![]()



Contents
Karpet is a tiny library with just a few dependencies for fetching coins/tokens metrics data from the internet.
It can provide following data:
- coin/token historical price data (no limits)
- google trends for the given list of keywords (longer period than official API)
- twitter scraping for the given keywords (no limits)
- much more info about crypto coins/tokens (no rate limits)
What is upcoming?
- Reddit metrics
- Have a request? Open an issue ;)
Library uses a few nifty dependencies and is Python 3.6+ only. There is no need to install dependencies you don't need. Therefore this library utilizes extras which install optional dependencies:
- for Google trends - google
- Install the library via pip.
pip install karpet # Basics only
pip install karpet[google] # For Google trends- Import the library class first.
from karpet import KarpetRetrieves historical data.
k = Karpet(date(2019, 1, 1), date(2019, 5, 1))
df = k.fetch_crypto_historical_data(symbol="ETH") # Dataframe with historical data.
df.head()
price market_cap total_volume
2019-01-01 131.458725 1.36773e+10 1.36773e+10
2019-01-02 138.144802 1.43923e+10 1.43923e+10
2019-01-03 152.860453 1.59222e+10 1.59222e+10
2019-01-04 146.730599 1.52777e+10 1.52777e+10
2019-01-05 153.056567 1.59408e+10 1.59408e+10Retrieves exchange list.
k = Karpet()
k.fetch_crypto_exchanges("nrg")
['DigiFinex', 'KuCoin', 'CryptoBridge', 'Bitbns', 'CoinExchange']Retrieves Google Trends - in percents for the given date range.
k = Karpet(date(2019, 1, 1), date(2019, 5, 1))
df = k.fetch_google_trends(kw_list=["bitcoin"]) # Dataframe with trends.
df.head()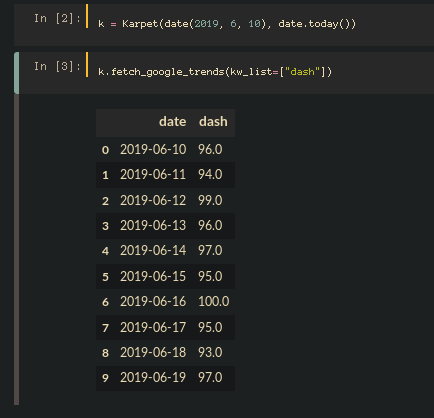
And with a few lines of code you can get a chart
df = df.set_index("date")
df.plot()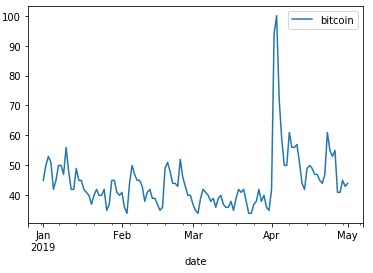
Retrieves crypto news.
k = Karpet()
news = k.fetch_news("btc") # Gets 10 news.
print(news[0])
{
'url': 'https://cointelegraph.com/ ....', # Truncated.
'title': 'Shell Invests in Blockchain-Based Energy Startup',
'description': 'The world’s fifth top oil and gas firm, Shell, has...', # Truncated.
'date': datetime.datetime(2019, 7, 28, 9, 24, tzinfo=datetime.timezone(datetime.timedelta(seconds=3600)))
'image': 'https://images.cointelegraph.com/....jpg' # Truncated.
}
news = k.fetch_news("btc", limit=30) # Gets 30 news.Retrieves top crypto news in 2 categories:
- Editor's choices - articles picked by editors
- Hot stories - articles with most views
k = Karpet()
editors_choices, top_stories = k.fetch_top_news()
print(len(editors_choices))
5
print(len(top_stories))
5
print(editors_choices[0])
{
'url': 'https://cointelegraph.com/...', # Truncated.
'title': 'Bank of China’s New Infographic Shows Why Bitcoin Price Is Going Up',
'date': datetime.datetime(2019, 7, 27, 10, 7, tzinfo=datetime.timezone(datetime.timedelta(seconds=3600))),
'image': 'https://images.cointelegraph.com/images/740_aHR...', # Truncated.
'description': 'The Chinese central bank released on its website an ...' # Truncated.
}
print(top_stories[0])
{
'url': 'https://cointelegraph.com/...', # Truncated.
'title': 'Bitcoin Price Shuns Volatility as Analysts Warn of Potential Drop to $7,000',
'date': datetime.datetime(2019, 7, 27, 10, 7, tzinfo=datetime.timezone(datetime.timedelta(seconds=3600))),
'image': 'https://images.cointelegraph.com/images/740_aHR0c...' # Truncated.
'description': 'Stability around $10,600 for Bitcoin price is ...' # Truncated.
}Resolves coin ID's based on the given symbol (there are coins out there with identical symbol).
Use this to get distinctive coin ID which can be used as id param for
method fetch_crypto_historical_data().
k = Karpet()
print(k.get_coin_ids("sta"))
['statera']Fetches coin/token basic data like:
open_issues is only provided if total_issues and closed_issues are
available.
k = Karpet()
print(k.get_basic_data(id="ethereum"))
{
'closed_issues': 5530,
'commit_count_4_weeks': 40,
'current_price': 3167.67,
'forks': 11635,
'market_cap': 371964284548,
'name': 'Ethereum',
'open_issues': 230,
'pull_request_contributors': 552,
'rank': 2,
'reddit_accounts_active_48h': 2881.0,
'reddit_average_comments_48h': 417.083,
'reddit_average_posts_48h': 417.083,
'reddit_subscribers': 1057875,
'stars': 31680,
'total_issues': 5760,
'year_high': 4182.790285752286,
'year_low': 321.0774351739628,
'yoy_change': 695.9225871929757 # growth/drop in percents
}- remove obsolete parts of the code and some dependencies
- fixed
get_basic_data()method (different data source) - new property in
get_basic_data()return dict -rank - tests enhanced
- fixed minor bugs
- new data in
get_basic_data()method -year_low,year_high,yoy_change
- new method
get_basic_data()
- removed twitter integration - twitterscraper library is not up to date
- fixed news fetching
- new method
get_coin_ids() - method
fetch_crypto_historical_data()hasidparam now
- migrated to coingecko.com API (no API key needed anymore)
- migrated to cryptocompare.com API (you need an API key now)
- requirements are now managed by Poetry
- added
fetch_top_news()method for top crypto news separated in 2 categories
fetch_news()adds new "description" item and renames "image_url" to "image"- all
fetch_news()item properties are now presented even if they areNone
- simplified import from
from karpet.karpet import Karpettofrom karpet import Karpet
- added
fetch_news()method for retrieving crypto news
- added
fetch_exchanges()method for retrieving symbol exchange list - removed obsolete library dependency
- twitter scraping added
- initial release
This is my personal library I use in my long-term project. I can pretty much guarantee it will live for a long time then. I will add new features over time and I more than welcome any help or bug reports. Feel free to open an issue or merge request.
The code is is licensed under MIT license.