在本文中,您将了解 F1 分数。 F1 分数是一种机器学习指标,可用于分类模型。尽管分类模型存在许多指标,但通过本文,您将了解 F1 分数的计算方式以及何时使用它有附加价值。
f1 分数是对两个更简单的性能指标的改进建议。因此,在深入了解 F1 分数的细节之前,让我们概述一下 F1 分数背后的那些指标。
准确性是分类模型的一个指标,它衡量正确预测的数量占所做预测总数的百分比。例如,如果你的预测有 90% 是正确的,那么你的准确率就是 90%。
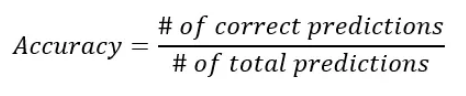
仅当您的分类中的类别分布均等时,准确性才是有用的指标。这意味着,如果您有一个用例,在该用例中观察到一个类的数据点多于另一个类的数据点,则准确性不再是有用的指标。让我们看一个例子来说明这一点:
假设您正在处理网站的销售数据。您知道 99% 的网站访问者不购买,只有 1% 的访问者购买。您正在构建一个分类模型来预测哪些网站访问者是买家,哪些只是浏览者。
现在想象一个效果不佳的模型。它预测 100% 的访问者只是观看者,而 0% 的访问者是购买者。这显然是一个非常错误和无用的模型。
当你有类不平衡时,准确性不是一个好的指标。
如果我们在这个模型上使用精度公式会发生什么?您的模型仅预测了 1% 错误:所有买家都被错误分类为看客。因此,正确预测的百分比为 99%。这里的问题是 99% 的准确率听起来不错,而你的模型表现很差。总之:当你有类别不平衡时,准确性不是一个好的衡量标准。
- 通过重采样解决不平衡数据
解决类别不平衡问题的一种方法是处理您的样本。使用特定的采样方法,您可以以数据不再不平衡的方式对数据集进行重新采样。然后您可以再次使用准确性作为指标。
- 通过指标解决不平衡数据
解决类不平衡问题的另一种方法是使用更好的准确性指标,如 F1 分数,它不仅考虑了模型预测错误的数量,还考虑了所犯错误的类型。
Precision 和 Recall 是考虑到类不平衡的两个最常见的指标。它们也是F1成绩的基础!在将它们组合到下一部分的 F1 分数之前,让我们更好地了解 Precision 和 Recall。
精度是 F1 分数的第一部分。它也可以用作单独的机器学习指标。它的公式如下所示:

您可以按如下方式解释此公式。在预测为正的所有内容中,精度计算正确的百分比:
- 一个不精确的模型可能会发现很多阳性,但它的选择方法是有噪音的:它也会错误地检测到许多实际上不是阳性的阳性。
- 一个精确的模型是非常“纯粹”的:也许它没有找到所有的积极因素,但模型分类为积极的那些很可能是正确的。
召回率是 F1 分数的第二个组成部分,尽管召回率也可以用作单独的机器学习指标。召回公式如下所示:
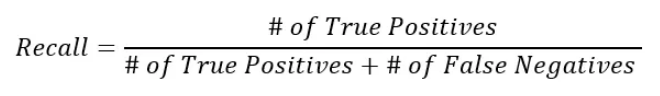
您可以按如下方式解释此公式。在所有实际积极的事物中,模型成功找到了多少:
- 具有高召回率的模型可以很好地找到数据中的所有正例,即使它们也可能错误地将一些负例识别为正例。
- 召回率低的模型无法找到数据中的所有(或大部分)阳性病例。