Brustkrebs ist eine der häufigsten Krebserkrankungen. Er macht 30 % aller Krebsfälle bei Frauen in Deutschland aus. In seltenen Fällen kann er auch Männer befallen (1 % aller Krebsfälle bei Männern).
Im Rahmen unseres Projektes analysieren wir einen Datensatz aus den USA der Informationen über demographische und medizinische Details von 1019 Brustkrebs Patienten aus den USA enthält. Die Daten werden zum beantworten unserer Forschungsfrage verwendet. In der Forschungsfrage gehen wir der Frage nach, ob Patienten, die an Brustkrebs erkrankt sind und vergleichbare Krankheitszustände vorweisen, auch die gleiche Behandlung bzw. Medikation erhalten.
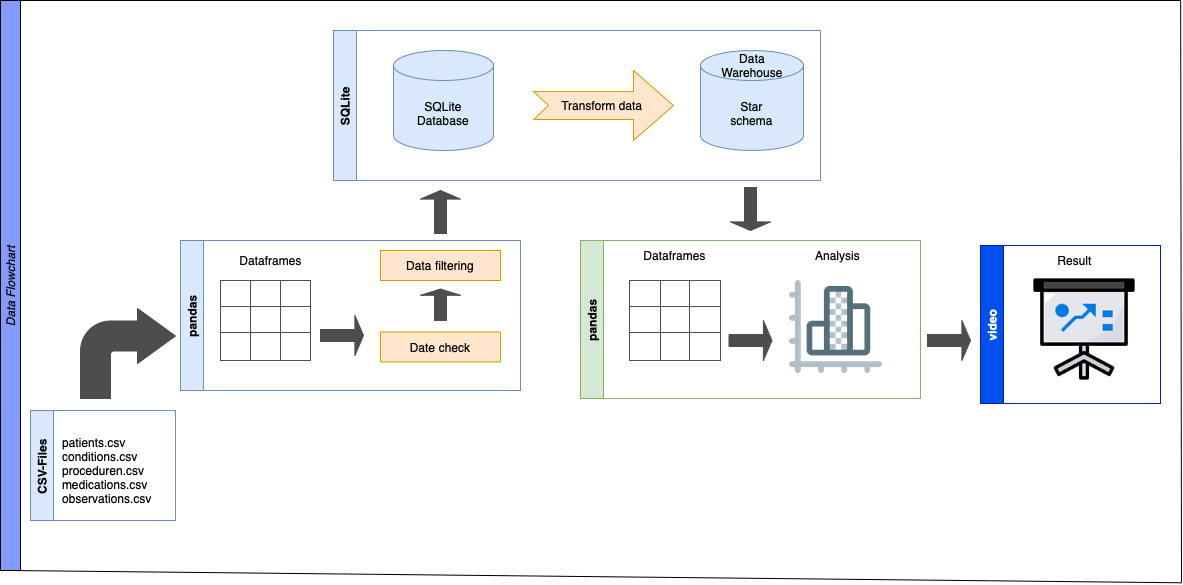
Eine genaue Anleitung zum klonen der Daten und des Codes und deren Ausführung auf lokalen oder cloud bassierten Systemen findet sich in Systemumgebung.
Der genaue Aufbau der verwendeten Daten kann hier Datenbanktabellen betrachtet werden. Die von uns generierten Daten werden auf Google Drive zur Verfügung gestellt. Die Daten sind anonymisiert und erlauben somit keinerlei Rückschlüsse auf die Identität der Patienten, sie dienen jedoch dazu die von uns verwendeten Methoden vefifizierbar zu machen. Für genauere Details über die Verfügbarmachung unserer Daten siehe Data Sharing
Bei der Bearbeitung der Daten wurde das Sternschema als Datenmodell genutzt. Dei bearbeiteten Daten wurden in SQL-Datenbanken geladen und auf Google Drive gespeichert. Zur Auswertung der Daten wurde das K-means-Verfahren genutzt. Ausführlichere Informationen finden sich in den Forschungsergebnissen und im Notebook Analysis.ipynb.
Die Forschungsfrage kann positiv beschieden werden. Nach Analyse der Medikamentengabe, wurde ersichtlich, dass Pateienten mit gleichem oder vergleichbarem Krankheitszustand tatsächlich die gleiche (bzw. relativ ähnliche) Medikation erhielten. Diese trifft zumindest auf Patienten mit Brustkrebserkrankungen zu.