FinalizedEntry`. This way in the IR generation step we are not losing the declaration index + span (and thus, the declaration id) and can retrieve the test function's declaration later on. unblocks #3490. unblocks #3266.
As of #2985, we only produce the function name for each test in our output, e.g.
We should be showing the full file path, module path and line number like cargo does.
This was omitted from #2985, only because it wasn't immediately obvious to me where to retrieve the span from during the ASM generation stage, and the PR is big enough 😅
The text was updated successfully, but these errors were encountered: