转置卷积操作的详细分解
转置卷积是用于生成图像的,尽管它们已经存在了一段时间,并且得到了很好的解释——我仍然很难理解它们究竟是如何完成工作的。我分享的文章描述了一个简单的实验来说明这个过程。我还介绍了一些有助于提高网络性能的技巧。
本文主要内容:
- 反卷积操作的整体可视化
- 通过分离更重要的组件来优化网络
- 解决合成数据集问题
插图的任务是我能想到的最简单的任务:为合成数据构建一个自动编码器。它是合成的这一事实可能会引发一些问题。的确,在此类数据上训练的模型在真实数据上可能表现不佳。但是我们稍后会看到为什么会这样以及如何解决它。该模型由一个用于编码器的卷积层和一个用于解码器的反卷积(也称为卷积转置)组成。
数据是一组一维贝塞尔曲线,如下所示:
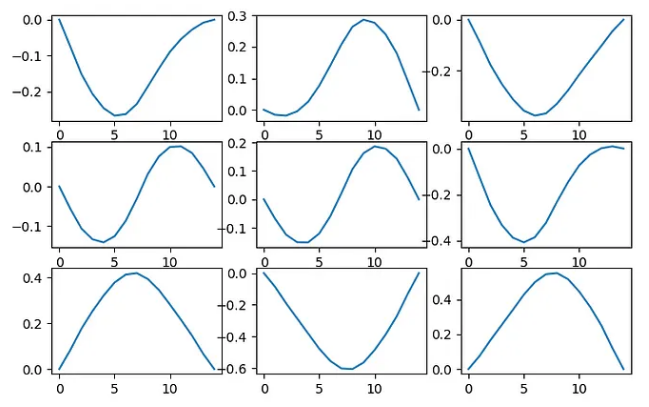
- 这是生成数据的代码:
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
DATASIZE = 1024 * 16
WINSIZE = 15
np.random.seed(22)
# A Wikipedia page on Bezier curves contains a thorough explanation on
# the topic, as well as mathematical formulas.
# A 3-rd order curve is used here, so it is built on 4 points
def get_curve_points(param1, param2, n):
# The four characteristic points depend on two parameters
p1 = {'x': 0, 'y': 0}
p2 = {'x': 0.5, 'y': param1}
p4 = {'x': 1, 'y': 0}
p3 = {'x': 0.5, 'y': param2}
xs = np.zeros(n)
ys = np.zeros(n)
# Calculating the curve points by the formula from Wikipedia
for i, t in enumerate(np.linspace(0, 1, n)):
xs[i] = (1-t)**3 * p1['x'] + 3*(1-t)**2*t * p2['x']\
+ 3*(1-t)*t**2 * p3['x'] + t**3 * p4['x']
ys[i] = (1-t)**3 * p1['y'] + 3*(1-t)**2*t * p2['y']\
+ 3*(1-t)*t**2 * p3['y'] + t**3 * p4['y']
xs = np.array(xs)
ys = np.array(ys)
return xs, ys
def generate_input(p1, p2):
xs, ys = get_curve_points(p1, p2, WINSIZE * 10)
# The function above generates the curve as a set
# of X and Y coordinates. The code below resamples them
# into a set of Y coordinates only.
# The function above does generate 10 times more points
# than we would need, to make it dense enough for the resampling.
result = []
for x in np.linspace(0, 1, WINSIZE):
result.append(ys[np.argmin((xs - x)**2)])
return np.array(result)
if __name__ == '__main__':
data = []
for i in tqdm(range(DATASIZE)):
# Generate two random parameters for each data item
p1 = np.random.uniform() * 2 - 1
p2 = np.random.uniform() * 2 - 1
ys = generate_input(p1, p2)
data.append(ys)
# Plot the first 9 samples in 3x3 window
if i < 3*3:
plt.subplot(3, 3, i+1)
plt.plot(ys)
plt.gcf().set_size_inches(8, 5)
plt.show()
data = np.array(data)
np.save('data.npy', data)这些曲线每条包含 15 个点。每条曲线将作为一维数组馈入网络(而不是为每个点传递 [x, y] 坐标,仅传递 [y])。
每条曲线都可以用两个参数来表征,这意味着我们的网络应该能够将任何曲线编码/解码为大小为 2 的向量。
这是一个可用于对曲线进行编码的示例网络:
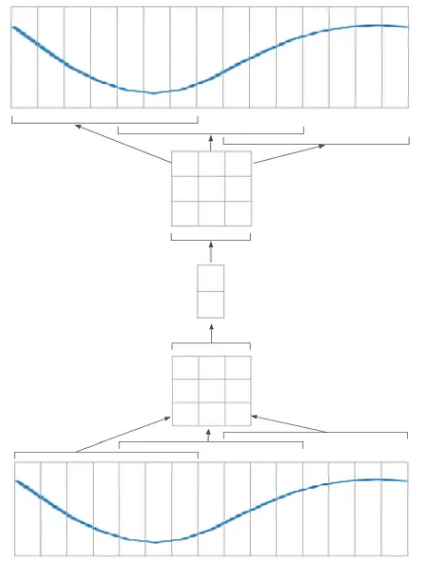
在上图中,输入信号(底部)被分成 3 个大小为 7 的块(通过应用窗口大小为 7 和步幅为 4 的卷积层)。每个补丁被编码成一个大小为 3 的向量,给出一个 3x3 矩阵。然后将该矩阵编码为大小为 2 的向量;然后在解码器中反向重复该操作。
网络可能被分成两部分。第一个将能够编码/解码曲线的一部分(7 像素补丁);而第二个只会处理 3x3 矩阵。这样,我就可以分别训练每个部分。我可以制作一个仅适用于 7 像素补丁的更小的自动编码器:
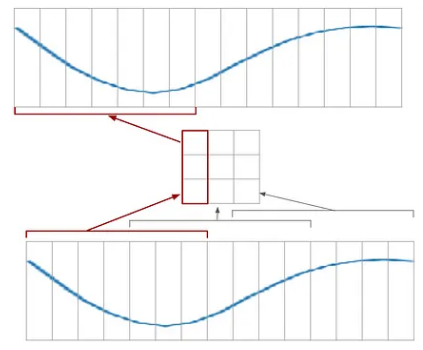
所以我要将每个示例拆分成补丁,并训练网络对补丁进行编码/解码。然后,我将组装这个网络来生成整个曲线。
我不会进一步编码这个 3x3 矩阵,因为这个过程不会携带任何新信息。
我将为编码器和解码器使用不同的模型。它们非常简单:
# The content of this file is later referenced as 'models.py'
# it will be imported by 'from models import *'
import torch
class Encoder(torch.nn.Module):
def __init__(self, ch, win):
super(Encoder, self).__init__()
self.conv = torch.nn.Conv1d(1, ch, win, 4)
def forward(self, x):
x = self.conv(x)
return torch.tanh(x)
class Decoder(torch.nn.Module):
def __init__(self, ch, win):
super(Decoder, self).__init__()
self.deconv = torch.nn.ConvTranspose1d(ch, 1, win, 4)
def forward(self, x):
x = self.deconv(x)
return x步幅为 4,因为正如“方法”部分中的图像所指,过滤器一次移动 4 个像素。由于我们在这里只实施一个阶段,因此这一步完全是可选的;它只会在我们组装更大的网络时产生影响。
首先,我将设置一组不同种子的训练。训练代码尽可能简单:
import os
import torch
import numpy as np
from models import *
from torch.utils.data import TensorDataset, DataLoader
N_CHANNELS = 3
WINSIZE = 7
N_EPOCHS = 5000
device = torch.device('cuda:0')
inputs = np.load('data.npy')
# Cut the 15px curves into 7px items, at random point
inputs_cut = []
np.random.seed(22)
start_idxs = np.random.randint(0, inputs.shape[1] - WINSIZE, inputs.shape[0])
for i in range(len(start_idxs)):
item_upd = inputs[i, start_idxs[i]:start_idxs[i] + WINSIZE]
inputs_cut.append(item_upd)
inputs = torch.tensor(inputs_cut).float().unsqueeze(1).to(device)
dataset = TensorDataset(inputs)
def train_model(seed):
torch.manual_seed(seed)
# Create the dataloader after the random seed was set,
# because its 'shuffle' depends on the seed
dataloader = DataLoader(dataset, batch_size=128, shuffle=True)
enc = Encoder(N_CHANNELS, WINSIZE).to(device)
dec = Decoder(N_CHANNELS, WINSIZE).to(device)
opt = torch.optim.Adam(list(enc.parameters()) + list(dec.parameters()), lr=1e-4)
mse = torch.nn.MSELoss()
for epoch in range(N_EPOCHS):
train_loss = 0
for item, in dataloader:
opt.zero_grad()
code = enc(item)
out = dec(code)
loss = mse(out, item)
loss.backward()
opt.step()
train_loss += loss.item()
if epoch % 10 == 0:
print(epoch, train_loss / len(dataloader))
os.makedirs('models', exist_ok=True)
torch.save(enc.state_dict(), open('models/encoder_{}.pt'.format(seed), 'wb'))
torch.save(dec.state_dict(), open('models/decoder_{}.pt'.format(seed), 'wb'))
for seed in [11, 22, 33, 44, 55]:
train_model(seed)以下是这些实验的损失表现:

该图显示了使用不同种子进行的 10 次实验的损失均值和标准差。
如果我现在将标签与网络输出进行视觉比较,它看起来如下所示:
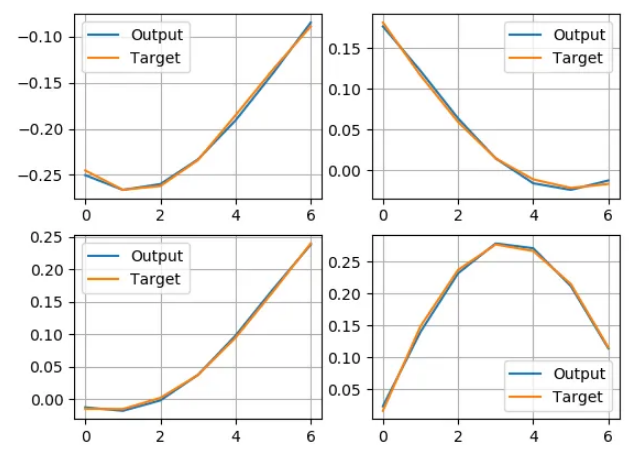
这看起来还不错,看起来网络在工作,1e-4 下的损失值就足够了。
接下来,我将说明编码器和解码器在这个例子中是如何工作的。
解码器旨在将代码(3 维向量)转换为曲线补丁。作为反卷积操作,它有一组过滤器,每个过滤器按某个值缩放,然后相加;换句话说,滤波器的加权和应该与所需的输出相匹配。
下图包含两个恢复曲线的示例。左边的例子是从向量 [0.0, 0.1, 0.2] 解码而来的,右边的例子是 [0.1, 0.1, 0.0]。每个示例在顶部包含缩放的过滤器,在底部包含不缩放的过滤器。

果然,我们可以一次改变一个矢量分量并实时渲染网络输出,形成一个看起来很酷的动画。所以这里是:

上面的每个动画都包含多个情节。左下角的点显示输入向量。它的 X 和 Y 坐标和大小代表输入的第一、第二和第三分量。右下角的图显示了原始过滤器,并且所有动画都保持不变。右上图显示缩放过滤器和输出。由于只有一个参数在变化,因此只有一个滤波器被缩放并且输出与该滤波器匹配。
左上图可能是最有趣的,因为它旨在显示输出如何同时依赖于两个组件。它上面的每条曲线代表第三个组件的不同值的输出。人们可能会看到,在第三个动画中,图形没有移动,只是不同的曲线变粗了。在前两个动画中,只有中间曲线保持粗体,因为第三个分量保持为零,但总的来说,它给出了如果第三个分量发生变化时输出会是什么的想法。
这是所有组件同时变化的情况:

这个例子中的编码器看起来有点不直观,但无论如何它以某种方式完成了工作。 (其质量将在以下部分进行审查)

左侧显示了原始过滤器以及示例输入。右图显示了应用于示例输入的这些相同过滤器(即输入的每个点乘以过滤器的每个点)。标签还包含每个过滤器的输出(即过滤器 1 的每个点乘以输入的每个点的总和得到 0.02)。
上图中的示例将被编码为一个向量 (0.02, 0.08, -0.08)。解码器将以如下所示的方式恢复输入:

左边的图显示了解卷积滤波器。右边的那个——每个滤波器乘以其代码向量值及其总和(这也是解码器的输出)。
该解决方案似乎有效——网络将其 7 值输入编码为 3 值代码;然后以低错误将其解码回来。但我看到了两种改进的可能性:
-
当使用不同的种子训练网络时,过滤器会有很大差异。这意味着网络具有太多的灵活性,我们可以对其进行约束。
-
编码器鲁棒性。我们如何确保编码器适用于各种真实数据?
为了说明第一种情况,我将简单地绘制通过使用不同种子训练获得的过滤器:
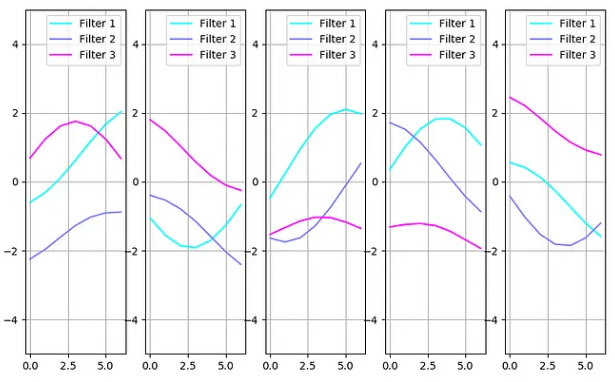
显然,我们需要考虑过滤器的符号和顺序:第一个图像上的过滤器 3 和第二个图像上的过滤器 1 是相同的。具有符号和顺序补偿的过滤器集如下所示:

这里的过滤器显然有很大差异。
不同的过滤器集给出相同结果的事实表明过滤器可能受到约束。限制过滤器的一种方法是确定它们的优先级。与 PCA 技术类似,将编码大部分信息的过滤器与编码少量细节的过滤器分开。这可以通过向编码图像添加噪声来实现:

在上图中,左边的图像展示了一个传统的自动编码器:输入被编码到一个二维平面上;然后解码回来。网络解码中间图像中 2D 平面稍微偏移的点。这迫使网络将相似的图像编码为在平面上保持接近的点。右图显示了解码点在 Y 轴上比在 X 轴上漂移更远的情况。这迫使网络将最重要的特征编码到 X 组件中,因为它的噪声较小。
这是在代码中实现的相同概念:
for epoch in range(N_EPOCHS):
train_loss = 0
for item, in dataloader:
opt.zero_grad()
code = enc(item)
# Generate noise to be added to the code
coderand = torch.randn(code.shape).to(device)
# Vary the noise magnitude for different channels
coderand[:, 0 :] *= 0.1
coderand[:, 1 :] *= 0.01
coderand[:, 2 :] *= 0.001
# Apply the noise
out = dec(code + coderand)
loss = mse(out, item)
loss.backward()
opt.step()再次运行实验后,我会收到一组更一致的过滤器:

如果我像以前一样补偿签名和订单,在“有什么问题”部分:

可以清楚地看到一侧弯曲而另一侧尖锐的过滤器,并且一个组件在中间弯曲。过滤器 2 和 3 似乎同等重要,因为它们有时在第一个组件中编码,有时在第二个组件中编码。然而,第三个滤波器的幅度较小,并且总是编码在最嘈杂的分量中,这表明它不太重要。
可以通过比较模型的性能同时将编码向量的不同分量归零来检查这种噪声的影响:

上图显示了通过将第一、第二或第三分量归零后的损失变化,左侧为噪声模型,右侧为原始模型。对于原始模型,禁用每个组件会导致相对相同的损耗下降。
这是视觉上的比较。在下图中找到模型输入和输出。从左到右:完整模型;禁用过滤器 1 的模型;禁用过滤器 2 的模型;禁用过滤器 3 的模型。
用噪声训练的模型:

对于原始模型:

当仅禁用噪声组件时,使用噪声训练的模型的误差明显较小。
现在让我们再看一下编码器过滤器。它们一点也不光滑,有些看起来很相似。这很奇怪,因为编码器的目的是发现输入中的差异,而您无法使用一组相似的过滤器来发现差异。网络如何做到这一点?好吧,答案是我们的合成数据集太完美了,无法训练正确的过滤器。网络可以很容易地通过一个点对输入进行分类:

在上面的每个图上,较大的图上都有一个曲线示例(称为“原始”),以及 3 个与该原始示例具有相似点的示例。示例本身是不同的,但给出该点的精确值(即 -0.247 或 -0.243),网络能够对整个示例做出决定。
这可以通过向原始输入添加噪声来轻松解决。
for epoch in range(N_EPOCHS):
train_loss = 0
for item, in dataloader:
opt.zero_grad()
# Generate the noise to be added to the input
itemrand = torch.randn(item.shape).to(device)
itemrand *= 0.01
# Apply the input noise
code = enc(item + itemrand)
# Generate noise to be added to the code
coderand = torch.randn(code.shape).to(device)
# Vary the noise magnitude for different channels
coderand[:, 0 :] *= 0.1
coderand[:, 1 :] *= 0.01
coderand[:, 2 :] *= 0.001
# Apply the noise
out = dec(code + coderand)
loss = mse(out, item)
loss.backward()
opt.step()再次训练模型后,我获得了很好的平滑过滤器:

人们可能会看到噪声最大的过滤器 1 比其他过滤器变得更大。我的猜测是,它试图使其输出大于噪音,试图降低其影响。但是由于我有一个 tanh 激活,它的输出不能大于 1,所以噪声仍然有效。
现在我们有了模型的工作组件,我们可以多次应用它,这样它就可以对整个 15 点曲线进行编码/解码。这没什么特别的,我需要做的就是不要把我的例子切成碎片:
import numpy as np
import torch
from torch.utils.data import TensorDataset, DataLoader
import matplotlib.pyplot as plt
from models import *
WINSIZE = 7
N_CHANNELS = 3
device = torch.device('cuda')
enc = Encoder(N_CHANNELS, WINSIZE).to(device)
dec = Decoder(N_CHANNELS, WINSIZE).to(device)
def eval_model(seed):
enc.load_state_dict(torch.load(open('models/encoder_{}.pt'.format(seed), 'rb')))
dec.load_state_dict(torch.load(open('models/decoder_{}.pt'.format(seed), 'rb')))
mse = torch.nn.MSELoss()
eval_loss = 0
cnt = 0
for item, in dataloader:
cnt += 1
# Plot first two examples in a 2x2 grid
if cnt <= 4:
code = enc(item)
out = dec(code)
loss = mse(out, item)
eval_loss += loss.item()
plt.subplot(2, 2, cnt)
plt.plot(out[0, 0].cpu().detach().numpy(), label="Output")
plt.plot(item[0, 0].cpu().detach().numpy(), label="Target")
plt.legend()
plt.grid()
print(eval_loss / len(dataloader))
plt.show()
inputs = np.load('data.npy')
inputs = torch.tensor(inputs).float().unsqueeze(1).to(device)
dataset = TensorDataset(inputs)
dataloader = DataLoader(dataset, batch_size=128, shuffle=False)
eval_model(22)
view raw这将给我以下输出:
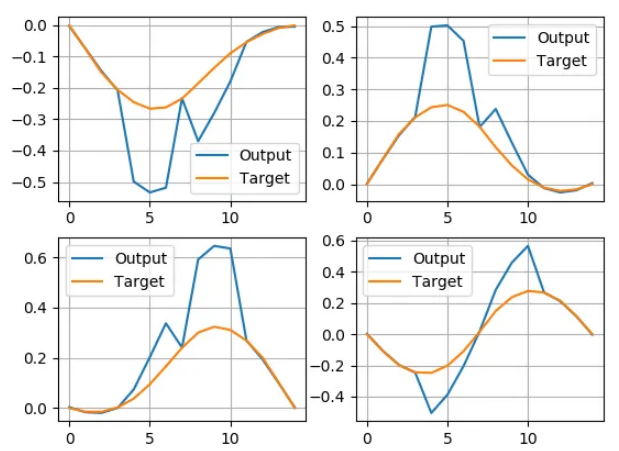
好吧,也许我需要改变一些东西。问题是,反卷积将总结图像的重叠部分。所以下面图中的这些部分加倍了:
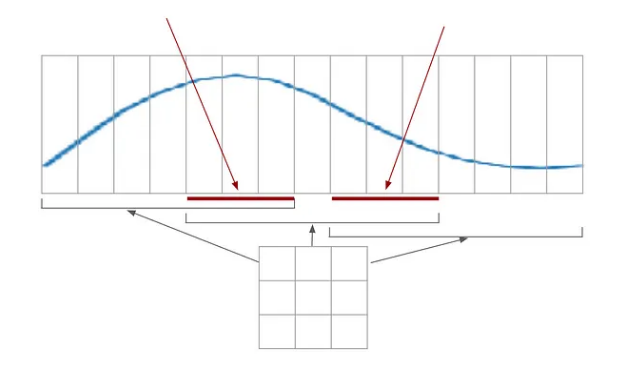
有一个简单的解决方法:我可以将输出重叠的过滤器的权重减少一半:
def eval_model(seed):
enc.load_state_dict(torch.load(open('models/encoder_{}.pt'.format(seed), 'rb')))
dec.load_state_dict(torch.load(open('models/decoder_{}.pt'.format(seed), 'rb')))
# With the deconvolution stride 4 and
# window size 7, which is our case, the
# only weight that does not overlap is
# the middle one, indexed as 4.
# All the other weights are reduced by a half.
dec.deconv.weight.data[:, :, 0] *= 0.5
dec.deconv.weight.data[:, :, -1] *= 0.5
dec.deconv.weight.data[:, :, 1] *= 0.5
dec.deconv.weight.data[:, :, -2] *= 0.5
dec.deconv.weight.data[:, :, 2] *= 0.5
dec.deconv.weight.data[:, :, -3] *= 0.5
...进行此操作后,我将得到以下输出:

这导致了另一个问题——边界点没有任何重叠,解码后的图像与应有的不同。对此有几种可能的解决方案。例如,在编码图像中包含填充,以便边界也被编码,或者忽略这些边界(也可能将它们排除在损失计算之外)。我将在这里停止,因为进一步的改进超出了本文的范围。
这个简单的例子说明了反卷积是如何工作的,以及如何使用噪声(有时大小不同)来训练神经网络。
所描述的方法确实适用于较大的网络,并且噪声幅度成为试验的超参数。该方法可能不适用于 ReLu 激活:它们的输出可能很容易变得比噪声幅度大得多,并且噪声会失去作用。