如果您是机器学习的新手,您可能会对这两者感到困惑——Label 编码器和 One-Hot 编码器。这两个编码器是 Python 中 SciKit Learn 库的一部分,它们用于将分类数据或文本数据转换为数字,我们的预测模型可以更好地理解这些数字。今天,本文通过一个简单的例子来了解一下两者的区别。
首先,您可以在此处找到 Label Encoder 的 SciKit Learn 文档。现在,让我们考虑以下数据:
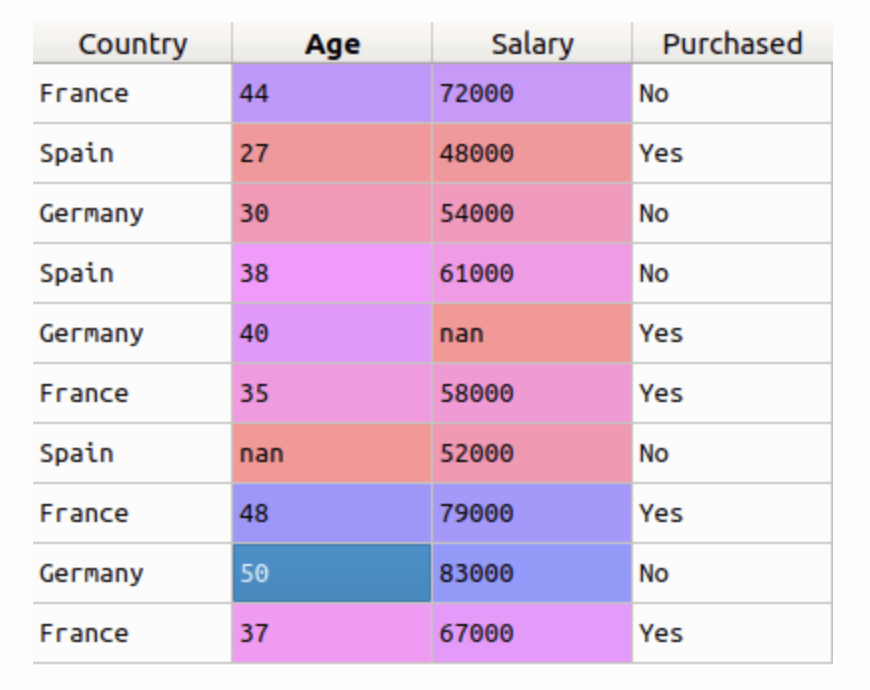
在本例中,第一列是国家列,全是文本。正如您现在可能知道的那样,如果我们要在数据上运行任何类型的模型,我们就不能在数据中包含文本。因此,在我们运行模型之前,我们需要为模型准备好这些数据。
为了将这种分类文本数据转换为模型可理解的数值数据,我们使用了标签编码器类。因此,要对第一列进行标签编码,我们所要做的就是从 sklearn 库中导入 LabelEncoder 类,拟合并转换数据的第一列,然后用新的编码数据替换现有的文本数据。让我们看一下代码。
from sklearn.preprocessing import LabelEncoder
labelencoder = LabelEncoder()
x[:, 0] = labelencoder.fit_transform(x[:, 0])我们假设数据在一个名为“x”的变量中。运行这段代码后,如果您检查 x 的值,您会看到第一列中的三个国家已被数字 0、1 和 2 替换。

这就是标签编码的全部内容。但是根据数据,标签编码引入了一个新问题。例如,我们将一组国家名称编码为数字数据。这实际上是分类数据,行之间没有任何关系。
这里的问题是,由于同一列中有不同的数字,模型会误解数据的某种顺序,0 < 1 < 2。但事实并非如此。为了克服这个问题,我们使用 One Hot Encoder。
现在,正如我们已经讨论过的,根据我们拥有的数据,我们可能会遇到这样的情况:在标签编码之后,我们可能会混淆我们的模型,认为列中的数据具有某种顺序或层次结构,而实际上我们显然不这样做没有它。为避免这种情况,我们对该列进行“OneHotEncode”。
One Hot Encoder 的作用是,它需要一个具有分类数据的列,该列已经过标签编码,然后将该列拆分为多个列。这些数字将替换为 1 和 0,具体取决于哪一列具有什么值。在我们的示例中,我们将获得三个新列,每个国家一列 - 法国、德国和西班牙。
对于第一列值为法国的行,“法国”列将为“1”,其他两列将为“0”。同样,对于第一列值为 Germany 的行,“Germany”列的值为“1”,其他两列的值为“0”。
One Hot Encoder 的 Python 代码也非常简单:
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder(categorical_features = [0])
x = onehotencoder.fit_transform(x).toarray()正如您在构造函数中看到的,我们指定哪一列必须进行 One Hot Encoder,在本例中为 [0]。然后我们用我们刚刚创建的 one hot encoder 对象拟合和转换数组“x”。就是这样,我们的数据集中现在有了三个新列:

如您所见,我们有三个新列,分别为 1 和 0,具体取决于行代表的国家/地区。
这就是 Label Encoding 和 One Hot Encoding 之间的区别。