Vector Space Model
An algebraic model for representing text documents in a way where the objects retrieved are modeled as elements of a vector space.
N/A
Extraction > Categorize > Group
- Vectors representing the objects retrieved;
Vector Space Model is recommended when program elements (such as classes, methods, etc.) have meaningful names ("attribute" instead of "atr" or "home" instead of "hm"). Besides that, is highly recommended to use this technique in products well documented.
A Information Retrieval Technique cannot achieve quality results when applied to products with no documentation and no meaningful identifiers names. For that reason we don't recommend the use of Vector Space Model (VSM) or any other Information Retrieval Technique in those situations. Furthermore, the use of VSM has some limitations which may be considering when selecting this technique:
- Long documents are poorly represented because they have poor similarity values;
- Search keywords must precisely match document terms; word sub-strings might result in a "false positive match";
- Semantic sensitivity; documents with similar context but different term vocabulary won't be associated, resulting in a "false negative match";
- The order in which the terms appear in the document is lost in the vector space representation;
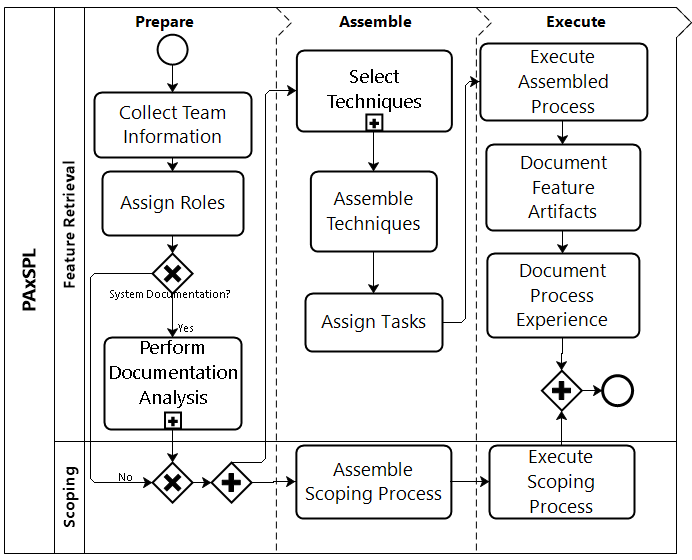
🔄 Prepare, Assemble and Execute Process for SPL (PAxSPL)

-
-
Static Analysis Techniques
-
Information Retrieval Techniques
-
Support Techniques
-
PAxSPL is a project developed within the Laboratory of Empirical Studies in Software Engineering