This repository is the official implementation of Make-A-Protagonist.
Make-A-Protagonist: Generic Video Editing with An Ensemble of Experts
Yuyang Zhao, Enze Xie, Lanqing Hong, Zhenguo Li, Gim Hee Lee

The first framework for generic video editing with both visual and textual clues.
The text-driven image and video diffusion models have achieved unprecedented success in generating realistic and diverse content. Recently, the editing and variation of existing images and videos in diffusion-based generative models have garnered significant attention. However, previous works are limited to editing content with text or providing coarse personalization using a single visual clue, rendering them unsuitable for indescribable content that requires fine-grained and detailed control. In this regard, we propose a generic video editing framework called Make-A-Protagonist, which utilizes textual and visual clues to edit videos with the goal of empowering individuals to become the protagonists. Specifically, we leverage multiple experts to parse source video, target visual and textual clues, and propose a visual-textual-based video generation model that employs mask-guided denoising sampling to generate the desired output. Extensive results demonstrate the versatile and remarkable editing capabilities of Make-A-Protagonist.
- [16/05/2023] Code released!
- [26/05/2023] Hugging Face Demo released!
- [01/06/2023] Upload more video demos with 32 frames in this repo and Project Page! Happy Children's Day!
- [19/06/2023] ControlNet training code for Stable UnCLIP is released HERE!
- Release training code for ControlNet UnCLIP Small
- Release inference demo
- Python>=3.9 and Pytorch>=1.13.1
- xformers 0.0.17
- Other packages in
requirements.txt - Build GroundedSAM expert
cd experts/GroundedSAM
pip install -e GroundingDINO
pip install -e segment_anythingThe following weights from HuggingFace are used in this project. You can download them into checkpoints or load them from HuggingFace repo.
ControlNet for Stable Diffusion UnCLIP Small should be downloaded manually into checkpoints:
- ControlNet UnCLIP Small
- You can also train your own ControlNet model with Stable UnCLIP HERE.
Pre-trained model for other experts should be downloaded manually into checkpoints:
- GroundingDINO
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha2/groundingdino_swinb_cogcoor.pth - Segment Anything
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth - XMem
wget https://github.com/hkchengrex/XMem/releases/download/v1.0/XMem.pth
Captioning and VQA:
python experts/blip_inference.py -d data/<video_name>/imagesProtagonist Segmentation:
- Frame segmentation with GroundedSAM
python experts/grounded_sam_inference.py -d data/<video_name>/images/0000.jpg -t <protagonist>Note: Since GroundingDINO detects bounding boxes for each noun in the sentence, it is better to use only one noun here. For example, use -t man instead of -t "a man with a basketball".
- Video object segmentation through the video
python experts/xmem_inference.py -d data/<video_name>/images -v <video_name> --mask_dir <protagonist>.maskControl Signals Extraction:
python experts/controlnet_signal_extraction.py -d data/<video_name>/images -c <control>Currently we only support two types of control signals: depth and openposefull.
Reference Protagonist Segmentation:
python experts/grounded_sam_inference.py -d data/<video_name>/reference_images/<reference_image_name> -t <protagonist> --masked_outTo fine-tune the text-to-image diffusion models with visual and textual clues, run this command:
python train.py --config="configs/<video_name>/train.yaml"Note: At least 24 GB is requires to train the model.
Once the training is done, run inference:
python eval.py --config="configs/<video_name>/eval.yaml"Applications: Three applications are supported by Make-A-Protagonist, which can be achieved by modifying the inference configuration file.
- Protagonist Editing:
source_protagonist: true - Background Editing:
source_background: true - Text-to-Video Editing with Protagonist:
source_protagonist: false & source_background: false
| Input Video | Reference Image | Generated Video |
 |
 |
 |
| "A man walking down the street" | "A panda walking down the snowy street" | |
 |
 |
 |
| "A man playing basketball" | "A man playing basketball on the beach, anime style" | |
 |
 |
 |
| "A man walking down the street" | "Elon Musk walking down the street" | |
 |
 |
 |
| "A Suzuki Jimny driving down a mountain road" | "A Suzuki Jimny driving down a mountain road in the rain" | |
 |
 |
 |
| "A girl in white dress dancing on a bridge" | "A girl dancing on the beach, anime style" | |
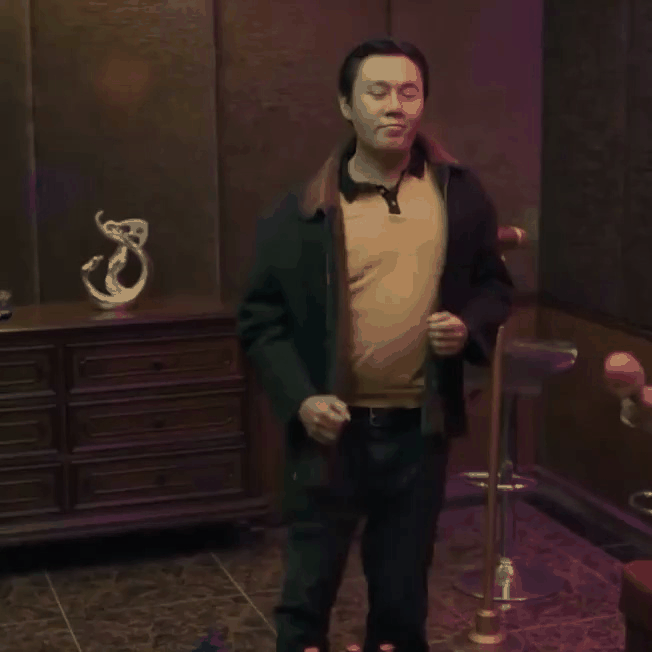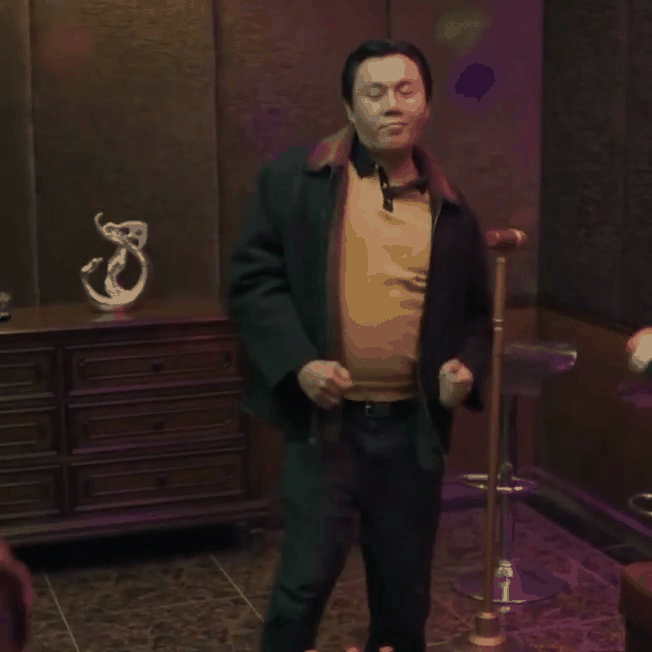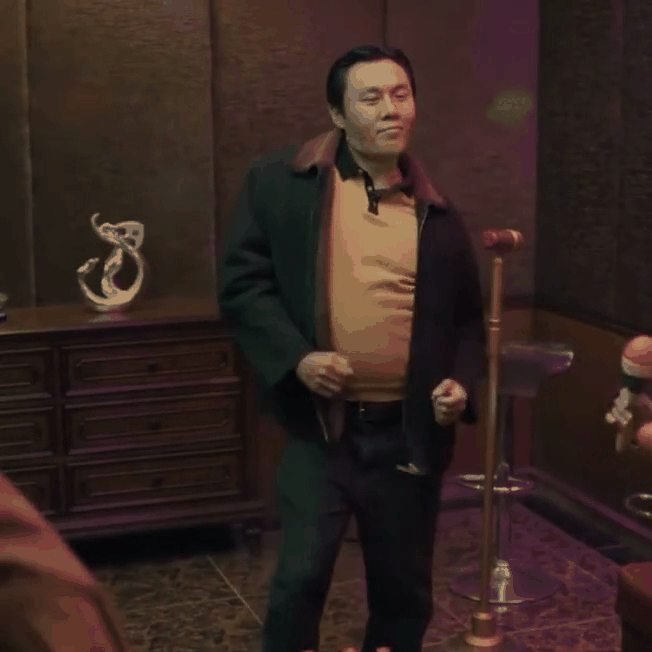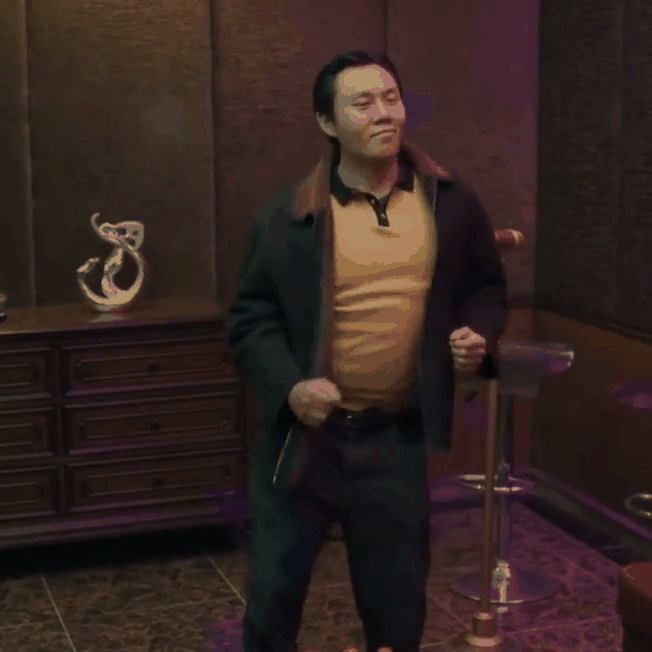 |
 |
 |
| "A man dancing in a room" | "A man in dark blue suit with white shirt dancing on the beach" |
If you make use of our work, please cite our paper.
@article{zhao2023makeaprotagonist,
title={Make-A-Protagonist: Generic Video Editing with An Ensemble of Experts},
author={Zhao, Yuyang and Xie, Enze and Hong, Lanqing and Li, Zhenguo and Lee, Gim Hee},
journal={arXiv preprint arXiv:2305.08850},
year={2023}
}- This code is heavily derived from diffusers and Tune-A-Video. If you use this code in your research, please also acknowledge their work.
- This project leverages Stable Diffusion UnCLIP, BLIP-2, CLIP, DALL-E 2 from Karlo, ControlNet, GroundingDINO, Segment Anything and XMem. We thank them for open-sourcing the code and pre-trained models.
- We thank AK and Hugging Face for providing computational resources on the demo
.