拉钩专栏 vip 账号爬取相关专栏
-
登陆拉钩教育
-
复制登陆成功后的 cookies
-
爬取:
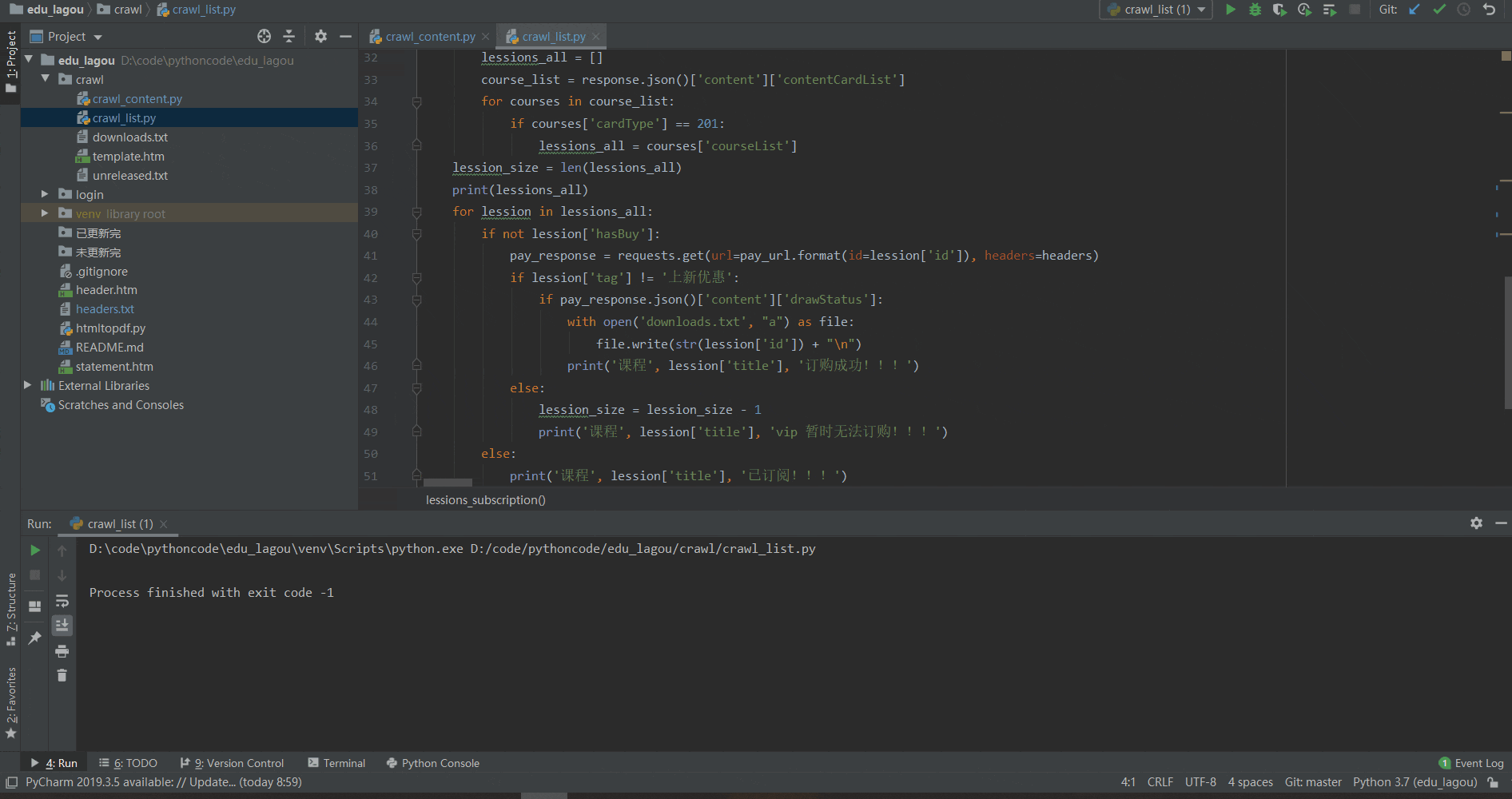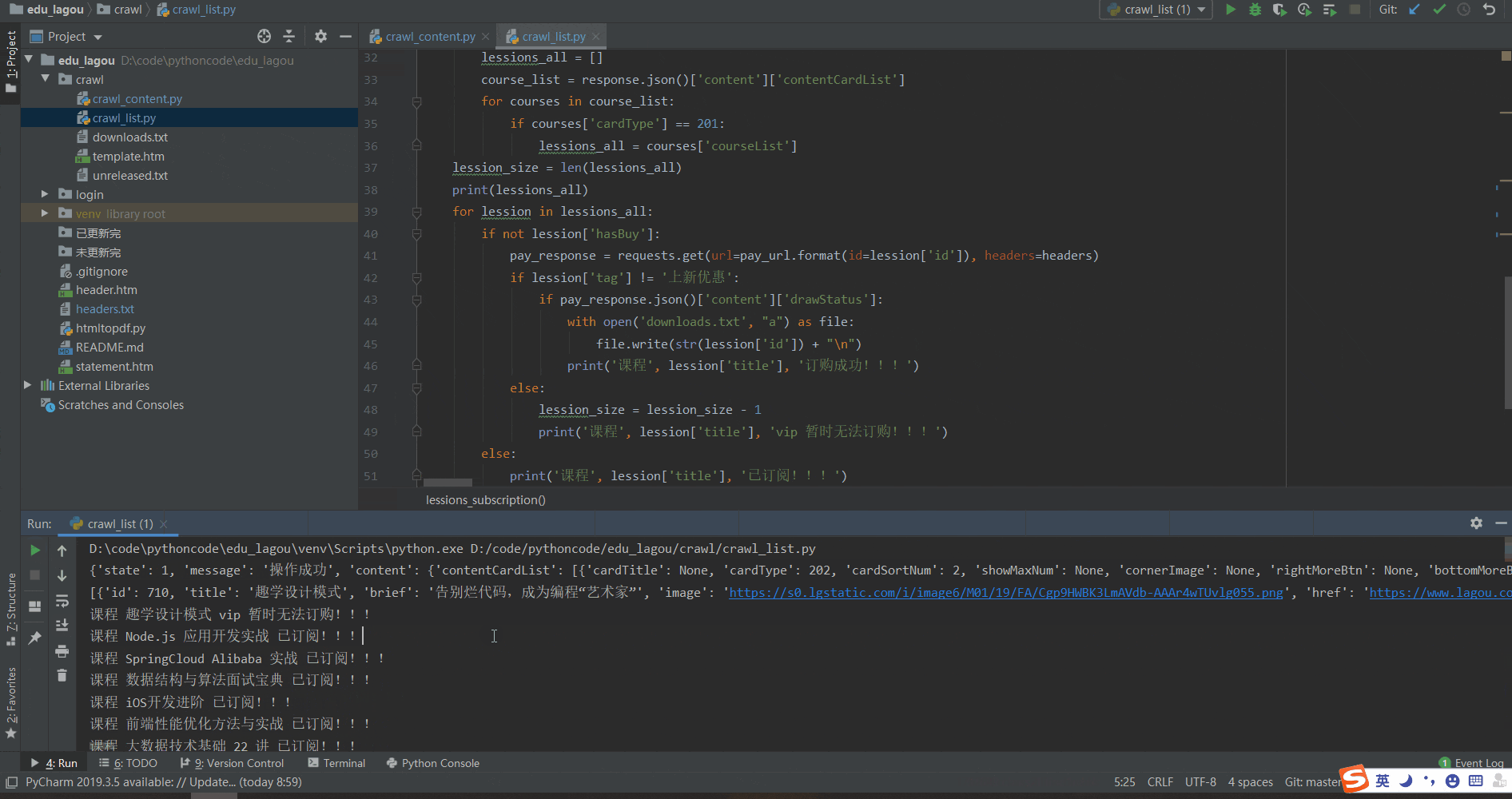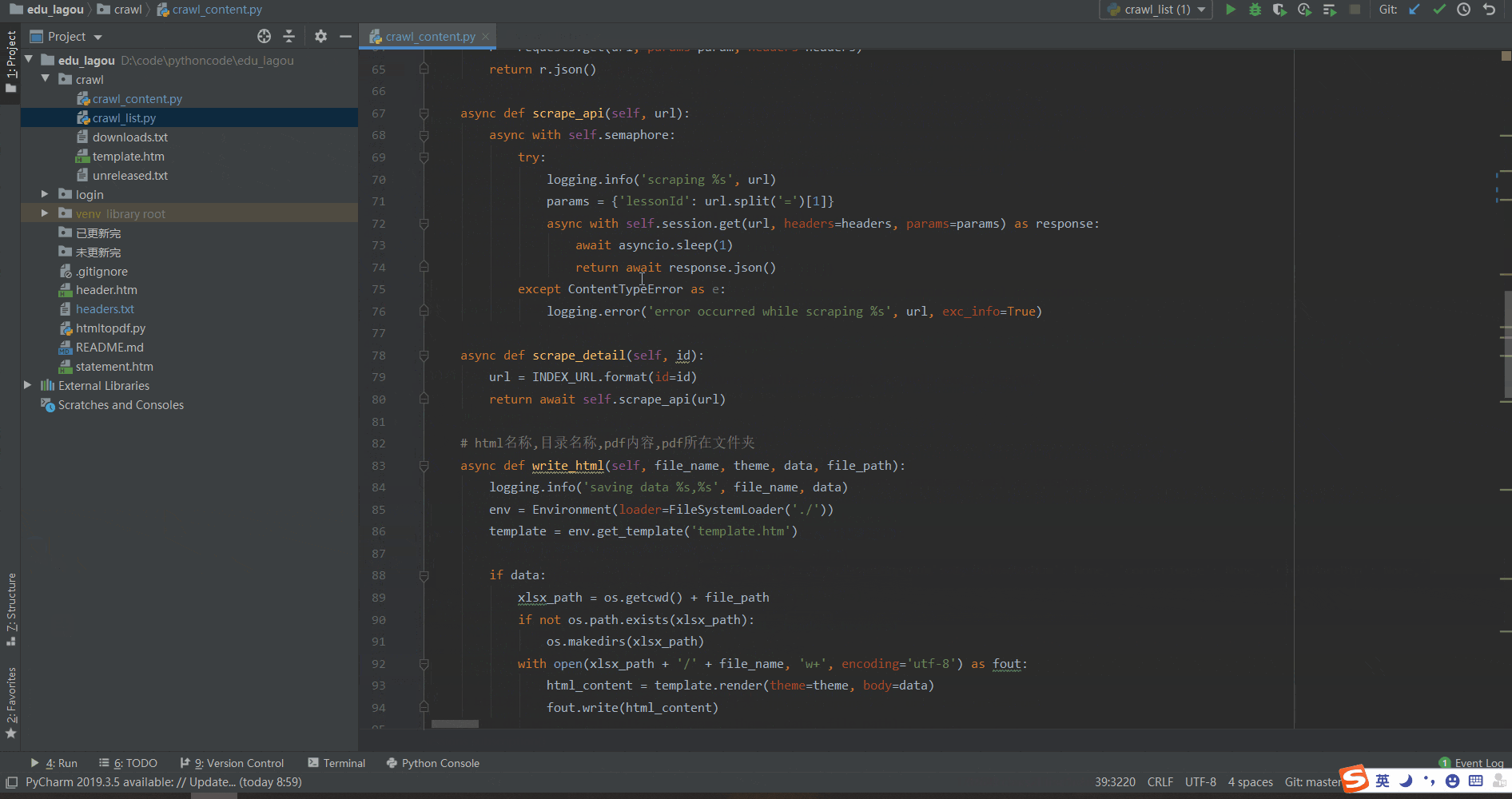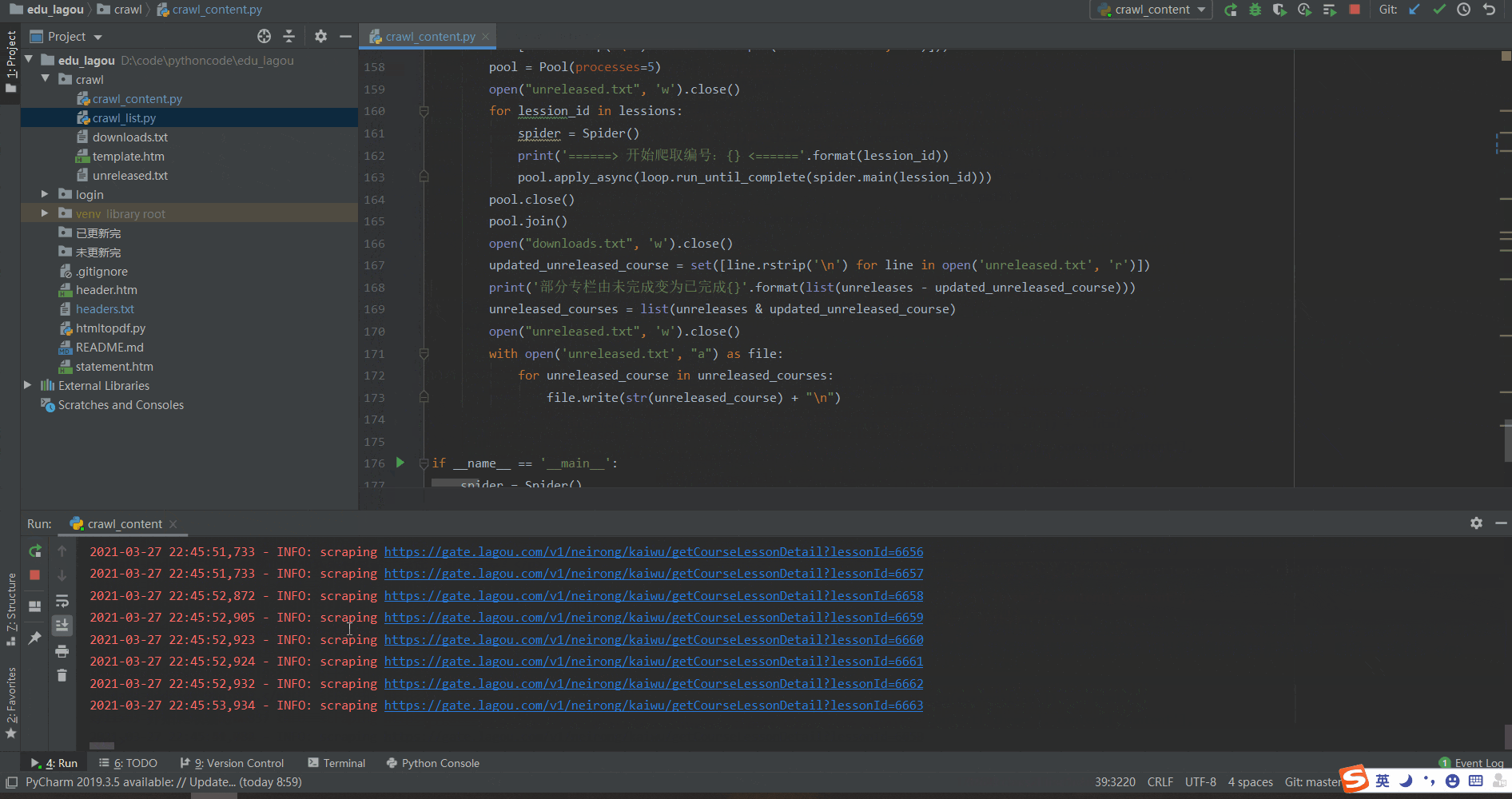
3.1 一键订阅:运行
crawl/crawl_list.py订阅并记录需要下载的专栏id到downloads.txt文件中 3.2 全量爬取:运行crawl/crawl_content.py中spider.crawl_all()方法 3.3 增量爬取:运行crawl/crawl_content.py中spider.cral_increase()方法
3.4 转换为 pdf:运行htmltopdf.py
- 第一次运行使用全量爬取,后续如果拉钩更新,项目会记录未下载和未更新完的专栏。
- 增量更新为未更新专栏的更新功能
- 目前需要手动在百度云网盘维护 pdf
- 增量更新时需要观看日志,并修改转换pdf文件夹,
pdf_paths = []根据日志中更新的id,通过查看https://kaiwu.lagou.com/course/courseInfo.htm?courseId=#{id}并修改更新id到需要更新的文件夹中
- 爬取拉勾课程
- 生成pdf
- 一键获取所有vip专栏订阅
- 一键下载所有专栏
- 多线程爬取专栏
- 全量爬取专栏
- 增量爬取专栏
- 更新未更新完得专栏并记录由未更新完变为更新完的专栏